智库慧询:通过与微调大模型对话完成数据库分析
感谢同小组的 ZYH 同学和 ZWC 同学,他们为项目做的贡献比我多
数据是互联网产业的血脉,全球数据分析市场预计将在未来五年内以每年20%的速度增长。但是传统的SQL语句语句构建费时费力,同时还需要数据分析师的参与。希望通过与微调大模型对话,自动完成SQL语句生成、统计图表绘制、数据分析的一系列工作。
整体思路如下:
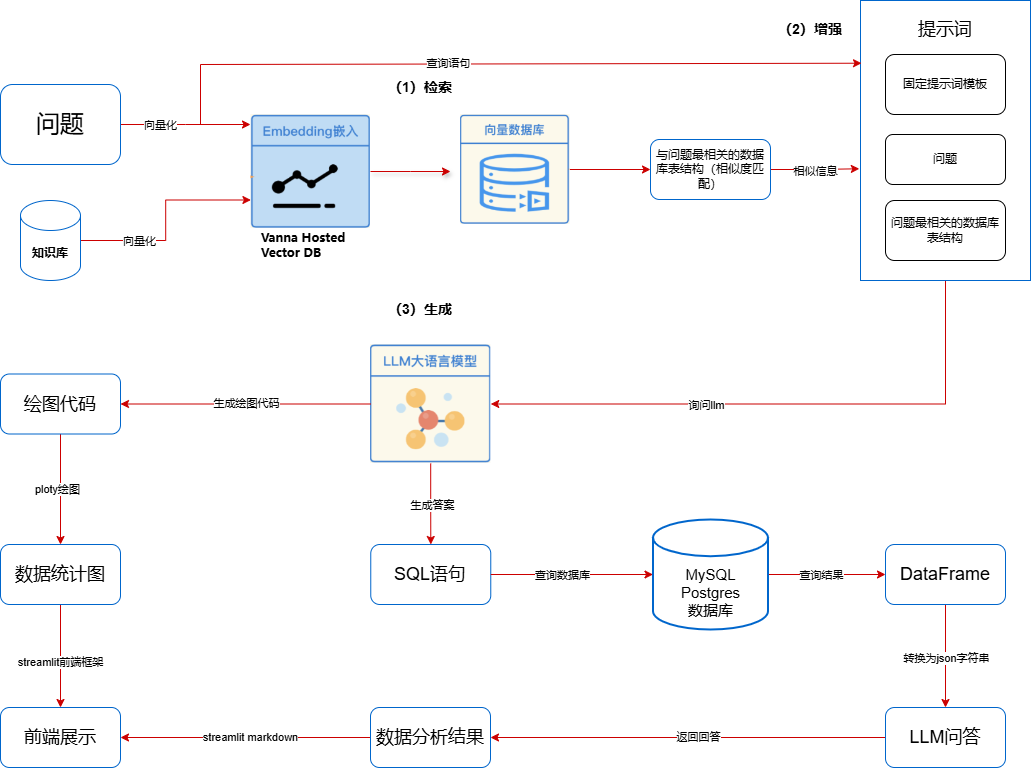
最终完成的界面:进入系统,自动根据数据库生成数据图表
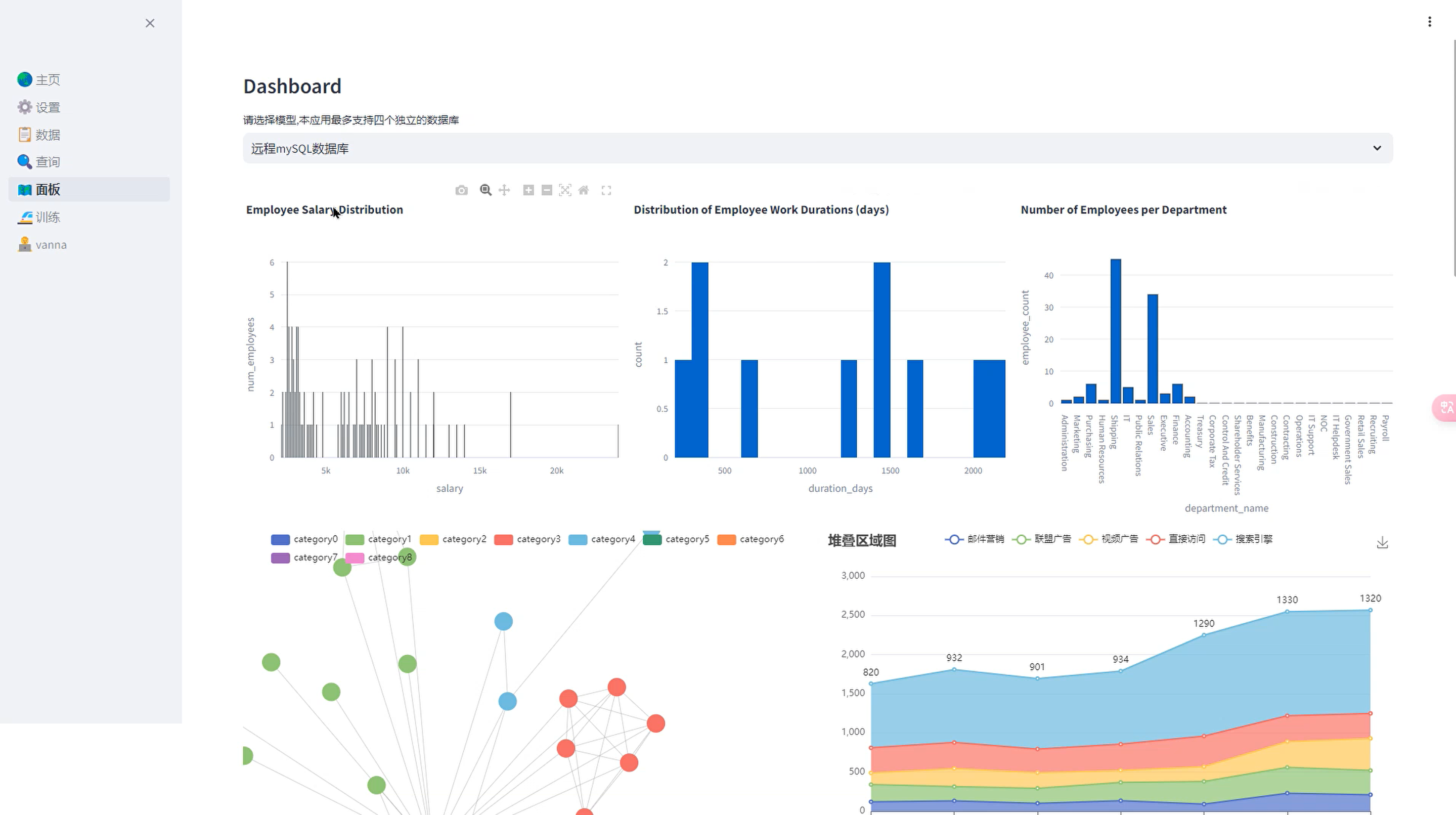
通过对话自动完成数据库分析,每个人都是数据分析师!
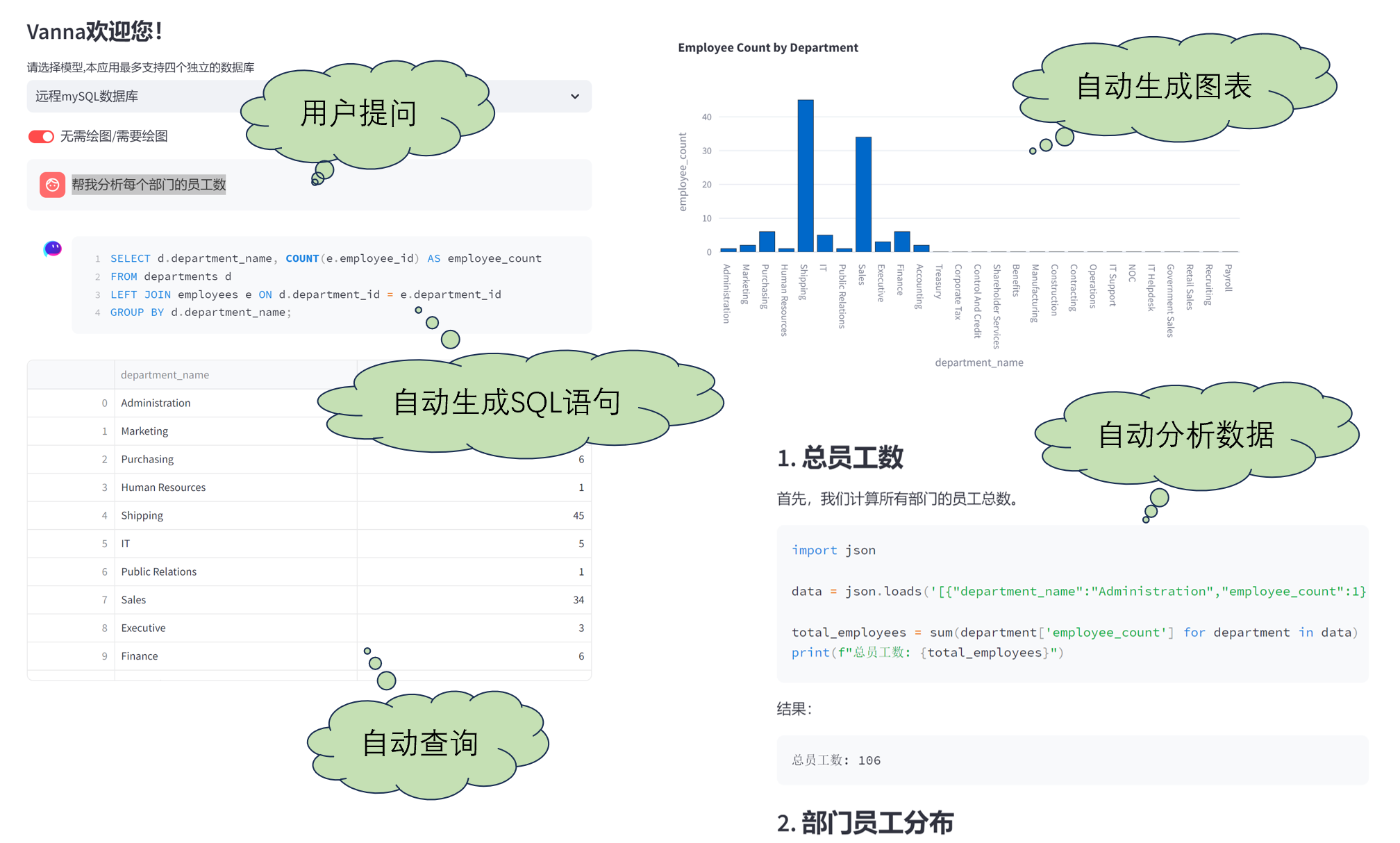
核心服务:
- 自动化SQL查询生成:通过先进的自然语言处理技术,用户只需输入查询需求,系统即可自动生成高效精准的SQL语句。
- 数据分析与可视化:平台内置多种数据分析工具和图表组件,用户可以轻松实现数据分析结果的可视化展示,支持柱状图、饼图、折线图等多种图表形式。
- 多数据库支持:平台兼容多种主流数据库,如MySQL、PostgreSQL、SQL Server等,用户可以无缝连接不同数据源。
- 自定义报表生成:用户可以根据自身需求,自定义生成各类数据报表,满足不同业务场景的需求。
- 实时数据监控:平台提供实时数据监控和预警功能,帮助用户及时发现和解决数据异常问题。
- 同时,我们的项目使用了开源的ChatGLM-6B作为生成模型,对其针对spider数据集进行了微调,各项指标表现良好,查询正确率高,分析准确。
ChatGLM3
微调选用了ChatGLM3-6B开源模型,是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
在使用中,确实能做到快速的安装部署,而且仅仅通过简单调整就可以在自己的数据集上进行微调。
ChatGLM3和GLM模型背后的技术在这里不再赘述,可以参考博客
微调ChatGLM3-6B
微调的主要目的是通过在特定任务上对预训练模型进行进一步训练,以适应该任务的需求,从而提高模型在该任务上的性能。
ChatGLM3-6B开源模型几种微调方式如下,我们使用了LoRA微调技术。
| 微调方法 | 名称 | GPU占用 | 备注 |
|---|---|---|---|
| LoRA | 低(秩)rank 自适应微调方法 | 14082MiB 显存预计14GB | |
| SFT全量微调 | 全参微调,一般结合:Accelerator和DeepSpeed框架 | 4张显卡平均分配,每张显卡占用 48346MiB 显存大约是195GB | 优点:全面全参微调效最效果比较好 缺点:计算量太大及资用太大 |
| P-TuningV2 | 更改传递的提示的嵌入以更好地表示任务 | 微调: 1张显卡,占用 18426MiB 显存,大约19GB内 |
各种微调方法的原理这里不再赘述,可以参考博客
支持的模型精度如下,我们选择的是:默认16-bit
| 精度 | 说明 | 备注 |
|---|---|---|
| 32bit | 32 比特全参数微调 | 效果好,计算量大 |
| FP16 | 16 比特冻结微调 | 或基于AQLM/AWQ/GPTQ/LLM.int8 |
| 8-bit | 8比特 | 用于运行 |
| 4-bit | 4比特 | 用于运行 |
具体的微调步骤参考GitHub文档,主要做的工作包括创建微调数据集和运行微调代码。
关于LoRA微调了哪些部分的参数,在微调代码中,这部分内容被包装在Hugging Face 提供的CausalLM相关的类的方法中,一般来说,微调的是自注意力的QKV部分,也可以手动打印模型信息看哪些部分加入了lora_A和lora_B:
1
2
3
model = AutoModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
for name, param in model.named_parameters():
print(name, param.shape)
1
2
3
4
5
6
7
8
9
10
11
12
model.decoder.layers.23.self_attn.k_proj.weight torch.Size([1024, 1024])
model.decoder.layers.23.self_attn.k_proj.bias torch.Size([1024])
model.decoder.layers.23.self_attn.v_proj.base_layer.weight torch.Size([1024, 1024])
model.decoder.layers.23.self_attn.v_proj.base_layer.bias torch.Size([1024])
model.decoder.layers.23.self_attn.v_proj.lora_A.default.weight torch.Size([16, 1024])
model.decoder.layers.23.self_attn.v_proj.lora_B.default.weight torch.Size([1024, 16])
model.decoder.layers.23.self_attn.q_proj.base_layer.weight torch.Size([1024, 1024])
model.decoder.layers.23.self_attn.q_proj.base_layer.bias torch.Size([1024])
model.decoder.layers.23.self_attn.q_proj.lora_A.default.weight torch.Size([16, 1024])
model.decoder.layers.23.self_attn.q_proj.lora_B.default.weight torch.Size([1024, 16])
model.decoder.layers.23.self_attn.out_proj.weight torch.Size([1024, 1024])
model.decoder.layers.23.self_attn.out_proj.bias torch.Size([1024])
数据集方面,我们选用Spider,它是一个由11名大学生标注的大规模、复杂且跨领域的语义解析和文本到SQL的数据集。该数据集包含10,181个问题和5,693个独特的复杂SQL查询,涵盖了200个具有多个表的数据库,在138个不同领域中进行了标注,平均每个数据库由 27.6 个 columns 和 8.8 个外键。
具体来说,我们从Spider数据集中的约6000个样本中提取问题文本和SQL查询代码,并插入到设计好的问答模板中,得到约6000个微调样本,转换为json格式数据并按照官方给的格式进行排列,得到train.json和dev.json存放到服务器的data目录。其中训练集数据大约有5400条,测试集有600条。
问答模板如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
user:
Your response should ONLY be based on the given context and follow the response guidelines and format instructions.
===Tables
{Spider提取的问题对应数据库的定义语言}
===Response Guidelines
1. If the provided context is sufficient, please generate a valid SQL query without any explanations for the question.
2. If the provided context is almost sufficient but requires knowledge of a specific string in a particular column, please generate an intermediate SQL query to find the distinct strings in that column. Prepend the query with a comment saying intermediate_sql
3. If the provided context is insufficient, please explain why it can't be generated.
4. Please use the most relevant table(s).
5. If the question has been asked and answered before, please repeat the answer exactly as it was given before.
===Question
{Spider提取的问题}
assistant:
{Spider提取的SQL回答}
微调结果如下:
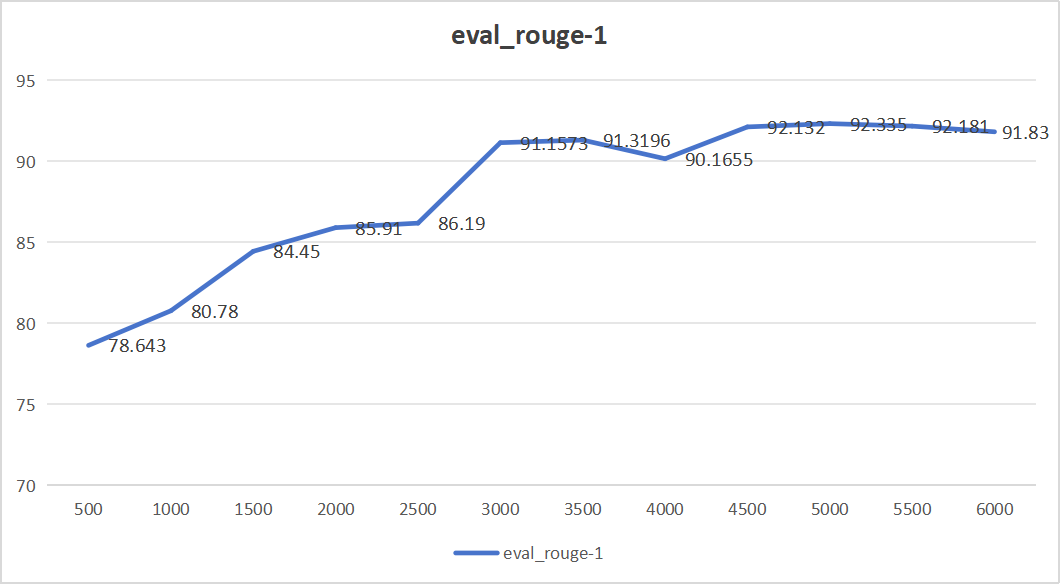
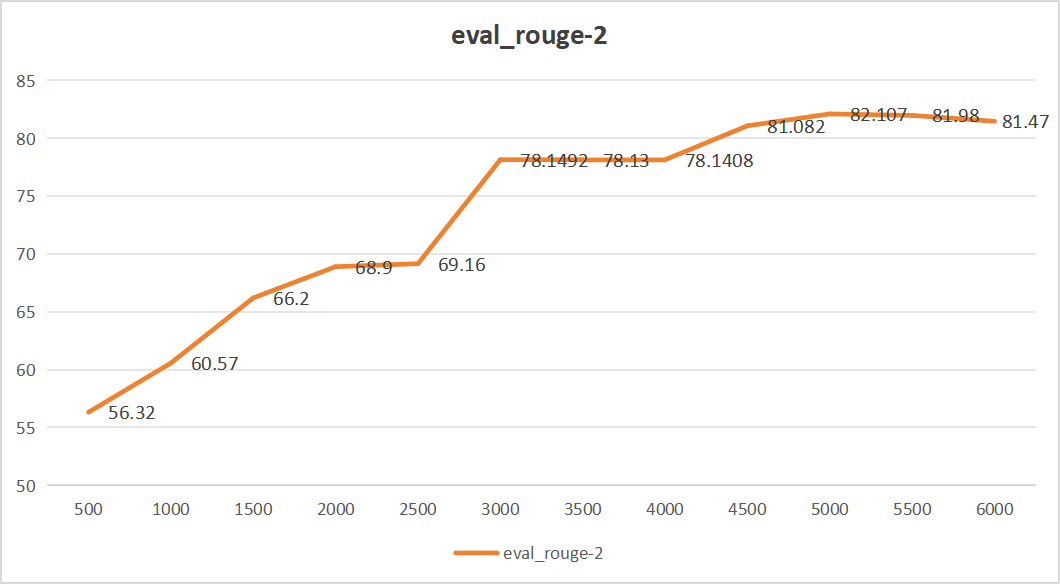
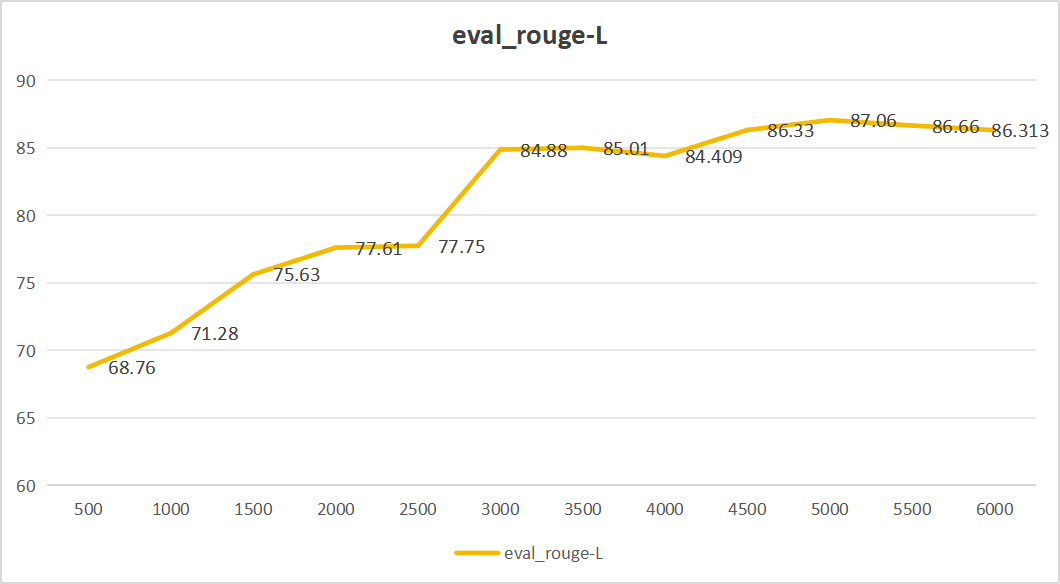
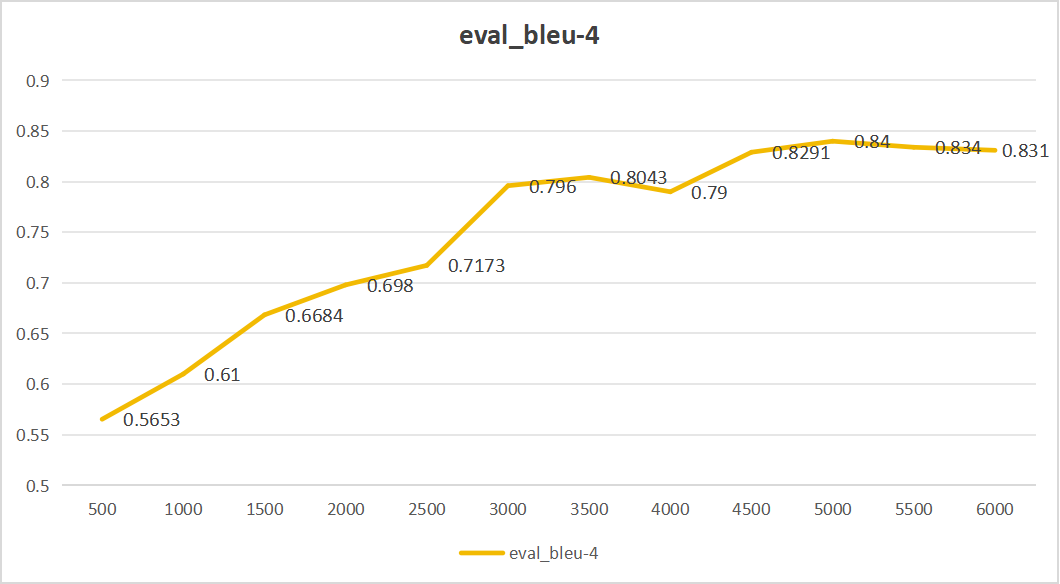
- ROUGE-1是一种评价文本生成任务的指标,用于衡量生成文本和参考文本之间的重叠程度,特别是单个词的重叠。值越高,表示生成的文本与参考文本更相似。
- ROUGE-2衡量的是生成文本和参考文本之间的二元组(即连续两个词)的重叠程度。同样,值越高,表示生成的文本质量更好。
- ROUGE-L基于最长公共子序列(Longest Common Subsequence, LCS)来评价生成文本和参考文本之间的相似度。它捕捉了生成文本和参考文本之间较长的匹配序列。值越高,表示生成的文本与参考文本更接近。
- BLEU-4是另一种常用于评估机器翻译和文本生成任务的指标,特别是四元组(即连续四个词)的重叠程度。值在0到1之间,越接近1越好,表示生成的文本与参考文本更相似。
文本生成评估指标的更多参考见博客
从上面四个图中,我们可以看出,大模型步长为5000的时候,效果最好,生成的内容与真实答案相似程度最高。eval_rouge-1达到92.335、eval_rouge-2达到82.107、eval_rouge-L达到87.06、eval_bleu-4达到0.84。同时最后平均损失仅为0.158。
其他微调细节:
- 损失函数:基于语言模型的交叉熵损失函数
- 优化器:Adam
- 正则化:权重衰减,dropout,残差连接,层归一化(LayerNorm),输入规范化(Input Normalization),分布式训练(Distributed Training),混合精度训练(Mixed Precision Training),知识蒸馏(Knowledge Distillation)
- 参数量:微调的参数量约195万;全部参数量6亿
- 参数初始化:使用ChatGLM3-6B预训练的参数,LoRA_A部分是正态分布,LoRA_B部分初始化为0
- 样本量:6000条左右
- 数据集大小:16MB左右
- GPU:RTX4090
- 显存消耗:24GB
- 训练时间:30min
- 精度:默认16-bit
ChatGPT-4o
因为要实现通过对话完成数据库分析,只有一个会生成SQL语句的大模型肯定是不够的,对于不需要生成SQL语句的普通问答,调用了ChatGPT-4o来回答,当然,也设计了一个简单的模板来让它更好地充当数据分析师的角色。
1
2
3
4
5
6
7
8
9
10
你是一个杰出的数据分析师和引导者,请回答客户的问题,并遵循以下原则
===原则===
1.如果客户问你使用了什么模型,请回答ChatGLM3-6B
2.请引导客户往能提供数据分析的方向提问
3.如果客户问了你是谁,请回答你是一个杰出的数据分析师
4.如果涉及到数据库相关问题,请根据数据库DDL进行回答
===数据库DDL===
{定义语句}
===问题===
{用户问题}
1
你是一个杰出的数据分析师,你的客户希望你帮助他们分析数据库的查询结果,找出数据中的深层联系和信息,注意在分析时不要给出代码,请根据以下的json数据进行分析:json:{}
第一个模板的第一条原则令人忍俊不禁
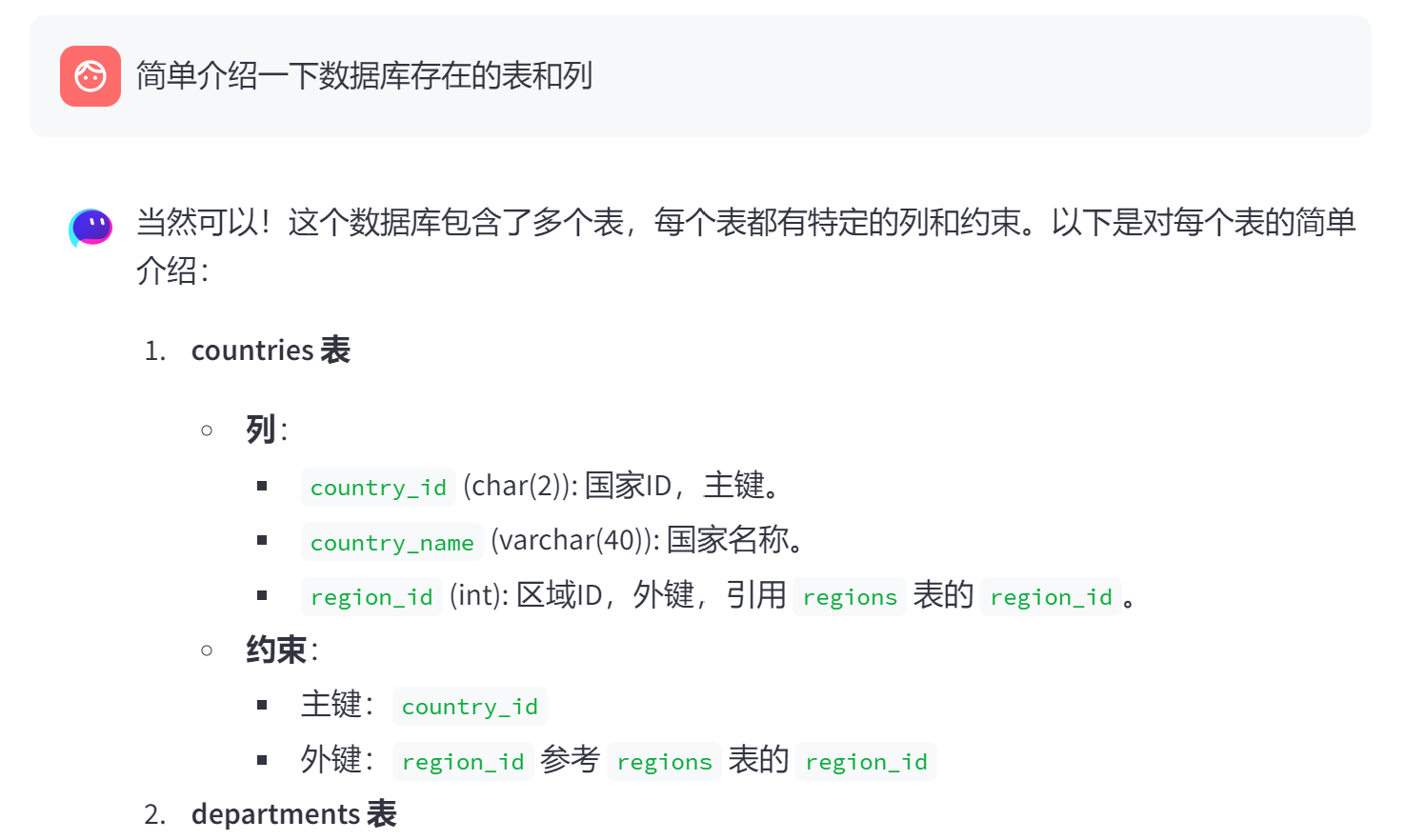
来看一些回答例子:

前端框架
使用了 Streamlit 开发前端。它是一个用于创建数据科学和机器学习应用程序的开源 Python 库。它有一套方便复用的前端组件,主要目标是使开发人员能够以简单的方式快速构建交互式的数据应用,而无需过多的前端开发经验。而且这些应用程序可以很方便地部署到网站上。
Streamlit 提供了一种简单的方法来转换数据脚本或分析代码为具有可视化界面的应用程序。总体来说是由上到下,随着python代码运行,每调用一个方法就可以在页面上添加一个组件。
举个例子:
1
2
3
4
5
6
7
8
9
10
append_message(AIMessage(content=sql)) # 在页面上展示生成的SQL语句
append_message(data_frame(input_df=df)) # 在页面上展示查询结果
if activate == 1: # 如果需要绘图
code = vn.generate_plotly_code(question=question, sql=sql, df=df)
fig = vn.get_plotly_figure(plotly_code=code, df=df)
append_message(plot_figure(input_figure=fig)) # 在页面上展示图像
analysis = generate_analysis(json_data)
append_message(SystemMessage(content=analysis)) # 在页面上展示分析结果
此外,在代码中也使用到了vanna,它是基于检索增强(RAG)的sql生成框架,会先用向量数据库将待查询数据库的建表语句、文档、常用SQL及其自然语言查询问题存储起来。在用户发起查询请求时,会先从向量数据库中检索出相关的建表语句、文档、SQL问答对放入到prompt里(DDL和文档作为上下文、SQL问答对作为few-shot样例),LLM根据prompt生成查询SQL并执行,框架会进一步将查询结果使用plotly可视化出来或用LLM生成后续问题。如果用户反馈LLM生成的结果是正确的,可以将这一问答对存储到向量数据库,可以使得以后的生成结果更准确。