Improving Language Understanding by Generative Pre-Training
读论文时间!
生成式预训练模型 GPT。
参考:
- 李沐读论文
- 《大规模语言模型从理论到实践》
- 前置知识:Transformer
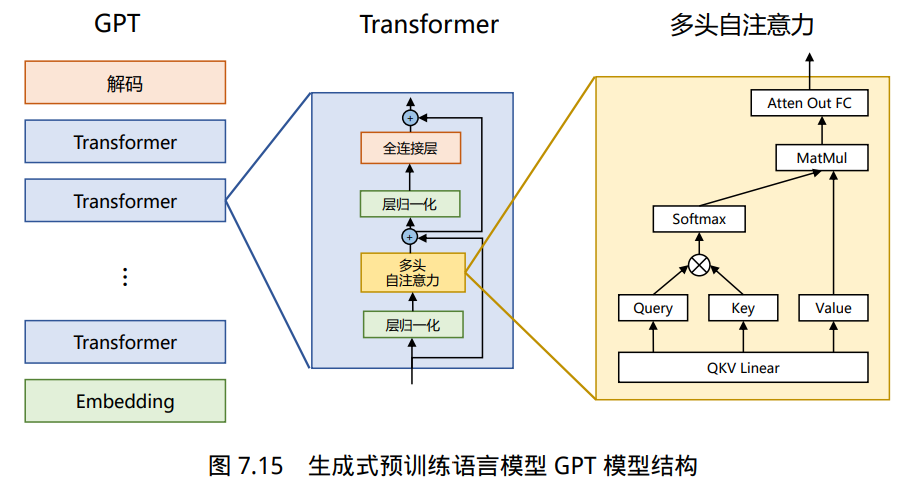
GPT的本质是把transformer的解码器拿出来,然后在没有标号的大量文本数据训练一个语言模型,来获得一个预训练模型,然后再用它在子任务上作微调。
概述

- 在transformer出现后,GPT 把transformer的解码器拿出来成为了GPT这个模型。
- 之后BERT把transformer的编码器拿出来做成了BERT这个模型,BERT的基础模型对标的是GPT,在可学习参数规模基本一样的情况下,效果比GPT更好。BERT的large模型甚至比它的基础模型更好。
- 在之后又出现了GPT2和GPT3,技术路线基本不变(具体指依旧使用transformer的解码器),可学习参数和样本规模越变越大,效果也越来越好。
- GPT2的特点是适合做zero-shot,指的是模型在没有进行显式训练的情况下,能够对之前从未见过的类别或任务进行推理和泛化。传统上,模型只能在训练数据中出现过的类别上进行准确预测,而zero-shot学习推动了模型在未见示例的情况下进行预测的能力。
- GPT3的特点是是在后续子任务的训练上权重是不会改变的。主要原因是因为GPT3的可学习参数规模达到了千亿级别,在这个规模上,做微调改变参数是很困难的一件事情。
BERT模型会比GPT模型效果优秀原因之一,是因为BERT模型拿出的是transformer的编码器,编码器是可以从两个方向看文本,可以类比为做完形填空。GPR拿出的是transformer的解码器,它只能从左往右去看文本。
虽然从两个方向看文本可以得到的效果更好,但是所付出的代价是它只能做有限的工作。对于一些生成式的工作或者语言翻译,是不可能两个方向同时去做的。所以说GPT因为只从左往右去看文本,所以说能做的工作会更多。
GPT1
论文标题是Improving Language Understanding by Generative Pre-Training。使用通用的预训练来提升语言的理解能力。
文章提出的问题是,在自然语言处理的任务中,存在大量没有标签的数据,标好的数据是非常少的。如果只是使用少量的标好的数据做训练,要达到一个好效果是比较难的。
解决方法是,在没有标号的大量文本数据训练一个语言模型,来获得一个预训练模型,然后再用它在子任务上作微调。
先预训练再微调
“先预训练再微调”的思想在很久之前就已经在计算机视觉领域流行,但是在自然语言处理界一直没有流行起来,主要原因是缺少像 ImageNet 那样大规模已经标好的数据。 ImageNet 的数据量是一百万张图片,但如果要在自然语言处理中达到同样的效果,数据量还要再翻十倍,因为一张图片的信息远比一个句子多,要学习到同样的东西,文本的规模必须更大。
使用未标好的数据进行训练时主要会遇到两个困难:第一个困难是目标函数的选择。自然语言处理的子任务很多,可能会有一些目标函数对于某一个子任务上效果很好,但是没有找到一个适合于所有子任务的目标函数。第二个难点是如何把学习到的文本表示传递(迁移)给下游的子任务。
预训练
假设文本为$\mathcal{U}={u_1, … u_n}$,第一个目标函数是最大化下列似然函数,本质是最大化第i个词出现的概率,使用这个词之前的k个词做预测:
\[L_1(\mathcal{U})=\sum_i \log P(u_i|u_{i-k},...u_{i-1};\Theta)\]- 其中$\Theta$为参数
- k是窗口大小
使用最大似然函数,本质上就是要求模型输出跟原来文本长得最像的文章。
在具体做预测时,假设要预测u这个词出现的概率,我们首先需要知道前k个词,假设为$U={u_{i-k},…u_{i-1}}$,公式为:
\[h_0=UW_e+W_p\] \[h_l=\text{transfomer_block}(h_{l-1}) \forall i \in [1,n]\] \[P(u)=\text{softmax}(h_nW_e^T)\]简单来说,就是把前面的所有词先做投影,加上位置编码,再经过n层transformer解码器块,然后再做投影,经过softmax得到概率。
微调
作微调时我们使用已经标好的数据集$\mathcal{C}$,假设文本为$x_1,…x_m$,标签为$y$,具体预测方法是:
\[P(y|x_1,...x_m)=\text{softmax}(h_l^mW_y)\]简单来说,就是把文本放到已经预训练好的transformer块,拿到最后一个词的最后一层输出,做投影(经过输出层),经过softmax得到概率。
接着做最大似然:
\(L_2(\mathcal{C})=\sum_{(x,y)} \log P(y|x_1,...x_m)\) 两个放一块训练效果最佳:
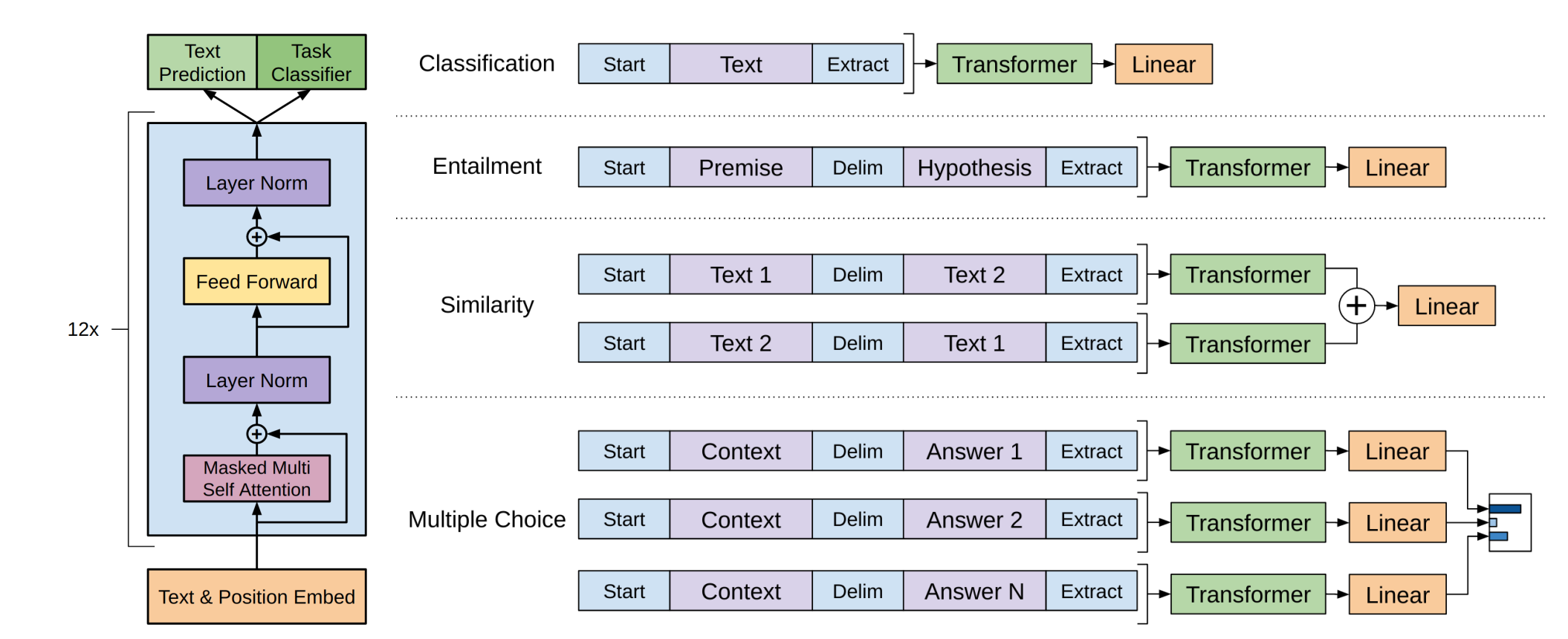
\[L_3(\mathcal{C})=L_2(\mathcal{C})+\lambda L_1(\mathcal{C})\]把NLP不同的子任务表示为统一的形式
分类、蕴含、相似度、多选。
GPT2
论文标题是Language Models are Unsupervised Multitask Learners,语言模型是无监督的多任务学习器。GPT-2 有15亿参数,百万网页的数据集:WebText。 本质上可以理解为一个参数更多、使用数据集更大、的没有微调过程的GPT1。
Zero-shot
GPT2的卖点是做zero-shot,指在经过预训练之后,对于子任务没有进行微调或者显式训练,直接进行子任务。
举一个语言翻译的例子,输入的序列是(translate to french, english text, french text),第一部分是一个让它去做翻译任务的提示词,第二部分是英语文本,第三部分是法语文本。
为什么这种方式可以工作?一方面,如果模型足够强大,可以理解提示词,那最好。另一方面,这种任务可能在预训练的文本里面出现过。
GPT3
论文标题是Language Models are Few-Shot Learners,语言模型是few shot learners。1750亿个可学习的参数。特点是在子任务上会提供少量的样本,但是在预训练之后就不再更新梯度或者微调,主要原因包括在这么大的参数上进行更新梯度非常困难。
举一个语言翻译的例子,输入的序列是
1
2
3
4
translate to Chinese
apple -> 苹果
red -> 红色
human -> ?
第一部分是一个让它去做翻译任务的提示词,后面有两个英译中的例子,最后做翻译的任务。