基于 verl 的 Qwen3.5-0.8B GRPO 记录
本文旨在完整记录一次利用 verl 对 Qwen3.5-0.8B 进行 GRPO 训练的流程,内容涵盖环境配置、任务定义、数据准备、过程监控、结果分析等
实验环境
- python 3.11
- torch 2.10.0+cu128
- vllm 0.18.0
- transformers 5.3.0.dev0
- ray 2.56.0
- verl 0.9.0.dev0
- GPU 1x NVIDIA 4090 (CUDA 13.2)
环境安装与准备
首先创建独立的 Python 3.11 环境。当前 verl main 分支会用到 enum.StrEnum,Python 3.10 在 Ray worker import 阶段会报错。
1
2
conda create -n verl-qwen35 python=3.11 -y
conda activate verl-qwen35
然后安装 verl 源码。这里使用源码安装,方便跟上 Qwen3.5 相关示例脚本和最新配置。
1
2
3
git clone --depth 1 https://github.com/verl-project/verl.git
cd verl
pip install -e '.[math]'
Qwen3.5 对依赖版本比较敏感。普通 transformers==4.57.x 不能识别 model_type: qwen3_5,需要安装 Qwen3.5 示例中对应的 transformers commit。vLLM 使用 0.18.0,同时补上 verl 运行时会用到的 TransferQueue。
1
2
3
4
5
6
pip install 'vllm==0.18.0' 'TransferQueue==0.1.8'
pip install --no-deps \
'git+https://github.com/huggingface/transformers.git@cc7ab9be508ce6ed3637bba9e50367b29b742dc6'
pip install 'huggingface-hub>=1.3.0'
安装后可以简单检查版本:
1
2
3
4
5
6
7
8
python - <<'PY'
import torch, transformers, vllm, ray
print("torch", torch.__version__, "cuda", torch.version.cuda, torch.cuda.is_available())
print("transformers", transformers.__version__)
print("vllm", vllm.__version__)
print("ray", ray.__version__)
PY
模型从 ModelScope 下载。
1
2
3
4
5
pip install -U modelscope
modelscope download \
--model Qwen/Qwen3.5-0.8B \
--local_dir ./models/Qwen3.5-0.8B
数据先用 GSM8K。verl 已经提供了预处理脚本,会把原始数据整理成训练需要的 parquet 文件。
1
2
3
4
cd verl
python examples/data_preprocess/gsm8k.py \
--local_dir ./data/gsm8k
生成结果包括:
1
2
./data/gsm8k/train.parquet
./data/gsm8k/test.parquet
任务定义
GSM8K 是小学数学文字题数据集,每条样本包含一道自然语言题目和一段带推理过程的标准答案。对于 reward,模型只要在回答末尾按约定格式输出最终数字,就可以用规则函数判断对错。
原始 GSM8K 样本大致长这样:
1
2
3
4
{
"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n#### 72"
}
verl 的预处理脚本会做两件事。第一,把题目包装成 chat 格式的 prompt,并追加一句格式要求:Let's think step by step and output the final answer after "####". 第二,从标准答案中抽取 #### 后面的数字,放进 reward_model.ground_truth,供后续规则奖励使用。
处理后的 parquet 样本可以理解为下面这种结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
"data_source": "openai/gsm8k",
"prompt": [
{
"role": "user",
"content": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? Let's think step by step and output the final answer after \"####\"."
}
],
"ability": "math",
"reward_model": {
"style": "rule",
"ground_truth": "72"
},
"extra_info": {
"split": "train",
"index": 0,
"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n#### 72"
}
}
训练时,模型看到的是 prompt,生成一段带推理过程的回答。默认 reward 函数会从模型输出最后一段中匹配 #### 数字,再和 ground_truth 比较。匹配正确给 1.0,没有按格式输出或数字错误给 0.0。
比如下面这个输出可以拿到奖励:
1
2
3
Natalia sold half as many clips in May, so she sold 24 in May.
Altogether she sold 48 + 24 = 72 clips.
#### 72
而下面这个即使文字解释接近,也会因为格式不符合 strict 规则而拿不到奖励:
1
Natalia sold 72 clips altogether.
训练配置
verl 的配置主要通过 Hydra override 传入。为了复现实验,最方便的做法是把命令整理成一个脚本,例如放在项目目录下的 scripts/run_qwen35_0_8b_gsm8k_grpo.sh。下面这份配置使用单张 4090:每步取 8 个 prompt,每个 prompt 采样 8 条 response,最大 response 长度为 1024,训练 48 step;同时开启 TensorBoard 记录,并每 24 step 保存一次 checkpoint。为保证长时间任务的稳定,推荐配合 screen 或 tmux 使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
#!/usr/bin/env bash
set -euo pipefail
###########################
# user-adjustable
###########################
export CUDA_VISIBLE_DEVICES=0
export CUDA_DEVICE_ORDER=PCI_BUS_ID
export WANDB_MODE=disabled
export TOKENIZERS_PARALLELISM=false
export RAY_DEDUP_LOGS=0
PYTHON_BIN=${PYTHON_BIN:-python}
VERL_DIR=${VERL_DIR:-/path/to/verl}
MODEL_PATH=${MODEL_PATH:-/path/to/models/Qwen3.5-0.8B}
TRAIN_FILE=${TRAIN_FILE:-/path/to/data/gsm8k/train.parquet}
TEST_FILE=${TEST_FILE:-/path/to/data/gsm8k/test.parquet}
PROJECT_NAME=${PROJECT_NAME:-GRPO-Qwen3_5}
EXPERIMENT_NAME=${EXPERIMENT_NAME:-Qwen3_5-0_8B-GSM8K-b8n8-r1024-s48-tb-save24}
OUTPUT_DIR=${OUTPUT_DIR:-/path/to/outputs/${EXPERIMENT_NAME}}
TRAIN_SAMPLES=${TRAIN_SAMPLES:-1024}
VAL_SAMPLES=${VAL_SAMPLES:-256}
TRAIN_BATCH_SIZE=${TRAIN_BATCH_SIZE:-8}
ROLLOUT_N=${ROLLOUT_N:-8}
MAX_PROMPT_LENGTH=${MAX_PROMPT_LENGTH:-512}
MAX_RESPONSE_LENGTH=${MAX_RESPONSE_LENGTH:-1024}
TOTAL_STEPS=${TOTAL_STEPS:-48}
TEST_FREQ=${TEST_FREQ:-12}
SAVE_FREQ=${SAVE_FREQ:-24}
LOGGER=${LOGGER:-'["console","tensorboard"]'}
ROLLOUT_GPU_MEM_UTIL=${ROLLOUT_GPU_MEM_UTIL:-0.9}
LOG_PROB_MAX_TOKEN_LEN=${LOG_PROB_MAX_TOKEN_LEN:-2048}
ROLLOUT_MAX_MODEL_LEN=${ROLLOUT_MAX_MODEL_LEN:-1792}
ray stop --force || true
mkdir -p "${OUTPUT_DIR}"
cd "${VERL_DIR}"
###########################
# parameter arrays
###########################
DATA=(
algorithm.adv_estimator=grpo
algorithm.use_kl_in_reward=False
data.train_files="${TRAIN_FILE}"
data.val_files="${TEST_FILE}"
data.train_max_samples=${TRAIN_SAMPLES}
data.val_max_samples=${VAL_SAMPLES}
data.train_batch_size=${TRAIN_BATCH_SIZE}
data.max_prompt_length=${MAX_PROMPT_LENGTH}
data.max_response_length=${MAX_RESPONSE_LENGTH}
data.filter_overlong_prompts=True
data.truncation=error
data.shuffle=False
data.dataloader_num_workers=0
)
MODEL=(
actor_rollout_ref.model.path="${MODEL_PATH}"
actor_rollout_ref.model.use_remove_padding=False
actor_rollout_ref.model.enable_gradient_checkpointing=True
+actor_rollout_ref.model.override_config.attn_implementation=eager
)
ACTOR=(
actor_rollout_ref.actor.optim.lr=1e-6
actor_rollout_ref.actor.ppo_mini_batch_size=${TRAIN_BATCH_SIZE}
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=1
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${LOG_PROB_MAX_TOKEN_LEN}
actor_rollout_ref.actor.use_kl_loss=True
actor_rollout_ref.actor.entropy_coeff=0
actor_rollout_ref.actor.kl_loss_coef=0.01
actor_rollout_ref.actor.kl_loss_type=low_var_kl
actor_rollout_ref.actor.use_torch_compile=False
actor_rollout_ref.actor.strategy=fsdp2
actor_rollout_ref.actor.use_dynamic_bsz=False
actor_rollout_ref.actor.fsdp_config.fsdp_size=1
actor_rollout_ref.actor.fsdp_config.reshard_after_forward=True
actor_rollout_ref.actor.fsdp_config.offload_policy=True
actor_rollout_ref.actor.fsdp_config.param_offload=True
actor_rollout_ref.actor.fsdp_config.optimizer_offload=True
actor_rollout_ref.actor.fsdp_config.ulysses_sequence_parallel_size=1
)
REF=(
actor_rollout_ref.ref.strategy=fsdp2
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=1
actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${LOG_PROB_MAX_TOKEN_LEN}
actor_rollout_ref.ref.use_torch_compile=False
actor_rollout_ref.ref.fsdp_config.reshard_after_forward=True
actor_rollout_ref.ref.fsdp_config.offload_policy=True
actor_rollout_ref.ref.fsdp_config.param_offload=True
actor_rollout_ref.ref.fsdp_config.ulysses_sequence_parallel_size=1
)
ROLLOUT=(
actor_rollout_ref.rollout.name=vllm
actor_rollout_ref.rollout.ignore_eos=False
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=1
actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${LOG_PROB_MAX_TOKEN_LEN}
actor_rollout_ref.rollout.tensor_model_parallel_size=1
actor_rollout_ref.rollout.gpu_memory_utilization=${ROLLOUT_GPU_MEM_UTIL}
actor_rollout_ref.rollout.n=${ROLLOUT_N}
actor_rollout_ref.rollout.enable_chunked_prefill=True
actor_rollout_ref.rollout.max_model_len=${ROLLOUT_MAX_MODEL_LEN}
actor_rollout_ref.rollout.max_num_seqs=64
actor_rollout_ref.rollout.max_num_batched_tokens=8192
actor_rollout_ref.rollout.free_cache_engine=True
actor_rollout_ref.rollout.enforce_eager=False
actor_rollout_ref.rollout.enable_prefix_caching=False
actor_rollout_ref.rollout.agent.num_workers=1
actor_rollout_ref.rollout.checkpoint_engine.update_weights_bucket_megabytes=512
+actor_rollout_ref.rollout.engine_kwargs.vllm.limit_mm_per_prompt.image=0
+actor_rollout_ref.rollout.engine_kwargs.vllm.limit_mm_per_prompt.video=0
)
TRAINER=(
trainer.critic_warmup=0
trainer.logger="${LOGGER}"
trainer.project_name="${PROJECT_NAME}"
trainer.experiment_name="${EXPERIMENT_NAME}"
trainer.n_gpus_per_node=1
trainer.nnodes=1
trainer.balance_batch=False
trainer.resume_mode=disable
trainer.val_before_train=False
trainer.save_freq=${SAVE_FREQ}
trainer.test_freq=${TEST_FREQ}
trainer.total_epochs=1
trainer.total_training_steps=${TOTAL_STEPS}
trainer.default_hdfs_dir=null
trainer.default_local_dir="${OUTPUT_DIR}"
)
REWARD=(
reward.num_workers=1
)
TRANSFER_QUEUE=(
transfer_queue.backend.SimpleStorage.num_data_storage_units=1
)
###########################
# launch
###########################
"${PYTHON_BIN}" -m verl.trainer.main_ppo \
"${DATA[@]}" \
"${MODEL[@]}" \
"${ACTOR[@]}" \
"${REF[@]}" \
"${ROLLOUT[@]}" \
"${TRAINER[@]}" \
"${REWARD[@]}" \
"${TRANSFER_QUEUE[@]}" \
"$@"
运行时直接执行脚本即可:
1
bash scripts/run_qwen35_0_8b_gsm8k_grpo.sh
如果需要实时看曲线,可以另开一个终端启动 TensorBoard:
1
tensorboard --logdir tensorboard_log --port 16006
重要参数:
data.train_batch_size=8表示每个 step 取 8 个 promptactor_rollout_ref.rollout.n=8表示每个 prompt 采样 8 条回答,因此一次 rollout 会产生 64 条 responsedata.max_response_length=1024给模型留出更长的推理空间,同时也会显著增加 rollout 和 log prob 计算成本actor_rollout_ref.model.use_remove_padding=False是 Qwen3.5 上比较关键的一项。开启 remove padding 时,actor 侧 old log-prob 计算容易在 RoPE 相关 shape 上出错actor_rollout_ref.actor.use_dynamic_bsz=False也是同一类稳定性设置,先固定 batch 行为,避免在 smoke 和小规模观察实验里引入额外变量max_num_seqs=64对应 8 个 prompt 乘以 8 条 responsemax_model_len=1792需要覆盖 prompt 和 response 的总长度;配合max_response_length=1024时,log-prob 相关 token 上限也相应设为2048trainer.total_training_steps=48控制总 step 数trainer.test_freq=12表示每 12 step 做一次验证trainer.logger=["console","tensorboard"]同时保留终端日志和 TensorBoard 曲线trainer.save_freq=24表示每 24 step 保存一次 checkpoint。checkpoint 保存后还会恢复 rollout engine,显存余量太紧时这里也可能成为新的不稳定点
GRPO 训练
通过观察日志,我们看到训练过程的关键信息。首先,训练启动后,verl 会先做配置校验,然后启动本地 Ray。
1
2
3
4
5
6
7
8
9
[validate_config] All configuration checks passed successfully!
Started a local Ray instance.
'max_response_length': 1024
'train_batch_size': 8
'train_max_samples': 1024
'val_max_samples': 256
'experiment_name': 'Qwen3_5-0_8B-GSM8K-b8n8-r1024-s48'
'total_training_steps': 48
这几行基本确认了本次 run 的规模:训练集采样 1024 条,验证集采样 256 条,每步 8 个 prompt,最大生成长度 1024,一共训练 48 step。日志里会完整打印一次配置树,实际排查时可以用它确认 override 有没有被默认值覆盖。
接着是数据集加载和 prompt 长度过滤。GSM8K 原始 train/test 分别是 7473/1319 条,本次实验只取其中一部分做观察。
1
2
3
4
5
6
7
8
9
10
11
12
Using dataset class: RLHFDataset
dataset len: 7473
selected 1024 random samples out of 7473
filter dataset len: 1024
Using dataset class: RLHFDataset
dataset len: 1319
selected 256 random samples out of 1319
filter dataset len: 256
train and validate dataloader initialized, train dataset size: 1024, val dataset size: 256
Total training steps: 48
这里的 filter dataset len 仍然是 1024/256,说明 max_prompt_length=512 没有过滤掉额外样本。后面的 Total training steps: 48 来自 trainer 初始化阶段,也可以作为最终训练步数的二次确认。
模型和 worker 初始化阶段会打印 actor/ref、FSDP 和 reward loop 的状态。
1
2
3
4
5
6
Qwen3_5ForConditionalGeneration contains 852.99M parameters
Before FSDP, device used/total (GB): 0.39/23.52
After FSDP, device used/total (GB): 3.00/23.52
actor and ref model engine initialized
reward loop manager initialized
这说明 actor 和 ref model 都已经建好,规则奖励也已经注册。
启动阶段还会看到一条 critic 相关 warning:
这条 warning 和当前设置是匹配的。GRPO 使用 group 内相对奖励估计优势,本次配置里
algorithm.adv_estimator=grpo,所以不会启用 GAE critic。
rollout 由 vLLM 负责。日志里能看到 vLLM 服务的关键参数,以及 CUDA graph capture 的初始化过程。
1
2
3
4
5
6
7
'max_model_len': 1792
'max_num_seqs': 64
'gpu_memory_utilization': 0.9
'n': 8
Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 100%
Capturing CUDA graphs (decode, FULL): 100%
max_num_seqs=64 正好对应 8 prompt * 8 response。max_model_len=1792 用来覆盖 prompt 和 response 的总长度。CUDA graph capture 是 vLLM 启动阶段的优化步骤,首次启动会多等一会儿,后续生成会受益。
这一段也会出现一些 warning
- 第一条也能确认 vLLM 侧生成上限已经是 1024
- 第二条是 vLLM 接口弃用提示,不影响这次训练
- 第三条说明 verl 当前的 MFU 统计还没有覆盖
qwen3_5,因此日志里的perf/mfu/actor: 0.0不能用来判断训练有没有正常运行。
真正进入训练后,每个 step 会输出一行很长的指标。step 1 的代表性字段日志大致如下:
1
2
3
4
5
6
7
8
9
10
11
step:1
training/global_step:1
critic/rewards/mean:0.375
response_length/mean:467.84375
response_length/max:1024.0
response_length/clip_ratio:0.203125
timing_s/gen:89.0894
timing_s/old_log_prob:43.6307
timing_s/ref:43.0311
timing_s/update_actor:328.4308
perf/time_per_step:520.4508
critic/rewards/mean是这一批 rollout 的规则奖励均值,可以粗略理解为本 batch 中答对的比例response_length/clip_ratio表示生成被长度上限截断的比例,step 1 约为 20.3%,说明 1024 的 response length 仍然会被一部分样本打满timing_s/*可以看每个阶段的耗时,本次实验里 actor update 是主要耗时来源。
训练结束时,日志先显示进度条到 48/48,然后打印最后一次验证结果。
1
2
3
4
5
6
7
8
Training Progress: 100%|...| 48/48 [5:44:00<00:00, 430.01s/it]
step:48
val-core/openai/gsm8k/acc/mean@1:0.609375
critic/rewards/mean:0.75
response_length/mean:280.859375
response_length/clip_ratio:0.03125
timing_s/testing:24.9256
最终验证集 acc/mean@1 为 0.609375,最后一个 train batch 的 reward mean 为 0.75。和训练初期相比,step 48 的截断比例降到 0.03125,生成长度也明显变短。
TensorBoard 图表
在 TensorBoard 中,我们可以随时追踪训练参数:

score是规则函数给出的原始任务分数;在 GSM8K 里,回答的最终数字匹配标准答案就是1.0,否则是0.0。reward是真正送进 RL 更新的奖励。在当前配置里没有额外 reward shaping,也没有把 KL 放进 reward 里,所以 critic/rewards/mean 通常和 critic/score/mean 一样。如果以后加入长度惩罚、格式奖励、KL penalty 或 reward model,score 和 reward 就可能不一样。advantage是把 reward 转成策略更新信号后的结果。GRPO 会在同一个 prompt 的多条 response 之间做相对比较,答得更好的 response 得到正 advantage,答得差的得到负 advantage。图里critic/advantages/max经常到2.4749,critic/advantages/min经常到-2.4749,说明同组 response 之间存在明显的好坏差异,这正是 GRPO 可以利用的训练信号。return在 PPO/GAE 语境里通常表示累计回报;但这次没有启用 critic/GAE,reward 又是整条 response 级别的规则奖励,因此日志里的returns更接近训练内部复用的回报张量。
本次配置里 algorithm.use_kl_in_reward=False,也没有额外 reward shaping,所以 critic/score/mean 和 critic/rewards/mean 两条曲线完全重合。
algorithm.use_kl_in_reward=False表示 KL 不会作为惩罚项直接扣到 reward 里;KL 约束仍然可以通过 actor loss 中的actor/kl_loss生效。
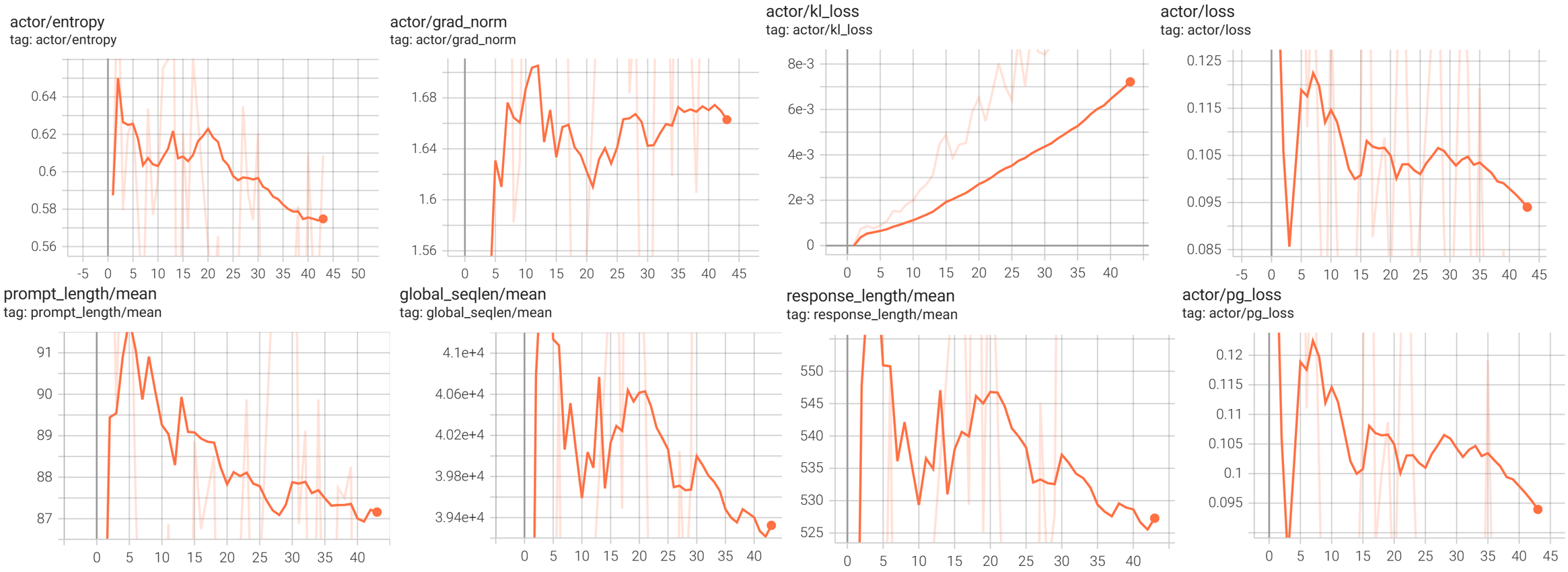
actor/pg_loss是 policy gradient 部分的 loss,直接对应 GRPO 用 advantage 推动策略更新的项;actor/kl_loss反映当前策略和参考策略的偏离程度。它在训练后段逐步变大,说明模型确实在离开初始策略;但数值仍然不高,结合前面的 clip 指标接近 0,可以看作这次更新比较保守。actor/loss是 actor 总 loss,包含 KL 正则等项。因为本次kl_coef=0.01,前期两条曲线几乎重合;随着actor/kl_loss从接近0增长到约0.018,两者后期会出现很小的差异。actor/entropy粗略反映输出分布的分散程度。原始数据里它大多在0.40到0.74之间波动,没有出现快速塌缩到很低的情况。actor/grad_norm用来看梯度是否异常。这里主要在1到2附近波动,最高约2.20,没有明显的梯度爆炸迹象。response_length/mean是每个 step 生成 response 的平均长度,本次大多在几百 token 范围内波动,平均约527。它会直接影响global_seqlen/mean和训练耗时。prompt_length/mean是输入 prompt 的平均长度,范围大致是74到110。相比 response 长度,它的变化小很多,因此本次总 token 量主要由 response 侧决定。global_seqlen/mean是每个 step 的总 token 规模,平均约3.9 万。
因为这次是单卡训练,
global_seqlen/min/max/mean和balanced_*曲线基本重合。多卡训练时,每张卡拿到的样本长度可能不同,global_seqlen/min/max/mean反映的是各个 rank 原始 token 负载的分布;如果max明显高于min,说明某些 rank 被更长的序列拖慢。balanced_*是做完 batch balance 之后的负载统计,用来观察重排后 token 是否更均匀;两者差距越小,通常说明跨卡负载越均衡。

ppl即 perplexity,计算上可以理解为exp(-平均 logprob)。同一批 token 上,perplexity 越低,表示模型给这些 token 的平均概率越高,也就是模型认为这些 token 越自然。rollout_corr/training_ppl是训练侧 actor 重新计算出来的 perplexity;rollout_corr/rollout_ppl是 rollout 侧 vLLM 记录的 perplexity。它们看的是同一批 response,只是来自两套执行路径。rollout_corr/ppl_ratio近似表示training_ppl / rollout_ppl。理想情况下它应该接近1;大于1表示训练侧认为这些 response 稍微更不自然,小于1则相反。rollout_corr/log_ppl_abs_diff是两边 log perplexity 的平均绝对差。理想情况下它应该接近0,比ppl_ratio更适合观察小量级差异。
training_ppl 的平均值约为 1.688,rollout_ppl 约为 1.687;ppl_ratio 的平均值约为 1.0005,log_ppl_abs_diff 平均约为 0.0012。这说明 vLLM rollout 侧和 actor 训练侧的概率计算整体很近,这是我们希望的。因为 rollout 负责生成样本,actor 负责用这些样本计算 logprob 和更新参数;如果两边对同一批 token 的概率判断差很多,训练就会变成在一个明显偏离的分布上做更新,importance ratio、KL 和 advantage 估计都可能变得不稳定。轻则表现为 loss、clip ratio、KL 曲线异常抖动,重则说明 rollout 权重同步、dtype/实现差异或异步滞后已经影响训练可信度。
这张图没有放
rollout_corr/kl、k3_kl、chi2_token、chi2_seq,但它们也是同一类一致性诊断。
kl直接估计E[log π_rollout - log π_training];k3_kl使用更稳定的小 KL 估计,形式近似为E[r - log(r) - 1],其中r = π_training / π_rollout;chi2_token = E[ρ_t^2] - 1看 token 级 importance weight 的方差;chi2_seq = E[(∏ρ_t)^2] - 1看整条 response 级别的累积差异。理想情况下,KL 和 χ² 相关指标也都应接近0。

val-core/openai/gsm8k/acc/mean@1是验证集上的最终答案准确率。这里每 12 step 验证一次,TensorBoard 中记录到 step 12、24、36,数值分别是0.5117、0.5352、0.5703,整体是上升的。val-aux/openai/gsm8k/reward/mean@1是验证集上的规则奖励均值。在 GSM8K 里,reward 主要来自最终答案是否匹配,所以它和acc/mean@1基本对齐;这次两条曲线的数值完全相同。timing_s/step是单个训练 step 的总耗时,包含生成、logprob 计算、ref 计算、advantage 计算、actor 更新、权重同步等阶段。本次记录到的平均 step 耗时约401s。timing_s/update_actor是 actor 参数更新耗时,也是当前主要瓶颈。原始数据里它平均约300s,占单 step 总耗时的大部分。
部署与推理
verl 训练保存下来的 actor checkpoint 通常是 FSDP 分片格式,不能直接当作普通 HuggingFace 模型目录交给 vLLM 或 Transformers 加载。因此部署前需要先把 checkpoint 合并成 HuggingFace 格式。这个步骤只是在整理权重格式,不会改变模型参数。
1
2
3
4
5
6
cd verl
python -m verl.model_merger merge \
--backend fsdp \
--local_dir ./outputs/qwen35_grpo/checkpoints/actor \
--target_dir ./models/qwen35-0.8b-gsm8k-grpo
合并完成后,可以分别部署原始模型和训练后模型。下面用 vLLM 的 OpenAI-compatible server,端口和 GPU 按实际机器调整即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 原始模型
CUDA_VISIBLE_DEVICES=0 vllm serve ./models/Qwen3.5-0.8B \
--served-model-name qwen35-0.8b-base \
--host 0.0.0.0 \
--port 8000 \
--dtype float16 \
--max-model-len 2048 \
--gpu-memory-utilization 0.65 \
--max-num-seqs 16 \
--limit-mm-per-prompt '{"image":0,"video":0}'
# 训练后模型
CUDA_VISIBLE_DEVICES=1 vllm serve ./models/qwen35-0.8b-gsm8k-grpo \
--served-model-name qwen35-0.8b-gsm8k-grpo \
--host 0.0.0.0 \
--port 8001 \
--dtype float16 \
--max-model-len 2048 \
--gpu-memory-utilization 0.65 \
--max-num-seqs 16 \
--limit-mm-per-prompt '{"image":0,"video":0}'
简单检查服务是否起来:
1
2
curl http://localhost:8000/v1/models
curl http://localhost:8001/v1/models
推理可以直接走 OpenAI 兼容接口。下面的脚本从处理后的 GSM8K parquet 中取出一条样本,用样本里的 chat prompt 调模型;替换 base_url 和 model 即可测试原始模型或训练后模型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import pandas as pd
from openai import OpenAI
DATA_FILE = "./data/gsm8k/test.parquet"
SAMPLE_INDEX = 18
MODEL_NAME = "qwen35-0.8b-gsm8k-grpo"
client = OpenAI(
base_url="http://localhost:8001/v1",
api_key="EMPTY",
)
df = pd.read_parquet(DATA_FILE)
row = df.iloc[SAMPLE_INDEX]
messages = row["prompt"].tolist()
gold = row["reward_model"]["ground_truth"]
resp = client.chat.completions.create(
model=MODEL_NAME,
messages=messages,
temperature=0,
max_tokens=512,
)
print("question:", row["extra_info"]["question"])
print("gold:", gold)
print()
print(resp.choices[0].message.content)
这个例子里,标准答案是 7。题目要求计算 4 周里一共吃了多少打鸡蛋:每天 3 个,4 周是 28 天,一共 3 * 28 = 84 个鸡蛋,84 / 12 = 7 打。
原始模型在这个样例上犯了中间推理错误:它把一周当成了 5 天,因此最终答案变成了 5。
1
2
3
4
5
6
There are 5 days in a week.
Eggs per week = 3 eggs/day * 5 days/week = 15 eggs/week.
Total eggs = 15 eggs/week * 4 weeks = 60 eggs.
Dozens = 60 / 12 = 5.
#### 5
训练后模型在同一道题上修正了这个步骤,先用 7 天计算每周鸡蛋数,再得到最终答案。
1
2
3
4
5
6
There are 7 days in a week.
Total eggs per week = 3 eggs/morning * 7 days = 21 eggs.
Total eggs in 4 weeks = 21 eggs/week * 4 weeks = 84 eggs.
Number of dozens = 84 / 12 = 7.
#### 7
实例:Memory-RL
memory 任务场景:模型把长输入压缩成 memory,再用这个 memory 去回答问题,reward 根据回答正确性、格式和压缩程度给分。这里参考 Mem-α 的思路,确认 data -> rollout -> memory server -> reward -> trainer log 链路跑通。
任务定义
把模型看成一个 memory writer。输入是一段包含若干标注样例的 context,模型需要输出一个固定结构的 memory JSON:
1
2
3
4
5
{
"core": "",
"semantic": [{"m1": "..."}],
"episodic": []
}
core / semantic / episodic 来自 Mem-α 的 memory 结构。
- 被训练的 memory writer 模型把 “Sentence -> Label” 这类映射写成紧凑记忆
- 随后 reward 函数把模型输出的 memory 发给 memory server
- memory server 根据问题检索/组织 memory,并调用 answer LLM 回答若干 label 查询题
- 回答越准,reward 越高;memory 紧凑,得到压缩奖励;JSON 格式合法,得到格式奖励。
数据
Mem-α 的公开数据里,每条样本通常包含 chunks、questions_and_answers、data_source 和 metadata。选了 NLU label 样本:
1
2
3
4
5
Sentence: what movie should i see
Label: 37
Sentence: will it rain on Saturday
Label: 9
转换成 verl 需要的 parquet 结构。一条样本如下:
prompt是模型真正看到的输入reward_model.ground_truth保存 reward 需要的标准问题和答案extra_info保存样本来源和调试信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
{
"data_source": "memalpha_nlu_memory_json",
"prompt": [
{
"role": "user",
"content": "You are a memory writer.\n\nRead the context and write compact memory JSON that helps answer future label questions.\nReturn only valid JSON with this exact schema:\n{\"core\":\"\",\"semantic\":[{\"m1\":\"...\"}],\"episodic\":[]}\n\nTarget mappings:\n- Sentence: what movie should i see -> Label: 37\n- Sentence: will it rain on Saturday -> Label: 9\n\nContext:\n..."
}
],
"ability": "memory",
"reward_model": {
"style": "rule",
"ground_truth": {
"questions_and_answers": [
{
"question": "Sentence: what movie should i see\nWhat are the labels for the above sentence?",
"answer": "37"
},
{
"question": "Sentence: will it rain on Saturday\nWhat are the labels for the above sentence?",
"answer": "9"
}
],
"source_chars": 2200
}
},
"extra_info": {
"split": "train",
"index": 0,
"memalpha_source": "icl_nlu_8296shot_balance",
"num_reward_questions": 2
}
}
奖励
这里有两个模型角色:
- 训练中的 Qwen3.5-0.8B 是 memory writer,负责把输入 context 写成 memory JSON
- answer LLM 由 memory server 调用,只负责基于给定 memory 回答验证问题
训练更新的是 memory writer,answer LLM 是固定服务。
评分编排放进了 custom reward worker,关于写记忆:先解析 memory writer 的输出,并规范成 Mem-α memory server 接受的 core / semantic / episodic 结构。这个阶段对应“写记忆”的质量检查,主要看 JSON 是否合法、memory 是否足够紧凑。
随后进入问答评分阶段:
- custom reward worker 把规范后的 memory 和 gold questions 发给 memory server
- memory server 根据问题检索/组织 memory prompt,再调用 answer LLM 生成答案
- custom reward worker 最后把 answer LLM 的答案和 gold answers 做 exact match,得到
answer_acc
原 Mem-α 代码中,这类 memory QA 调用也可以放在 rollout/generation 逻辑里;这里放进 custom reward worker 是新版 verl 接口适配方式。
分数由三部分组成:
1
score = answer_acc + 0.05 * format_score + 0.05 * compression_score
answer_acc是最主要的分数。如果有 3 个问题,全部答对就是1.0,答对 2 个就是0.6667。format_score判断模型输出能不能解析成合法 JSON object。compression_score = 1 - memory_chars / source_chars,并截断在[0, 1]。
例如一个样本有 3 个问题,answer LLM 基于 memory 全部答对,JSON 合法,memory 长度约为原文的 10%,最终分数大约是
1.095。如果只答对 1 个问题,即使 JSON 合法,分数也会明显下降。
memory server 的请求结构大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{
"memories": [
{
"core": "",
"semantic": [{"m1": "Sentence: what movie should i see Label: 37"}],
"episodic": []
}
],
"questions": [
["Sentence: what movie should i see\nWhat are the labels for the above sentence?"]
],
"max_tokens": 128,
"temperature": 0,
"enable_thinking": false
}
下载和配置
实验需要三部分:Mem-α 数据、Qwen3.5-0.8B 模型、verl 环境。
1
2
3
4
5
6
git clone --depth 1 https://github.com/wangyu-ustc/Mem-alpha.git
export VERL_DIR=/path/to/verl
export MODEL_PATH=/path/to/Qwen3.5-0.8B
export MEMALPHA_DIR=/path/to/Mem-alpha
export DATA_DIR=./data/memalpha_smoke
memory reward 需要两个服务。OpenAI-compatible answer server 负责生成答案;Mem-α memory server 负责接收 memory 和 questions,组织 memory prompt,并调用 answer server。
1
2
3
4
5
6
7
8
9
10
11
# answer server
CUDA_VISIBLE_DEVICES=0 vllm serve "$MODEL_PATH" \
--served-model-name qwen35-0.8b-memalpha \
--host 127.0.0.1 \
--port 18183 \
--dtype float16 \
--max-model-len 2048 \
--gpu-memory-utilization 0.55 \
--max-num-seqs 8 \
--enforce-eager \
--limit-mm-per-prompt '{"image":0,"video":0}'
1
2
3
4
5
6
7
8
9
10
11
# memory server
cd "$MEMALPHA_DIR"
export QWEN_URL=http://127.0.0.1:18183/v1
export QWEN_MODEL_NAME=qwen35-0.8b-memalpha
export QWEN_TOKENIZER_PATH="$MODEL_PATH"
export MEMALPHA_SERVER_MAX_TOKENS=128
export NO_PROXY=127.0.0.1,localhost
export no_proxy=127.0.0.1,localhost
python memory_server.py --port 5005
启动后可以检查:
1
2
curl -sS --noproxy 127.0.0.1 http://127.0.0.1:18183/health
curl -sS --noproxy 127.0.0.1 http://127.0.0.1:5005/health
训练
相关配置如下,对于测试性实验,相关设置很保守,只是确认跑通:
1
2
3
4
5
6
7
8
9
10
algorithm.adv_estimator=grpo
actor_rollout_ref.rollout.n=2
data.train_batch_size=1
data.max_prompt_length=2048
data.max_response_length=512
trainer.total_training_steps=2
reward.custom_reward_function.path=./memalpha_reward.py
reward.custom_reward_function.reward_kwargs.memory_server_url=http://127.0.0.1:5005/batch_process
actor_rollout_ref.model.use_remove_padding=False
actor_rollout_ref.rollout.enforce_eager=False
启动:
1
2
3
4
5
6
7
cd "$VERL_DIR"
ray stop --force || true
CUDA_VISIBLE_DEVICES=0 \
TOTAL_STEPS=2 \
ROLLOUT_N=2 \
bash ./scripts/run_qwen35_memalpha_smoke.sh
训练结束后,日志里应该能看到类似信息:
1
2
3
4
Training Progress: 100%|██████████| 2/2
training/global_step:2
critic/score/mean:0.0848
training/num_turns/mean:2.0
memory server 日志中也应该出现多次 /batch_process 请求。以 2 step × rollout.n=2 为例,训练期间至少应该看到 4 次 reward 调用。
整体链路可以概括为:verl dataloader 读入 memory writer 样本,Qwen3.5-0.8B rollout 生成 memory JSON,custom reward 调用 memory server 做 QA,trainer 记录分项指标并完成 GRPO 更新。
常见问题:Mem-α 代码适配
Mem-α 原仓库的训练脚本、rollout worker 和 vLLM 接口都比较旧。适配新版 verl 时,新增了三个文件,把旧数据、旧 memory server 和新版 main_ppo 接起来。
build_memalpha_nlu_smoke.py负责把 Mem-α parquet 转成新版 verl parquet。输入是 Mem-alpha/data/memalpha/train.parquet 和 test.parquet,输出是 train.parquet 和 test.parquet。核心改动是读取原始 row 里的 chunks,用正则抽取 Sentence: ... Label: ...,再生成 chat-style prompt、reward_model.ground_truth.questions_and_answers 和 extra_info。最小骨架如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
EXAMPLE_RE = re.compile(r"Sentence:\s*(.*?)\s+Label:\s*(\d+)", re.DOTALL)
def _record(row, split, out_idx):
chunks = json.loads(row["chunks"])
chunk = chunks[0][:chunk_limit]
examples = _extract_examples(chunk, qa_per_row)
qas = [
{
"question": f"Sentence: {x['sentence']}\nWhat are the labels for the above sentence?",
"answer": x["label"],
}
for x in examples
]
return {
"data_source": "memalpha_nlu_memory_json",
"prompt": [{"role": "user", "content": _make_prompt(chunk, examples)}],
"ability": "memory",
"reward_model": {
"style": "rule",
"ground_truth": {
"questions_and_answers": qas,
"source_chars": len(chunk),
},
},
"extra_info": {
"split": split,
"index": out_idx,
"memalpha_source": row["data_source"],
},
}
memalpha_reward.py负责把 memory writer 的输出接到 Mem-α memory server。关键函数是 compute_score(data_source, solution_str, ground_truth, extra_info, ...)。它先从 solution_str 里解析 JSON;解析失败时,把原始输出包装成一条 semantic memory,并把 format_score 记为 0;然后把 semantic / episodic 规范成 single-key dict list;最后请求 /batch_process,用 answer LLM 的回答算 answer_acc。最小骨架如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def compute_score(data_source, solution_str, ground_truth, extra_info=None,
memory_server_url="http://127.0.0.1:5005/batch_process",
max_tokens=128, timeout=90):
qas = list(ground_truth["questions_and_answers"])
source_chars = max(int(ground_truth.get("source_chars", 1)), 1)
raw_memory, format_score = _parse_memory(solution_str)
memory, memory_chars = _normalize_memory(raw_memory)
response = requests.post(
memory_server_url,
json={
"memories": [memory],
"questions": [[qa["question"] for qa in qas]],
"max_tokens": max_tokens,
"temperature": 0,
"enable_thinking": False,
},
timeout=timeout,
)
predictions = response.json()["result"][0]
answer_acc = _score_answers(predictions, qas)
compression_score = max(0.0, min(1.0, 1.0 - memory_chars / source_chars))
return {
"score": answer_acc + 0.05 * format_score + 0.05 * compression_score,
"memalpha_acc": answer_acc,
"memalpha_format": format_score,
"memalpha_compression": compression_score,
}
run_qwen35_memalpha_modern_smoke.sh负责把新版 verl 的 Hydra 配置写清楚。需要暴露几个路径变量:VERL_DIR、MODEL_PATH、TRAIN_FILE、TEST_FILE、REWARD_FILE、CKPTS_DIR。核心配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
DATA=(
algorithm.adv_estimator=grpo
data.train_files="${TRAIN_FILE}"
data.val_files="${TEST_FILE}"
data.train_batch_size=1
data.max_prompt_length=2048
data.max_response_length=512
)
ROLLOUT=(
actor_rollout_ref.rollout.name=vllm
actor_rollout_ref.rollout.n=${ROLLOUT_N}
actor_rollout_ref.rollout.max_model_len=3072
actor_rollout_ref.rollout.max_num_seqs=4
actor_rollout_ref.rollout.free_cache_engine=True
actor_rollout_ref.rollout.enforce_eager=False
)
TRAINER=(
trainer.total_training_steps=${TOTAL_STEPS}
reward.custom_reward_function.path="${REWARD_FILE}"
reward.custom_reward_function.name=compute_score
+reward.custom_reward_function.reward_kwargs.memory_server_url=http://127.0.0.1:5005/batch_process
)
这三个文件之外,原 Mem-α 仓库里主要看三个位置。
memalpha/llm_agent/generation.py说明原方法如何多 chunk 写 memory、调用 memory server QA、收集预测答案和 memory state;memory_server.py说明/batch_process的 payload、memory prompt 构造、BM25 过滤和 answer LLM 调用- 原训练脚本说明
rollout.n、compression/content reward 权重、max prompt/response length 等实验参数。完整迁移时保留这些语义,替换文件签名、配置写法、HTTP payload 校验和新版 verl 接口即可。
实例:多轮工具调用
模型在同一条 trajectory 里多次调用工具,工具读取或修改 per-sample state,trainer 记录 tool reward、最终回答 reward 和 actor update。
实验采用新版 verl 内置的 vLLM async + tool_agent + BaseTool 路线,目标是跑通 data -> vLLM async rollout -> ToolAgentLoop -> BaseTool -> reward -> actor update。
任务定义
每条样本带一个临时 memory store,模型必须先调用 search_memory 找到候选记忆,再调用 read_memory 读取目标记忆,最后用 FINAL: ... 给出答案。工具协议采用 Qwen3.5 chat template 可解析的 XML tool call,由 actor_rollout_ref.rollout.multi_turn.format=qwen3_coder 负责解析。
每条 rollout 都有独立的 request_id。工具内部根据 request_id 维护 memory store,避免不同样本之间串状态。
实现思路
新版实现直接使用当前 verl 的内置接口:ToolAgentLoop 管多轮 rollout,BaseTool 管工具生命周期,tool_config.yaml 注册工具,custom reward 负责把工具分和最终答案分合成训练分数。工具状态不放在外部 tool server,而是从每条样本的 tools_kwargs 初始化,并用 agent_data.request_id 做 per-rollout 隔离。
代码放在一个独立目录,例如:
1
2
3
4
5
6
tmp/verl_modern_memory_tool_smoke/
memory_tools.py
tool_config.yaml
build_data.py
reward.py
run_qwen35_modern_memory_tool_smoke.sh
每个文件的职责如下:
memory_tools.py:定义search_memory和read_memory两个 nativeBaseTooltool_config.yaml:注册工具类、函数 schema 和 native tool 类型build_data.py:生成 train/test parquet,并在extra_info.tools_kwargs里放入每条样本的 memory storereward.py:读取 tool reward 和最终回答,计算规则分数run_qwen35_modern_memory_tool_smoke.sh:生成数据、设置PYTHONPATH、调用verl.trainer.main_ppo
工具实现
memory_tools.py 定义两个工具。search_memory(query) 返回候选 memory id;read_memory(memory_id) 返回 memory text。工具状态来自样本里的 extra_info.tools_kwargs.<tool_name>.create_kwargs,并通过 agent_data.request_id 做 per-rollout 隔离。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from verl.tools.base_tool import BaseTool, ToolResponse
def _ensure_store(agent_data, tool_name):
request_id = getattr(agent_data, "request_id", "default")
stores = agent_data.extra_fields.setdefault("memory_stores", {})
if request_id not in stores:
cfg = agent_data.tools_kwargs.get(tool_name, {}).get("create_kwargs", {})
stores[request_id] = {
"memories": cfg.get("memories", []),
"target_id": cfg.get("target_id", ""),
"target_answer": cfg.get("target_answer", ""),
"calls": [],
}
return stores[request_id]
class SearchMemoryTool(BaseTool):
async def execute(self, instance_id, parameters, **kwargs):
agent_data = kwargs["agent_data"]
store = _ensure_store(agent_data, "search_memory")
query = str(parameters.get("query", "")).strip().lower()
hits = [m["id"] for m in store["memories"] if query and query in m["text"].lower()]
if not hits:
hits = [m["id"] for m in store["memories"][:2]]
store["calls"].append({"tool": "search_memory", "query": query, "hits": hits})
return ToolResponse(text=str(hits)), 0.25 if query else 0.0, {}
class ReadMemoryTool(BaseTool):
async def execute(self, instance_id, parameters, **kwargs):
agent_data = kwargs["agent_data"]
store = _ensure_store(agent_data, "read_memory")
memory_id = str(parameters.get("memory_id", "")).strip()
text = next((m["text"] for m in store["memories"] if m["id"] == memory_id), "")
reward = 0.75 if memory_id == store["target_id"] else 0.0
store["calls"].append({"tool": "read_memory", "memory_id": memory_id, "reward": reward})
return ToolResponse(text=text or "NOT_FOUND"), reward, {}
tool_config.yaml 注册工具类、工具 schema 和 native tool 类型。class_name 要能被训练进程 import 到,所以运行脚本里需要把 smoke 目录加入 PYTHONPATH。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
tools:
- class_name: memory_tools.SearchMemoryTool
config:
type: native
tool_schema:
type: function
function:
name: search_memory
description: Search user memory and return candidate memory ids.
parameters:
type: object
properties:
query:
type: string
required: [query]
- class_name: memory_tools.ReadMemoryTool
config:
type: native
tool_schema:
type: function
function:
name: read_memory
description: Read one memory by id.
parameters:
type: object
properties:
memory_id:
type: string
required: [memory_id]
数据
build_data.py 生成 train/test parquet。关键字段是 agent_name="tool_agent"、extra_info.need_tools_kwargs=True 和 extra_info.tools_kwargs。tools_kwargs 把每条样本的初始 memory、目标 memory id、目标答案注入工具。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
{
"data_source": "memory_tool_smoke",
"agent_name": "tool_agent",
"prompt": [
{
"role": "system",
"content": "You are a memory-using assistant. Use tools before answering.",
},
{
"role": "user",
"content": "Question: Which tea should be prepared for this user?\nSearch hint: tea preference\nUse the memory tools.",
},
],
"ability": "memory_tool",
"reward_model": {
"style": "rule",
"ground_truth": {
"target_answer": "jasmine green tea",
"target_id": "mem_tea",
},
},
"extra_info": {
"need_tools_kwargs": True,
"target_answer": "jasmine green tea",
"tools_kwargs": {
"search_memory": {
"create_kwargs": {
"memories": [
{"id": "mem_tea", "text": "The user prefers jasmine green tea for late afternoon breaks."},
{"id": "mem_music", "text": "The user likes quiet instrumental music when reading."},
],
"target_id": "mem_tea",
"target_answer": "jasmine green tea",
}
},
"read_memory": {
"create_kwargs": {
"memories": "...same as search_memory...",
"target_id": "mem_tea",
"target_answer": "jasmine green tea",
}
},
},
},
}
生成数据:
1
2
python tmp/verl_modern_memory_tool_smoke/build_data.py \
--output-dir tmp/verl_modern_memory_tool_smoke/data
奖励
reward.py 从 ToolAgentLoop 写入的 extra_info.tool_rewards 读取工具分,再检查最终回答是否包含 gold answer,以及是否出现 FINAL:。
1
2
3
4
5
6
7
8
def compute_score(data_source, solution_str, ground_truth, extra_info=None, **kwargs):
extra_info = extra_info or {}
target = str(ground_truth.get("target_answer", "")).lower()
response = str(solution_str)
tool_reward = min(sum(float(x) for x in extra_info.get("tool_rewards", [])), 1.0)
answer_reward = 1.0 if target and target in response.lower() else 0.0
format_reward = 0.25 if "FINAL:" in response else 0.0
return tool_reward + answer_reward + format_reward
满分是 2.25:工具调用最多 1.0,最终答案 1.0,FINAL: 格式 0.25。这个 reward 只用于 smoke,重点是确认 tool reward、answer reward 和格式 reward 都能进入训练指标。
下载和配置
依赖包括三部分:新版 verl 环境、Qwen3.5-0.8B 模型、smoke 脚本目录。模型可以使用本地 HuggingFace 格式目录,脚本通过 MODEL_PATH 指定:
1
2
3
export VERL_DIR=/path/to/verl
export MODEL_PATH=/path/to/Qwen3.5-0.8B
export SMOKE_DIR=tmp/verl_modern_memory_tool_smoke
运行前需要让训练进程能 import 到 memory_tools.py:
1
export PYTHONPATH="${SMOKE_DIR}:${VERL_DIR}:${PYTHONPATH:-}"
run_qwen35_modern_memory_tool_smoke.sh 的核心 Hydra 覆盖如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
algorithm.adv_estimator=grpo
data.train_files="${TRAIN_FILE}"
data.val_files="${TEST_FILE}"
data.train_batch_size=4
data.max_prompt_length=1024
data.max_response_length=512
actor_rollout_ref.rollout.name=vllm
actor_rollout_ref.rollout.mode=async
actor_rollout_ref.rollout.n=2
actor_rollout_ref.rollout.multi_turn.enable=True
actor_rollout_ref.rollout.multi_turn.tool_config_path="${TOOL_CONFIG}"
actor_rollout_ref.rollout.multi_turn.format=qwen3_coder
actor_rollout_ref.rollout.multi_turn.max_user_turns=2
actor_rollout_ref.rollout.multi_turn.max_assistant_turns=3
actor_rollout_ref.rollout.agent.default_agent_loop=tool_agent
reward.custom_reward_function.path="${REWARD_FILE}"
reward.custom_reward_function.name=compute_score
trainer.total_training_steps=2
trainer.n_gpus_per_node=2
训练
两卡运行命令如下,<repo>、<verl_env>、<model_dir> 替换为自己的路径:
1
2
3
4
5
6
cd <repo>
<verl_env>/bin/ray stop --force || true
MODEL_PATH=<model_dir>/Qwen3.5-0.8B \
CUDA_VISIBLE_DEVICES=0,1 \
bash tmp/verl_modern_memory_tool_smoke/run_qwen35_modern_memory_tool_smoke.sh
用 screen 跑后台任务:
1
2
3
4
5
6
7
8
9
10
11
cd <repo>
RUN_TAG="modern_memory_tool_$(date +%Y%m%d_%H%M%S)"
screen -dmS "$RUN_TAG" \
-L -Logfile "tmp/logs/${RUN_TAG}.screen.log" \
bash -lc '
cd <repo>
MODEL_PATH=<model_dir>/Qwen3.5-0.8B \
CUDA_VISIBLE_DEVICES=0,1 \
bash tmp/verl_modern_memory_tool_smoke/run_qwen35_modern_memory_tool_smoke.sh
'
结果
完成 2/2 training steps。日志里可以看到多轮工具调用、非零 reward 和 actor update:
1
2
3
4
5
6
7
8
9
10
11
12
Training Progress: 100%|██████████| 2/2
training/global_step:1
critic/score/mean:2.1875
critic/score/max:2.25
critic/score/min:2.0
training/num_turns/mean:6.0
training/global_step:2
critic/score/mean:2.25
critic/score/max:2.25
critic/score/min:2.25
training/num_turns/mean:6.0
training/num_turns/mean=6.0 对应 user -> assistant tool_call -> tool -> assistant tool_call -> tool -> assistant final。第 2 step 的 critic/score/mean=2.25 达到本 toy reward 满分,说明工具分、答案分和格式分都进入了训练指标。
常见问题:verl-tool 代码适配
旧 TIGER-AI-Lab/verl-tool 可以参考:Search-R1 风格的 tool server、trajectory state、tool metrics 和 reward worker。问题在于该仓库和当前 verl / vLLM 接口差异较多,直接跑会遇到旧 async rollout、ZeroMQ/AsyncLLM、Ray placement、Qwen chat template 等兼容点。旧代码适配可以作为工程参考,长期原型更适合使用上一节的新版 ToolAgentLoop + BaseTool 路线。
旧 verl-tool smoke 中主要新增或修改这些文件:
verl_tool/servers/tools/memory_sandbox.py:新增 toy tool。继承BaseTool,实现parse_action()和conduct_action(),解析<write_memory>、<read_memory>、<answer>三类标签。write_memory写入BaseTool.env_cache里的 per-trajectory memory,read_memory返回 observation,answer读取extra_field["target"]做 exact match 并结束 trajectory。复制时重点保留trajectory_id -> env的隔离逻辑。build_memory_tool_smoke_data.py:生成verl-tool训练数据。每条样本至少包含prompt、ability、reward_model.ground_truth.target、extra_info.target。extra_info.target会被 tool server 的answer分支读取,用来计算最终 outcome reward。复制时重点检查 parquet 里的prompt是否是 chat message list,target是否同时写进reward_model和extra_info。action_stop_tokens.txt:写入</write_memory>,</read_memory>,</answer>。旧verl-toolagent loop 依靠这些 stop tokens 切分 action;缺少这个文件时,模型可能把多个动作和最终答案一次性生成,tool server 收不到干净 action。run_qwen35_memory_tool_smoke.sh:整理训练命令。关键配置包括actor_rollout_ref.agent.enable_agent=True、actor_rollout_ref.agent.tool_server_url=http://127.0.0.1:<port>/get_observation、actor_rollout_ref.agent.action_stop_tokens=<path>、actor_rollout_ref.agent.max_turns=3、actor_rollout_ref.rollout.n=2、trainer.total_training_steps=2。复制时先用 2 step 验证链路,再扩大 batch 和 step。verl_tool/agent_loop/verltool_agent_loop.py:给 Qwen3.5 chat template 缺失的mtrl_sep做 fallback。旧代码假设 tokenizer/chat template 里存在mtrl_sep,Qwen3.5 可能没有该字段,结果是 prompt 拼接或 action 分隔失败。处理方式是在读取不到mtrl_sep时使用明确的默认分隔符,并保证 stop tokens 与工具标签一致。verl_tool/workers/rollout/vllm_rollout/vllm_async_server.py:适配新版 vLLM 的 async rollout 接口。旧代码会显式走vllm.v1.engine.async_llm.AsyncLLM和 ZeroMQ 连接路径,在新版 vLLM 上容易启动后第一次 generate 崩溃。smoke 里曾增加本地vllm.LLM(...)分支绕过该问题;这个分支只适合验证 tool server 和 reward 链路,正式训练应回到 verl 官方 rollout 后端,避免破坏权重同步语义。
旧 verl-tool 适配时需要保留的语义是 multi-turn tool rollout、per-sample environment state、tool observation、trajectory metrics 和最终 reward。可替换的是旧 async rollout 后端、ZeroMQ 连接细节、Qwen template 兼容 shim 和 toy tool 的具体动作协议。