MiniGPT-4:Enhancing Vision-Language Understanding with Advanced Large Language Models
读论文时间!
多模态大模型MiniGPT-4
内容整理自《大规模语言模型从理论到实践》
模型
MiniGPT-4 期望将来自预训练视觉编码器的图像信息与大语言模型的文本信息对齐,它的模 型架构如图所示。具体来说主要由三个部分构成:预训练的大语言模型 Vicuna,预训练的视觉编码器以及一个单一的线性投影层。
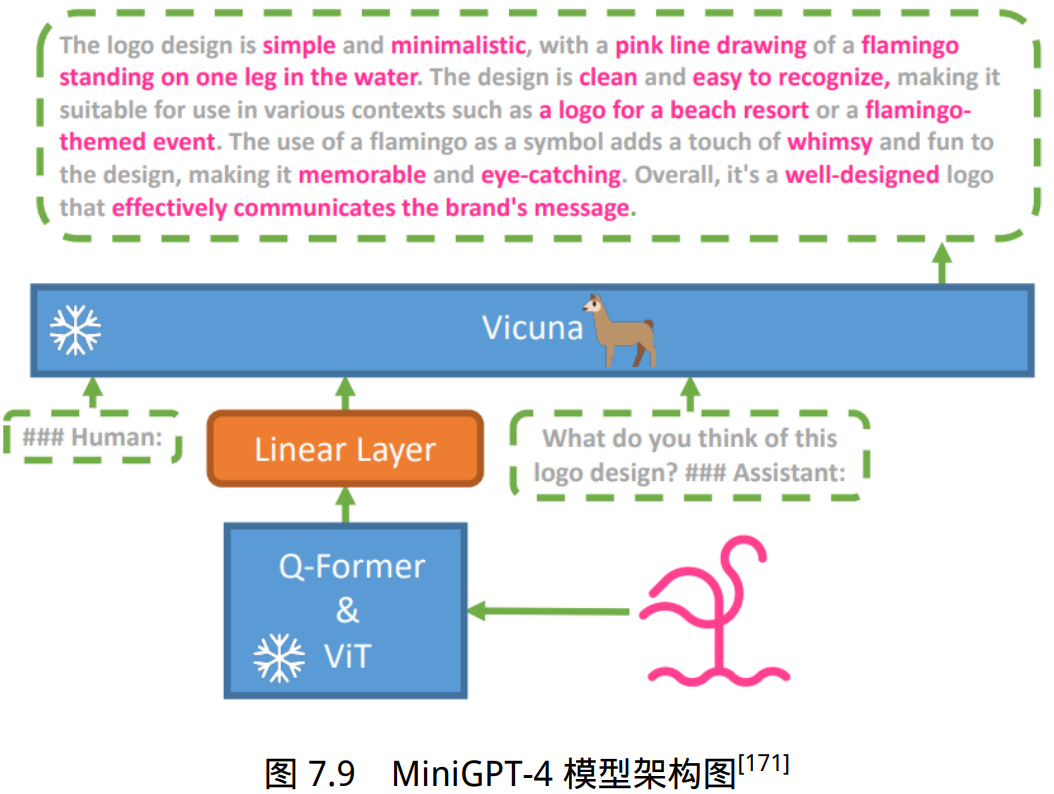
Vicuna 模型
Vicuna 是一个基于解码器的语言模型,它建立在 LLaMa 的基础上,可以执行广泛的复杂 语言任务。在 MiniGPT-4 中,它的主要任务是同时理解输入进来的文本与图像数据,对多个模态 的信息具有感知理解能力,生成符合指令的文本描述。在具体构建过程中,MiniGPT-4 并不从头 开始训练大语言模型,而是直接利用现有的 Vicuna-13B 或 Vicuna-7B 版本,冻结所有的参数权重, 降低计算开销。
视觉编码器
为了让大语言模型具备良好的视觉感知能力,MiniGPT-4 使用了与 BLIP-2 相同的预训练视觉语言模型。该模型由两个部分组成:视觉编码器 ViT(Vision Transformer)和图文对齐模 块 Q-Former。
输入图像在传入视觉编码器后,首先会通过 ViT 做一步初步的编码,提取出图像中的基本视觉特征。然后通过预训练的 Q-Former 模块,进一步的将视觉编码与文本编码对齐,得到 语言模型可以理解的向量编码。
对于视觉编码器 ViT,MiniGPT-4 使用了 EVA-CLIP 中的 ViT-G/14 进行实现,初始化该模 块的代码如下所示:
1
2
3
4
5
6
# 创建 Eva-ViT-G 模型,这是一种特定的视觉基础模型
visual_encoder = create_eva_vit_g(
img_size, drop_path_rate, use_grad_checkpoint, precision
)
# 创建 LayerNorm 用于视觉编码器的标准化
ln_vision = LayerNorm(visual_encoder.num_features)
其中:
- img_size 表示输入图像的尺寸;
- drop_path_rate 表示使用 drop_path 的比例,这 是一种正则化技术;
- use_grad_checkpoint 表示是否使用梯度检查点技术来减少内存使用;
- precision 表示训练过程中的精度设置。
对于图文对齐模块 Q-Former,在具体实现中通常使用预训练的 BERT 模型。它通过计算图像 编码和查询(一组可学习的参数)之间的交叉注意力,更好地将图像表示与文本表示对齐。初始 化该模块的代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def init_Qformer(cls, num_query_token, vision_width, cross_attention_freq=2):
# 使用预训练的 BERT 模型配置 Q-Former
encoder_config = BertConfig.from_pretrained("bert-base-uncased")
# 分别设置编码器的宽度与查询长度
encoder_config.encoder_width = vision_width
encoder_config.query_length = num_query_token
# 在 BERT 模型的每两个块之间插入交叉注意力层
encoder_config.add_cross_attention = True
encoder_config.cross_attention_freq = cross_attention_freq
# 创建一个带有语言模型头部的 Bert 模型作为 Q-Former 模块
Qformer = BertLMHeadModel(config=encoder_config)
# 创建查询标记并初始化,这是一组可训练的参数,用于查询图像和文本之间的关系
query_tokens = nn.Parameter(
torch.zeros(1, num_query_token, encoder_config.hidden_size)
)
query_tokens.data.normal_(mean=0.0, std=encoder_config.initializer_range)
# 返回初始化的 Q-former 模型和查询标记
return Qformer, query_tokens
线性投影层
视觉编码器虽然已经在广泛的图像-文本任务中做了预训练,但它们本质上没有针对 LLaMA、 Vicuna 等大语言模型做过微调。为了弥补视觉编码器和大语言模型之间的差距,MiniGPT-4 增加 了一个可供训练的线性投影层,期望通过训练将编码的视觉特征与 Vicuna 语言模型对齐。
通过定 义一个可训练的线性投影层,将 Q-Former 输出的图像特征映射到大语言模型的表示空间,以便结 合后续的文本输入做进一步的处理和计算。创建该模块并处理图像输入的代码如下:
1
2
3
4
5
6
# 创建线性投影层,将经过 Q-Former 转换的图像特征映射到语言模型的嵌入空间
# img_f_dim 是图像特征的维度
# llama_model.config.hidden_size 是语言模型的隐藏状态的维度
self.llama_proj = nn.Linear(
img_f_dim, self.llama_model.config.hidden_size
)
输入图像后 MiniGPT-4 完整的处理流程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def encode_img(self, image):
device = image.device
with self.maybe_autocast():
# 使用视觉编码器对图像进行编码,再使用 LayerNorm 标准化
image_embeds = self.ln_vision(self.visual_encoder(image)).to(device)
# 默认使用冻结的 Q-Former
if self.has_qformer:
# 创建图像的注意力掩码
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(device)
# 扩展查询标记以匹配图像特征的维度
query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
# 使用 Q-Former 模块计算查询标记和图像特征的交叉注意力,更好地对齐图像和文本
query_output = self.Qformer.bert(
query_embeds=query_tokens,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
)
# 通过线性投影层将 Q-Former 的输出映射到语言模型的输入
inputs_llama = self.llama_proj(query_output.last_hidden_state)
# 创建语言模型的注意力掩码
atts_llama = torch.ones(inputs_llama.size()[:-1], dtype=torch.long).to(image.device)
# 返回最终输入进语言模型中的图像编码和注意力掩码
return inputs_llama, atts_llama
同时,为了减少训练开销、避免全参数微调带来的潜在威胁。MiniGPT-4 将预训练的大语言模型和视 觉编码器同时冻结,只需要单独训练线性投影层,使视觉特征和语言模型对齐。
训练
为了获得真正具备多模态能力的大语言模型,MiniGPT-4 提出了一种分为两阶段的训练方法。
- 第一阶段,MiniGPT-4 在大量的图像-文本对数据上进行预训练,以获得基础的视觉语言知识。
- 第 二阶段,MiniGPT-4 使用数量更少但质量更高的图像-文本数据集进行微调,以进一步提高预训练 模型的生成质量与综合表现。
预训练
在预训练阶段,MiniGPT-4 希望从通过大量的图像-文本对中学习视觉语言知识。以 Conceptual Caption 数据集为例,数据格式如图所示,包含基本的图像信息与对应的文本描述。

在第一阶段的训练过程中,预训练的视觉编码器和大语言模型都设置为冻结状态,只对单个 的线性投影层进行训练。预训练共进行了约 2 万步,批量大小为 256,覆盖了 500 万个图像-文本 对,在 4 张 A100 上训练了 10 个小时。
下面作为一段示例代码,有助于更好地理解 MiniGPT-4 的 训练过程。实现了整个 MiniGPT-4 模型的前向传播过程,包括图像和文本的编码、提示处理、多 模态数据编码的连接,以及最终损失的计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
def forward(self, samples):
image = samples["image"]
# 对输入图像进行编码
img_embeds, atts_img = self.encode_img(image)
# 生成文本指令
instruction = samples["instruction_input"] if "instruction_input" in samples else None
# 将指令包装到提示中
img_embeds, atts_img = self.prompt_wrap(img_embeds, atts_img, instruction)
# 配置 tokenizer 以正确处理文本输入
self.llama_tokenizer.padding_side = "right"
text = [t + self.end_sym for t in samples["answer"]]
# 使用 tokenizer 对文本进行编码
to_regress_tokens = self.llama_tokenizer(
text,
return_tensors="pt",
padding="longest",
truncation=True,
max_length=self.max_txt_len,
add_special_tokens=False
).to(image.device)
# 获取 batch_size
batch_size = img_embeds.shape[0]
# 创建开始符号的嵌入向量和注意力掩码
bos = torch.ones([batch_size, 1],
dtype=to_regress_tokens.input_ids.dtype,
device=to_regress_tokens.input_ids.device) * self.llama_tokenizer.bos_token_id
bos_embeds = self.embed_tokens(bos)
atts_bos = atts_img[:, :1]
# 连接图像编码、图像注意力、文本编码和文本注意力
to_regress_embeds = self.embed_tokens(to_regress_tokens.input_ids)
inputs_embeds, attention_mask, input_lens = self.concat_emb_input_output(img_embeds, atts_img, to_regress_embeds, to_regress_tokens.attention_mask)
# 获得整体的输入编码和注意力掩码
inputs_embeds = torch.cat([bos_embeds, inputs_embeds], dim=1)
attention_mask = torch.cat([atts_bos, attention_mask], dim=1)
# 创建部分目标序列,替换 PAD 标记为-100
part_targets = to_regress_tokens.input_ids.masked_fill(
to_regress_tokens.input_ids == self.llama_tokenizer.pad_token_id, -100
)
# 创建完整的目标序列,用于计算损失
targets = (
torch.ones([inputs_embeds.shape[0], inputs_embeds.shape[1]], dtype=torch.long).to(image.device).fill_(-100)
)
for i, target in enumerate(part_targets):
targets[i, input_lens[i] + 1:input_lens[i] + len(target) + 1] = target
# 在自动混合精度环境下,计算语言模型的输出
with self.maybe_autocast():
outputs = self.llama_model(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
return_dict=True,
labels=targets,
)
loss = outputs.loss
# 返回损失作为输出
return {"loss": loss}
在第一轮训练完成后,MiniGPT-4 获得了关于图像的丰富知识,并且可以根据人类查询提供 合理的描述,但是它在生成连贯的语句输出方面遇到了困难。例如,可能会产生重复的单词或句 子、碎片化的句子或者完全不相关的内容。这样的问题阻碍了 MiniGPT-4 与人类进行真实交流时 流畅的视觉对话能力。
微调
研究者注意到,预训练的 GPT-3 面临过类似的问题。虽然在大量的语言数据集上做了预训练, 但模型并不能直接生成符合用用户意图的文本输出。GPT-3 通过从人类反馈中进行指令微调和强 化学习的过程,产生了更加人性化的输出。借鉴这一点,研究者期望预训练的 MiniGPT-4 也可以 做到与用户意图对齐,增强模型的可用性。
在预训练的基础上,研究人员使用精心构建的高质量图像-文本对对预训练的 MiniGPT-4 模型 进行微调。在训练过程中,MiniGPT-4 同样要完成类似的文本描述生成任务,不过具体的任务指 令不再固定,而是来自一个更广泛的预定义指令集。例如,“详细描述此图像”,“你可以为我描述 此图像的内容吗”,或者是“解释这张图像为什么有趣”。微调训练代码实现只是在训练数据集和文本 提示上与预训练过程有略微的不同。
微调结果表明,MiniGPT-4 能够产生更加自然、更加流畅的视觉问答反馈。同时,这一训练 过程也是非常高效的,只需要 400 个训练步骤,批量大小为 12,使用单张 A100 训练 7 分钟即可 完成。
数据集
进行微调的数据集是研究者精心构建了一个高质量的、视觉语言领域的图像-文本数据集。该数据集的构建 主要通过以下两个基本操作产生:
更全面的描述。研究者使用构建提示的策略,鼓励基于 Vicuna 的多模态模型生成 给定图像的全面描述。具体的提示模板如下所示:
1
2
###Human: <Img><ImageFeature></Img> Describe this image in detail.
Give as many details as possible. Say everything you see. ###Assistant:
<Img>作 为提示符,标记了一张图像输入的起止点。 <ImageFeature>代表输入图像在经过视觉编码器 和线性投影层后的视觉特征。在这步操作中,一共从 Conceptual Caption 数据集中随机选择 了 5,000 张图像,生成对应的、内容更加丰富的文本描述。
更高质量的描述。由于这些生成的描述仍然存在较多的错误和噪音,例如不连贯的陈述、单词或句子的反复。研究者利用 ChatGPT 强大的语言理解和生成能力,让其作为一个自动化的文本质量评估者,对生成的 5,000 份图 像-文本对进行检查。期望通过这步操作,修正文本描述中的语义、语法错误或结构问题。该 步操作使用 ChatGPT 自动地改进描述。具体的提示模板如下所示:
1
2
3
4
5
Fix the error in the given paragraph.
Remove any repeating sentences, meaningless characters, not English sentences, and so on.
Remove unnecessary repetition. Rewrite any incomplete sentences.
Return directly the results without explanation.
Return directly the input paragraph if it is already correct without explanation.
在经过 ChatGPT 的评估与改进后,5000 个图像-文本对中最终保留下 3500 对符合要求的高 质量数据,用于模型微调。具体的数据格式如图所示,包含基本的图像信息 和更加全面的文本描述。
