Video Graph Transformer for Video Question AnsweringLarge Language Models
读论文时间!
视频问答(VideoQA)模型:Video Graph Transformer,VGT
官方代码: https://github.com/sail-sg/VGT
介绍
当前视频问答遇到的问题:
- 视频编码器过于简单。目前的视频编码器要么是稀疏帧上操作的2D神经网络(CNN 或 Transformer ),要么是在短视频段上操作的3D神经网络。这些网络对视频进行整体编码,但不能明确建模精细的细节,即视觉对象之间的时空交互。
- 通常,在多选问答中,视频、问题以及每个候选答案都被追加到一个整体标记序列中,然后馈送给跨模态Transformer,以获得用于分类答案的全局表示。这种全局表示对于消除候选答案的歧义很弱,因为视频可能会压倒短答案并支配总体表示。
- 在开放式问答(通常作为多类分类问题进行建模)中,答案被视为类别索引,而其词义(有助于问答)被忽略。对信息的不充分建模加剧了数据饥饿问题,并导致性能较差。
本文提出了一种针对视频问答(VideoQA)问题的视频图注意力模型(Video Graph Transformer,VGT)。VGT 的独特之处在于:
- 它设计了一个动态图注意力模块,该模块通过显式捕获视觉对象、它们的关系以及动态关系来编码视频,从而实现复杂的时空推理。
- 利用独立的视觉和文本 Transformer 分别对视频和文本进行编码,而不是使用单个跨模态 Transformer 来融合视觉和文本信息以分类答案。视觉文本通信是通过额外的跨模态交互模块实现的。
亮点:
- 在无预训练的情况下,由于更合理的视频编码和问答解决方案,VGT 在具有挑战性的动态关系推理的视频问答任务上比之前的方法表现得更好。其性能甚至超过了使用数百万外部数据进行预训练的模型。
- VGT 还可以从自监督跨模态预训练中受益匪浅,但使用的数据量要小得多。
- 在少量数据上预训练 VGT 时,我们可以观察到进一步且非同寻常的性能提升。
相关工作
在 Transformer 在视觉语言任务上取得成功之前,已经提出了各种技术来建模信息丰富的视频内容以回答问题,例如跨模态注意力、运动外观记忆、图神经网络。然而,它们大多利用帧或片段级别的视频表示作为信息源,少了动态。
最近,基于对象级表示构建的图已经被证明具有优越的性能,特别是在强调视觉关系推理的基准测试中。然而,这些方法没有兼顾空间和时间、局部和全局、静态和动态。
统一图对于长视频来说很繁琐,因为多个对象在时空交互。此外,静态图可能会导致错误的关系(例如拥抱与战斗)或无法捕捉动态关系(例如拿走)。
ClipBERT利用图像描述数据进行预训练,但仅在时间推理任务上能够取得有限的性能提升,因为静态图像很难学习时序关系。
最近的一些工作收集了百万级别的用户生成(Web 上大量存在)视觉文本数据进行预训练,但在针对如此大规模的数据集进行训练时会遇到巨大的计算成本问题。
总的来说,现有基于 Transformer 模型的视频语言模型中动态推理能力差和数据饥饿的问题在促使我们开展这项工作。
图神经网络与 Transformer 之间的联系正受到越来越多的关注。最近的一项工作将图和 Transformer 结合用于视频对话。然而,它只对来自静态帧的池化图表示应用全局Transformer ,少了动态。我们的工作设计并学习动态视觉图。
模型
定义
给定一个视频v和一个问题q,VideoQA旨在将两个流的信息v和q结合起来来预测答案a。A表示问题的答案候选项,任务可以表示为:
\[a^*=\mathop{\arg \max}_{a\in\mathcal{A}} \mathcal{F}_W(a|q,v,\mathcal{A})\]其中,$\mathcal{F}_W$ 表示具有可学习参数 W 的映射函数。我们设计了VGT模型来执行映射$\mathcal{F}_W$
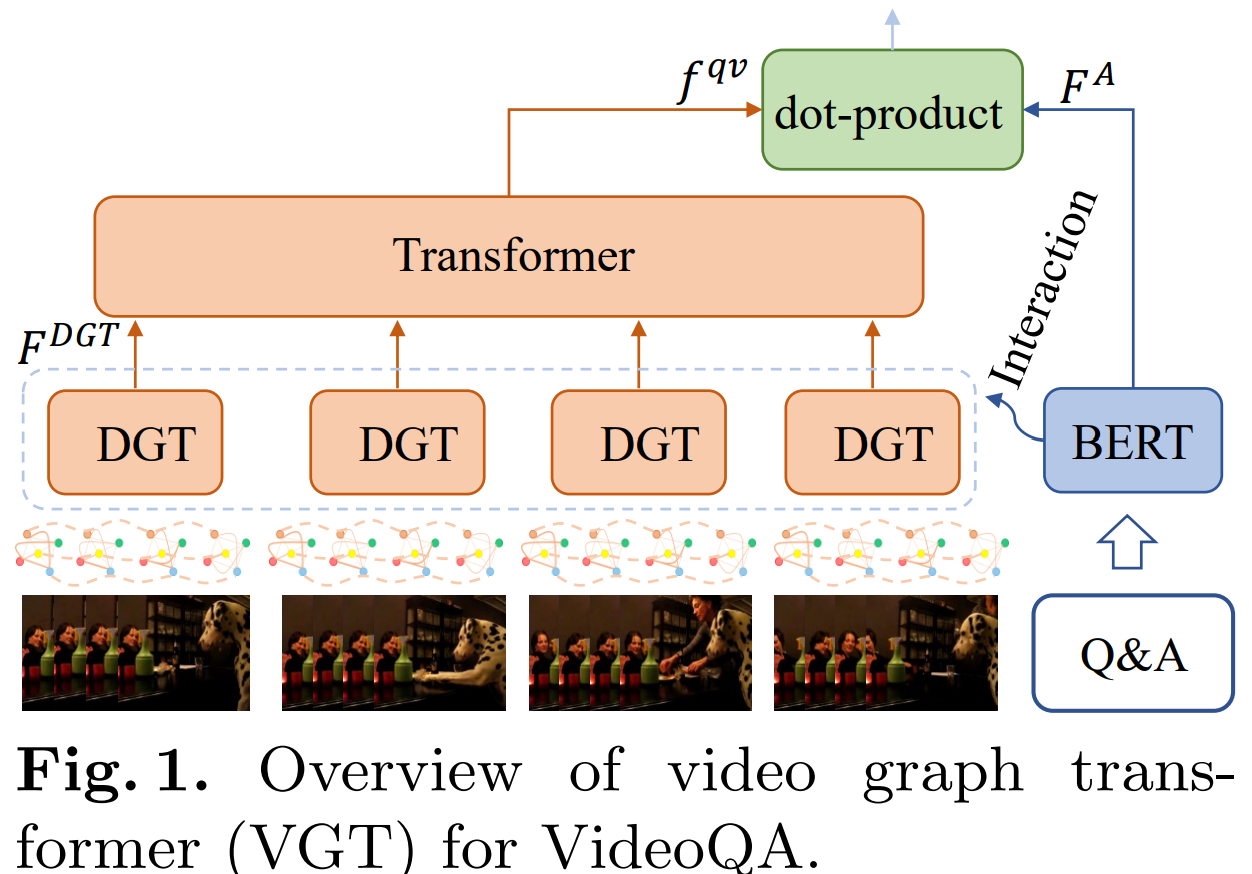
- 在视觉部分,VGT 以视觉对象图作为输入,通过 DGT(dynamic graph transformer)模块得到特征表示 $F^{DGT}$
- $F^{DGT}$ 通过全局 transformer 得到全局特征 $f^{qv}$,以表示与查询相关的视频内容。
- 在文本部分,VGT 使用语言模型(BERT)为所有候选答案提取特征表示 $F^A$
- 通过$f^{qv}$和$F^A$的点乘,找到相关分数最大的候选答案,得到最终答案 $a^*$
视频在图神经网络中的表示
给定一个视频,我们稀疏采样 lv 帧。 将这些帧等分为 k 段,每段长度为 lc = lv / k。
对于每个采样帧(如下图),我们使用预训练好的对象检测器提取 n 个 RoI 对齐特征作为对象外观表示 $F_r={f_{r_i}}^n_{i=1}$ ,以及它们的空间位置 $B={b_{r_i}}^n_{i=1}$ ,其中 $r_i$ 表示图像中第 i 个对象区域。
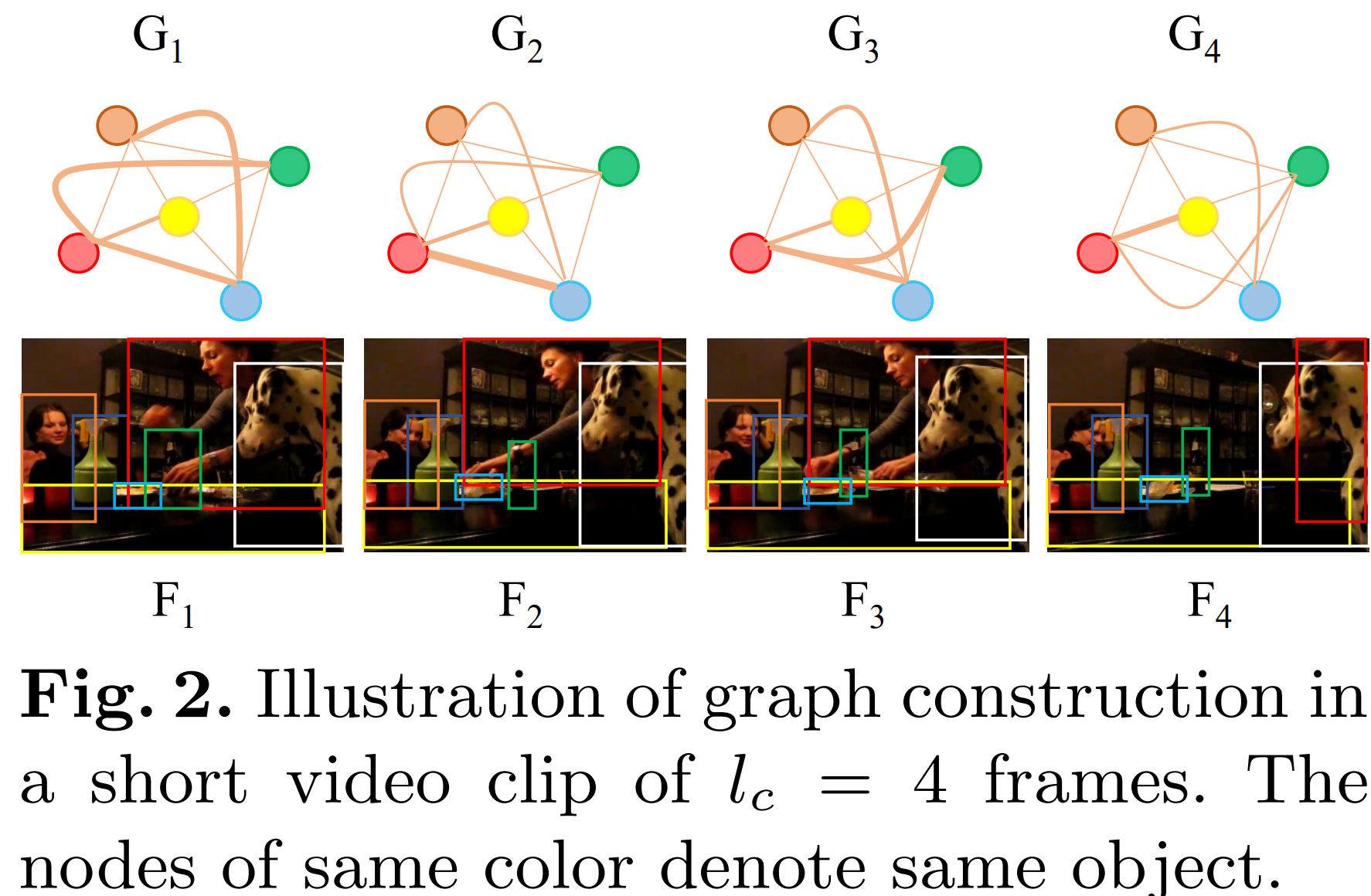
此外,我们使用预训练的图像分类模型为所有采样帧生成全局上下文特征图 $F_I={f_{I_t}}^{l_v}_{t=1}$。全局上下文用于增强从本地对象聚合而来的图表示。
为了在视频片段中不同的帧内找到相同的对象,我们通过考虑它们的外观和空间位置来定义一个连接分数s:
\[s_{i,j}=ψ(f^t_{r_i},f^{t+1}_{r_j})+\lambda * \text{IoU}(b^t_{i},b^{t+1}_{j}) , t\in\{1,2,...,l_c-1\}\]- 其中,ψ表示相邻帧中检测到的对象 i 和 j 之间的余弦相似度。
- IoU计算对象 i 和 j 的位置重叠。
- 在我们的实验中,我们总是将λ设置为1。
每个片段的第一帧中的检测到的对象被指定为锚定对象。 对于接下来的连续帧中的检测到的对象,通过贪婪地最大化每一帧来与锚定对象相关联。 通过在片段内对齐对象,我们可以确保在不同帧上构建的图的节点和边表示的一致性。这里假设在一个很短的视频片段中,物体不会新增或消失。
接下来,我们拼接物体外观特征 fr 和位置特征 floc ,再投影,ELU是一种激活函数:
\[f_o=\text{ELU}(\phi_{W_o}([f_r;f_{loc}]))\]- 其中, [; ] 表示特征连接
- floc 是通过应用一个 1×1 卷积核到相对坐标上获得的
- 函数 $\phi_{W_o}$ 代表具有参数 Wo 的线性变换
有了 $ F_o = {f_{o_i}}^n_{i=1}$,第 t 个帧中可以初始化为对偶相似度:
\[R_t=\sigma(\phi_{W_{ak}}(F_{o_t})\phi_{W_{av}}(F_{o_t})^T), t\in\{1,2,...,l_v\}\]- 其中,函数 $\phi_{W}$ 代表具有参数 W 的线性变换,下面公式都是不再赘述
我们使用不同的转换来反映现实世界主体-客体交互的不对称性质。对于对称关系,我们期望学习到的参数Wak和Wav非常相似。σ是Softmax操作,它对每一行进行归一化。
为了简洁起见,我们用 $G_t = (F_{o_t}, R_t)$ 表示第t帧的图表示,其中Fo是节点表示,而R是图的边表示。
DGT
dynamic graph transformer (DGT) 以一组视觉图 ${G_t}^{L_v}_{t=1}$ 为输入,对每个剪辑进行处理,并通过挖掘对象的时间动力学及其空间交互,来输出一个表示序列 $F^{DGT} ∈ R^{d×k}$。为此,我们按顺序操作时间图变换器单元、空间图卷积单元和分层聚合单元,具体如下:
Temporal Graph Transformer
如图,Temporal Graph Transformer 采用 node transformer (NTrans) 和 edge transformer (ETrans) 来挖掘输入的一组图 Gin 中的数据,并输出一组新的图 Gout。
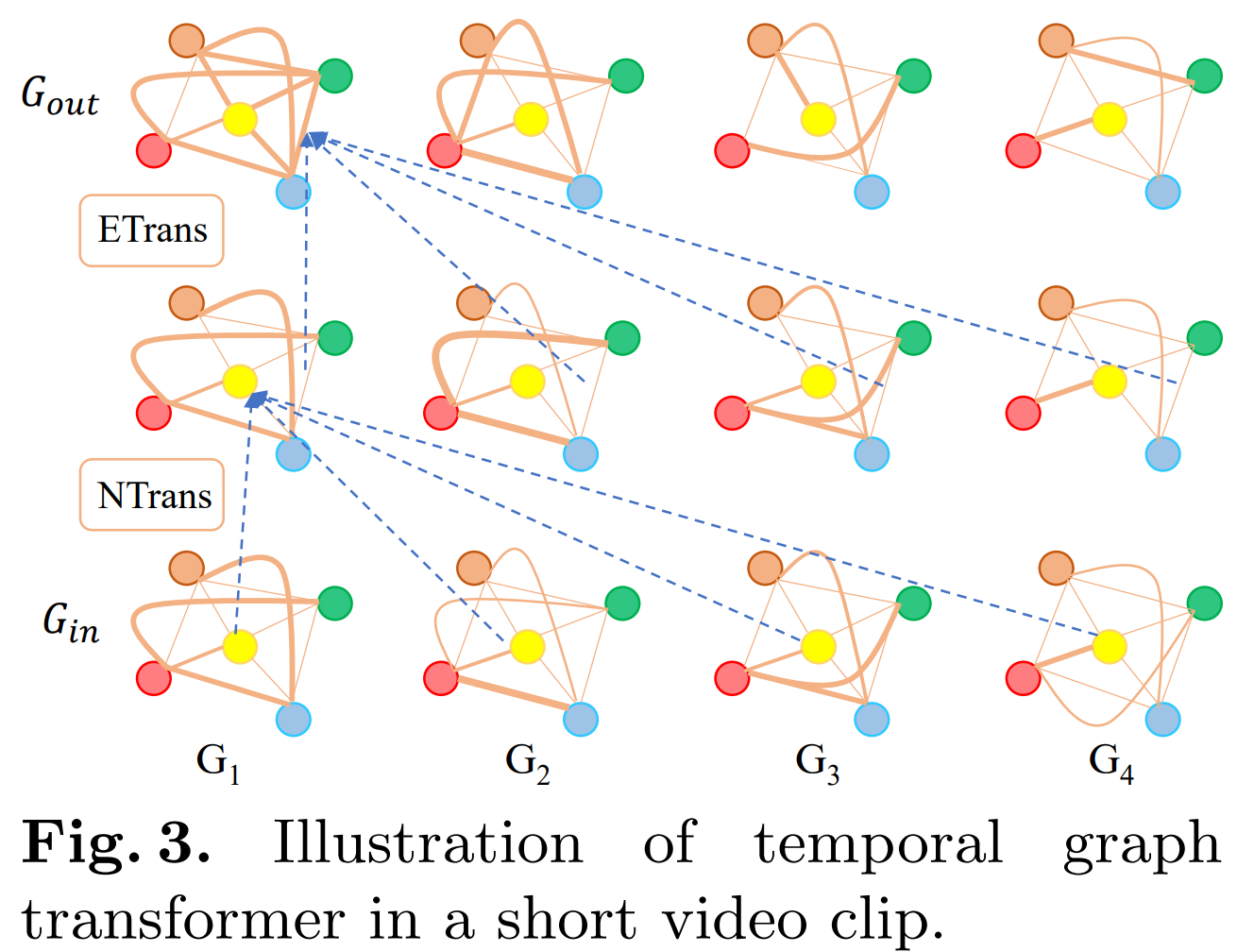
首先,使用多头自注意力(MHSA)来融合输入特征 $X_{in} = {x^t_{in}}^l_{t=1}$
\[X_{out}=\text{MHSA}(X_{in})=\phi_{W_c}([h_1;h_2;...h_e])\] \[h_i=SA(\phi_{W_{i_q}}(X_{in}),\phi_{W_{i_k}}(X_{in}),\phi_{W_{i_v}}(X_{in}))\] \[SA(X_q,X_k,X_v)=\sigma(X_kX_q^T/\sqrt{d_k})X_v\]再加上残差连接和层归一化 (LN),X 可以根据Transformer层数经历更多 MHSAs:
\[X=LN(X_{out}+X_{in})\]在Temporal Graph Transformer中,我们应用了H个自注意力块来通过聚合来自同一对象的所有相邻帧内的其他节点的信息来增强节点(或对象)表示,其中$F’_{o_i} \in \mathbb{R}^{l_c \times d}$,表示长度为lc的视频剪辑中对象i的特征表示:
\[F'_{o_i}=\text{NTrans}(F_{o_i})=\text{MHSA}^{(H)}(F_{o_i})\]我们使用 node transformer 的动机是因为它建模了单个对象的行为变化,从而推断动态动作(例如弯曲)。在某些帧中物体发生运动模糊或部分遮挡的情况下,它还可以帮助提高对象的外观特征提取。
然后更新相似度,即图的边表示,或者说关系矩阵:
\[R_t=\sigma(\phi_{W_{ak}}(F_{o_t})\phi_{W_{av}}(F_{o_t})^T), t\in\{1,2,...,l_v\}\]在更新的关系矩阵上应用 edge transformer,其中 $\mathcal{R} = {R_t}^l_{t=1} \in \mathbb{R} ^{l_c\times d_n},d_n=n^2$
\[\mathcal{R}'=\text{ETrans}(\mathcal{R})=\text{MHSA}^{(H)}(\mathcal{R})\]我们的动机是,捕获静态帧的联系可能是虚假的、微不足道的或不完整的。edge transformer 可以帮助调整错误的关系并召回丢失的关系。
我们称在第 t 个帧中具有时间上下文信息的图为 $G_{out_t}=(F_{o_t}’,R_t’)$。
Spatial Graph Convolution
Temporal Graph Transformer 专注于对时空关系进行推理。为了推断物体之间的空间交互,我们在所有 lv 图上应用了一个 U 层图注意力卷积。
\[F_o^{'(u)}=\text{ReLU}((R'+I)F_o^{'(u-1)}W^{(u)})\]为了简洁起见,省略了索引 t,$F_o^{‘(u)}$ 由输出节点表示 $F_o’$ 初始化,最后再加上残差连接:
\[F_{o_{out}}=F'_o+F_o^{'(u)}\]Hierarchical Aggregation
节点表示明确考虑了对象的空间和时间交互。但这些交互大多是原子性的。为了将这些原子交互聚集为更高层次的视频元素,我们在下图中采用了一种分层聚合策略。首先,我们对每个 节点进行聚合。
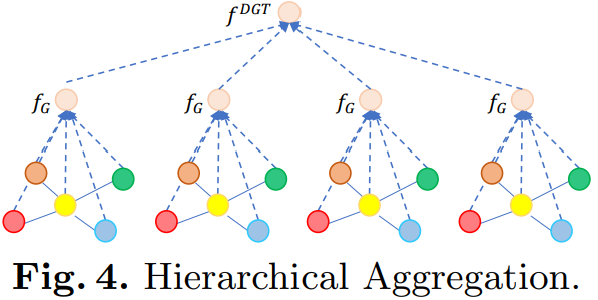
首先用一个简单的注意力机制来聚合节点
\[f_G=\sum_{i=1}^N\alpha_iF_{o_{out_i}},\alpha=\sigma(\phi_{W_G}(F_{O_{out}}))\]$f_G$ 捕获了本地对象之间的相互作用。 它可能会忽略帧的整体画面,特别是因为我们只保留 对象而不能保证它们包含该帧中所有感兴趣的对象。 因此,我们通过连接将其与帧级别的特征 $f_I$ 补充:
\[f_G=\text{ELU}(\phi_{W_m}([\phi_{W_f}(f_I);f_G]))\]接下来,我们通过如下方式对局部交互进行聚合以获得一系列 clip 级特征表示:
\[f^{DGT}=\text{MPool}(F_G)=\frac{1}{l_c}\sum^{l_v}_{t=1}f_{G_t}\]跨模态交互
为了找到与特定文本查询相关的视觉信息,视觉节点和文本节点之间的跨模型交互至关重要。给定一组由$X^v$表示的视觉节点,我们通过简单的跨模态注意力将文本信息 $X^q={x^q_m}^M_{m=1}$(M是文本 query tokens 的数量)合并到视觉节点中:
\[x^{qv}=x^v+\sum^M_{m=1}\beta_mx_m^q,\beta=\sigma(x^v(X^q)^T)\]在我们的实验中,我们探索了使用来自不同 DGT 模块级别的视觉表示进行跨模态交互的方法。在我们的实验中,我们在对象级别 $F_O$、帧级别$F_G$和剪辑级别 $F^{DGT}$上执行跨模态交互。我们发现结果在不同的数据集上有所不同。
默认情况下,我们在剪辑级别输出上执行跨模态交互(即 DGT 模块的输出 $X^v:=F^{DGT}$),因为在这一阶段节点的数量要小得多,并且节点表示已经吸收了前面层的信息。对于文本节点 $X^q$,我们通过在语言模型的词输出上进行简单的线性投影来获得它们:
\[X^q=\phi_{W_Q}(\text{BERT}(Q))\]$W_Q\in\mathbb{R}^{768\times d }$,文本查询 Q 可以是开放式问题回答中的问题,也可以是多选题中的问答对。在多选题中,我们根据不同的问答对获取到的视觉表示进行最大池化,找到与视频最相关的那个。
全局 transformer
上述 DGT 模块关注从视频剪辑中提取信息性的视觉线索。为了捕捉这些剪辑之间的时序动态,我们在跨模态交互的剪辑特征(即$F^{DGT}$)上应用另一个 H 层transformer ,并添加可学习的正弦时序位置嵌入。最后,将变换器的输出进行均值池化以获得整个视频的全局表示,即整个视频的全局表示 $f^{qv}∈R^d$ 定义如下:
\[f^{qv}=\text{MPool}(\text{MHSA}^{(H)}(F^{DGT}))\]全局 transformer具有两个主要优势:
- 它保留了逐层递进的整体结构,驱动不同粒度的视频元素。
- 它提高了视觉和文本特征之间的兼容性,可能有利于跨模态比较。
预测答案
为了获得特定答案候选的全局表示,从BERT中获取平均池化 tokens 表示:
\[f^A=\text{MPool}(X^A)\]然后通过点积计算其与查询感知视频表示 $f^{qv}$ 之间的相似性。因此,具有最大相似性的候选答案被返回作为最终预测,其中 \(F^A = \{f^A_a\}^{|A|}_{a = 1} ∈ \mathbb{R}^{|A| × d}\) ,其中 \(|A|\) 表示候选答案的数量:
\[s = f^{qv}(F^A)^T, a^*=\arg\max(s)\]对于开放式QA,直接计算问题表示 $f^q$(通过与 $f^A$中的答案表示相似的方式获得)和答案表示$F^A$之间的相似性,从而实现视频缺失QA。因此,最终的答案可以是一个联合决策,其中 $\odot$ 是逐元素乘积。:
\[s = f^{qv}(F^A)^T \odot f^{q}(F^A)^T\]在训练过程中,我们通过优化Softmax交叉熵损失函数来最大化给定样本的正确答案对应的(VQ, A)相似度:
\[\mathcal{L}=-\sum^{|A|}_{i=1}y_i\log s_i\]其中 si 是第i个样本的匹配分数。如果答案索引对应于第i个样本的ground-truth答案,则yi = 1,否则为0。
用弱配对数据预训练
为了跨模型匹配,我们鼓励每个 视频文本交互表示 $f^{qv}$ 与它的配对描述符 $f^q$ 之间的距离更近,并且在每次训练迭代中都远离来自其他视频文本对的负面描述符。这可以通过最大化以下对比目标来实现:
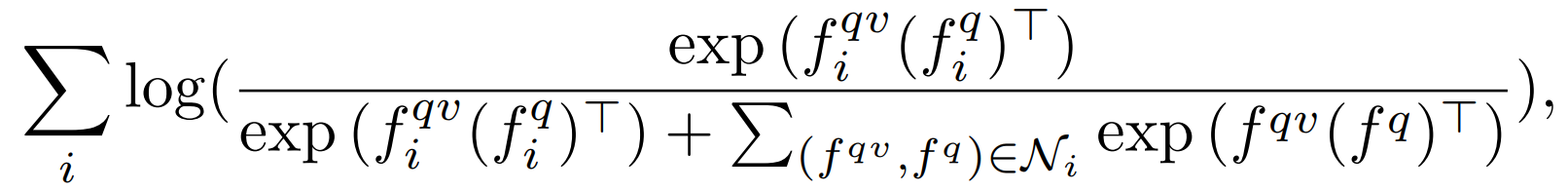
其中 Ni 表示第 i 个样本中所有负视频描述对的表示。如上所述,在计算fqv 和fq的过程中,需要优化的参数被隐藏起来。对于负抽样,我们在每个迭代周期从整个训练集中随机抽取它们。为了提高效率,我们只针对每个视频的正描述进行遮蔽语言建模。
实验
数据集
- NExT-QA 是一个手动注释的数据集,其中包含时空中的因果和时序对象交互。
- TGIF-QA 包含短小的 GIF;它询问重复动作识别、时间状态转换方面的问题。
- MSRVTT-QA ,该数据集挑战了整体视觉识别或描述能力。
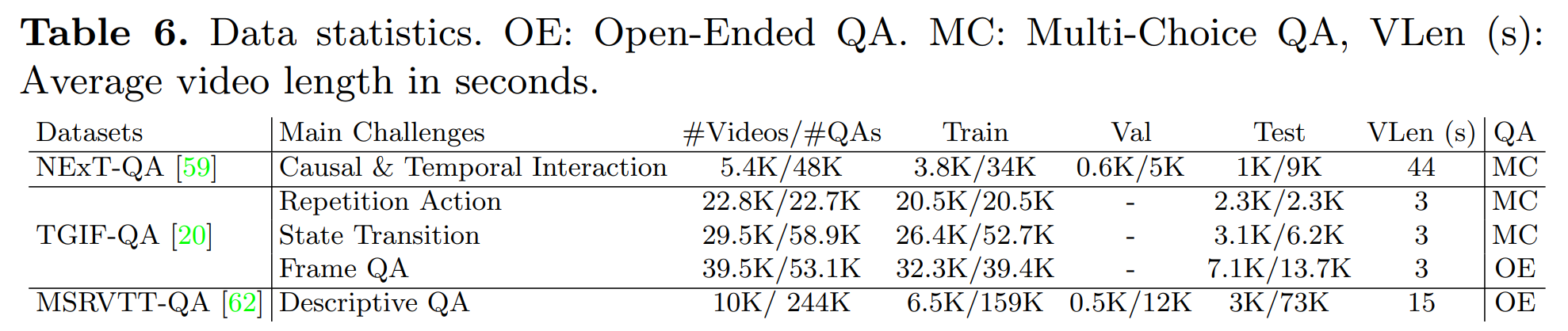
实验细节
我们将视频解码为帧,然后从每个视频中稀疏采样 $l_v$ = 32帧。这些帧被分为k= 8个片段,长度 $l_c$ = 4。
对于每一帧,我们使用目标检测模型检测并保留N= 20个高置信度区域(在无预训练实验中使用前5名),以及N= 10对于其他数据集。
模型隐藏状态的维度为d= 512。transfomer 的默认层数和自注意头数分别为H= 1和e= 8(DGT中的 edge transfomer 为e= 5)。此外,图神经网络层的数量为U= 2。
训练使用一块 Tesla V100 GPU 完成。在训练期间,我们使用初始学习率为1×10−5的余弦退火调度程序的Adam优化器。批大小设置为64,不同数据集的最大epoch范围从10到30不等。我们的超参数主要是在NExT-QA验证集上搜索得到,并在其他数据集上保持不变。不同的数据集之间最大epoch值从10到30不等。
对于带有QA注释的训练,我们首先端到端地训练整个模型(除了目标检测模型),然后冻结BERT并微调第一阶段获得的最佳模型的其他部分。两个阶段中最好的结果被确定为最终结果。
对于基于网络抓取的数据预训练,我们在WebVid2.5M中随机选择了0.18M个视频文本数据(少于10%)。然后以每秒5帧的速度提取视频,并对其进行与QA相同的方式处理。我们使用初始学习率为5 × 10 ^ -5和批大小64来优化模型。跨模态匹配中一个视频的负描述数设置为63,它们是从整个训练集中其他视频的描述中随机选择的。
此外,在掩蔽语言建模中,以15%的概率对文本标记进行破坏。一个损坏的标记将以80%的机会替换为“ [MASK]”标记,以10%的机会替换为任意标记,并以10%的机会替换为相同的标记。我们在最多两个epoch内训练模型,这给出了最佳的一般化结果,大约需要2个小时。
分析
与其他基于图的方法相比VGT具有几个优势:
- 它明确地建模了对象及其相互作用的时间动态。
- 通过视频与文本之间的显式相似度比较而不是分类来解决视频问答问题。
- 使用transfomer 表示视觉和文本数据,这可能提高特征兼容性并促进跨模态交互和比较
- VGT在训练和推理中使用的帧数要少得多,从而提高了视频编码效率。
比较了使用相似性比较方法(relevance comparison)和分类方法(classification)来解决视频问答任务(VideoQA)的效果。通过将 DGT 的输出与来自 BERT 的标记表示连接起来形成文本-视频表示序列,并将其馈送到跨模态 Transfomer 来进行信息融合。然后,将“[CLS]” token 的输出馈送给一个开放型QA中的“A”维分类器或二元相关性QA中的单向分类器。结果表明,这种基于分类模型变体(Comp → CLS)导致性能急剧下降。这种方法也会严重的过拟合。因此相似性比较方法更好。
跨模态交互在 TGIF-QA 上提高了超过 10% 的准确率。可能的原因是,GIF 是短剪辑视频,只包含与问题相关的视觉内容。这大大降低了对正例答案的空间时间定位挑战,尤其是当大多数负例都不出现在短剪辑中时。因此,在这个数据集上,跨模态交互表现得更有效。NExT-QA 中的视频没有被剪辑,所以改进相对较小。根据这些观察结果,我们在 TGIF-QA 中针对时空推理任务在帧级和片段级输出执行了跨模态交互,并为其他数据集保留了默认实现。
预训练可以稳定地提高QA性能,特别是在NExT-QA上。在TGIF-QA上的相对较小的改进可能是由于TGIF-QA数据集较大,并且有足够的注释数据进行微调。因此,预训练的帮助较少。此外,我们发现使用掩蔽语言建模(MLM)微调可以提高从验证到测试集的一般化能力,从而在NExT-QA测试集中实现最佳总体准确率(即55.7%)。
关于采样的视频剪辑数量,我们发现8个片段的设置比4个片段稳定地胜出。这是可以理解的,因为NExT-QA中的视频相对较长。至于采样的区域,在从头开始训练模型时,5个区域的设置给出了相对较好的结果。然而,当考虑预训练时,20个区域的设置给出了更好的结果。这种差异可能是由于学习更多的区域会导致过拟合问题,尤其是在数据集不够大时,构建的图变得更大、更复杂。
VGT 中的 BERT 编码器占用了 82% 的参数,视觉部分只有 24M 参数。们还实现了一个小版本的 VGT,通过用 DistilBERT 替换掉 BERT,仍然可以实现强大的性能(即53.46%,相比原来的 VGT 略差)。
再看三个例子:

- 例子(a)显示模型没有DGT 模块易于预测原子或接触动作(例如,“抓住”),这些动作可以在静态帧级别捕获。但是没有连贯起来看视频得出了错误的答案。
- (b) 显示了没有预训练的模型无法预测高度抽象的答案(例如,“调整”)。
- (c) 中展示了失败的情况。它表明当视频中的感兴趣对象很小并且检测器无法检测到时,我们的模型倾向于预测与问题在语义上接近的干扰答案。
保留更多的检测区域可能会有所帮助,但需要仔细权衡图的复杂性和推理效率。另一种选择是进行 modulated detection ,我们将其留待未来探索。