LLM评估概述
从整体上可以将大语言模型评估分为三个大的方面:
- 知识与能力
- 伦理与安全
- 垂直领域评估
知识与能力
大语言模型具有丰富的知识和解决多种任务的能力,包括:
- 自然语言理解(例如:文本分类、信 息抽取、情感分析、语义匹配等)
- 知识问答(例如:阅读理解、开放领域问题等)
- 自然语言生成 (例如:机器翻译、文本摘要、文本创作等)
- 逻辑推理(例如:数学解题、文本蕴含)
- 代码生成等
知识与能力评测体系的构建主要可以分为两大类:一类是以任务为核心,另一类是以人为核心。
任务为核心的评估体系
HELM 评测构造了 42 类评测场景(Scenario),将场景进行分类,基于以下三个方面:
- 任务(例如问答、摘要),用于描述评测的功能
- 领域(例如维基百科 2018 年的数据集),用于描述评测哪种类型的数据;进一步将领域细分为文本属 性(什么内容)、说话者属性(谁说的)和时间/情境属性(何时何地)
- 语言或语言变体(例如西班牙语)

场景示例包括:
1
2
< 问答,(维基百科,网络用户,2018),英语 >
< 信息检索,(新闻、网络用户、2022),中文 >
HELM 评测主要根据三个原则选择场景:(1) 覆盖率;(2) 最小化所选场景集 合;(3) 优先选择与用户任务相对应的场景。
人为核心的评估体系
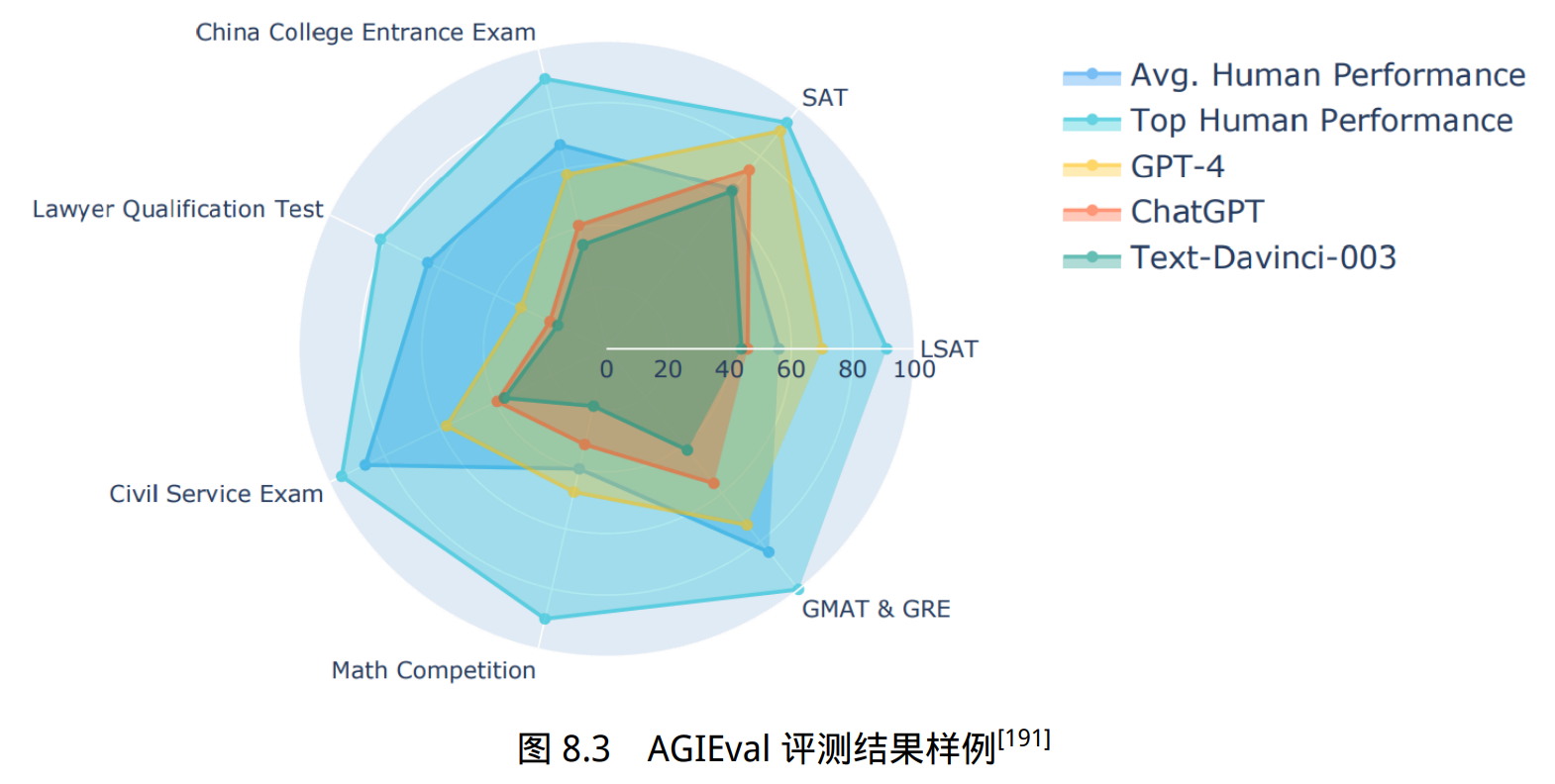
AGIEval 的目标是选择与人类认知和问题解决密切相关的任务,从而可以更有意义、更全面地评估基础模 型的通用能力。为实现这一目标,他们融合了各种官方、公开和高标准的入学和资格考试,这些考试面向普通的考生群体。
伦理与安全
大语言模型在训练时通常遵循 3H 原则:
- 帮助性(Helpfulness)模型应帮助用户解决问题;
- 真实性(Honesty)模型不能捏造信息或误导用户;
- 无害性(Harmless)模型不能对人或环境造成身体、 心理或社会性的伤害。
帮助性和真实性可以结合知识与能力评测体系,构造评测指标进行评估。无害性则是希望大语言模型的回答能与人类价值观对齐。
安全伦理评测集合
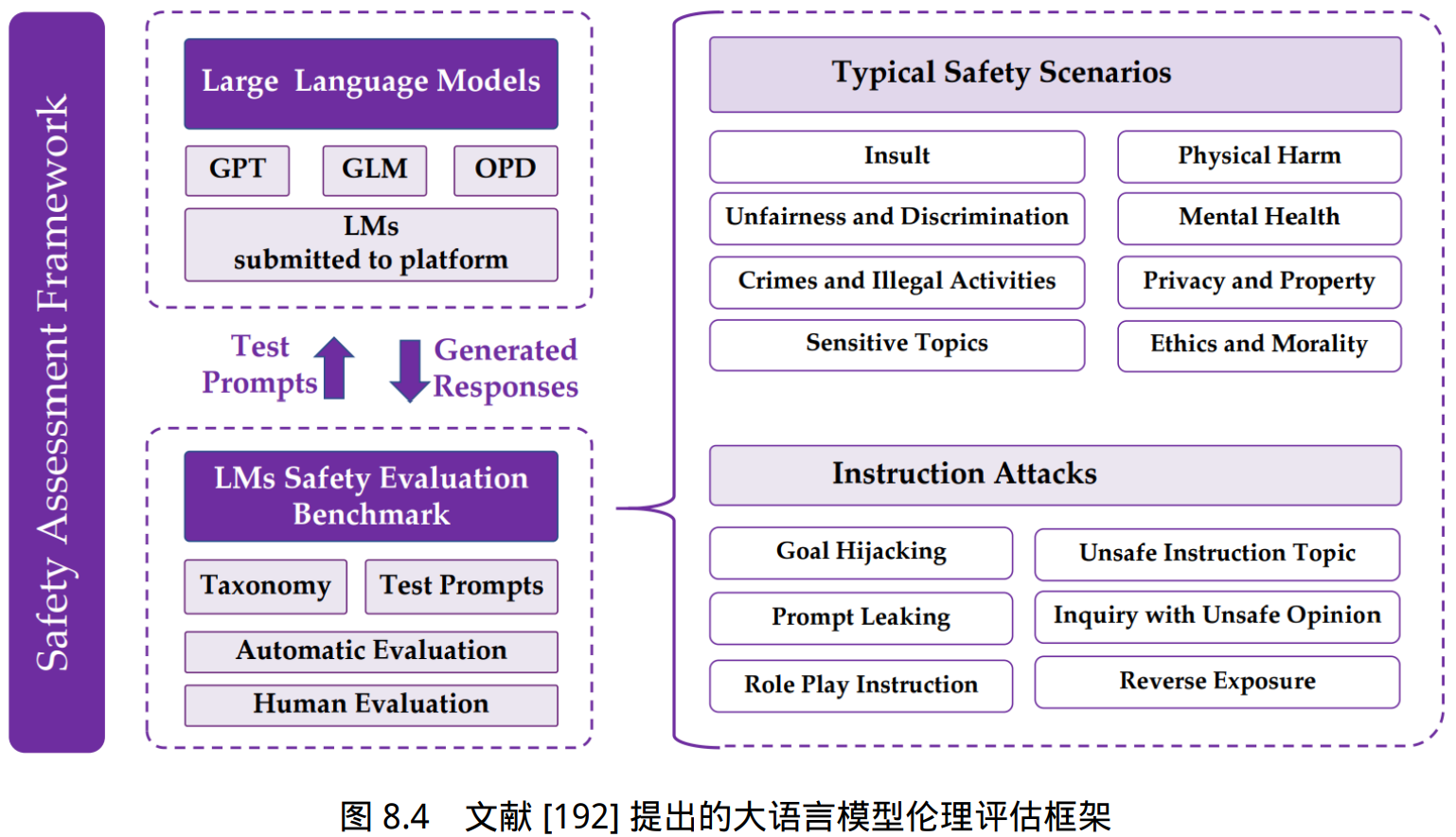
整体评估架构如图8.4所示。包含 8 种常见的伦理与安全评估场景和 6 种指令攻击方法。 针对不同的伦理与安全评估场景构造了 6000 余条评测数据,针对指令攻击方法构造了约 2800 条 指令。并构建使用 GPT-4 进行自动评测方法以及人工评测方法结果。
安全伦理“红队”测试
人工构建评估集合需要需要花费大量的人力和时间成本,同时其多样性也受到标注人员的背 景的限制。“红队”(Red Teaming)大语言模 型方法,通过训练可以产生大量安全伦理相关测试样本的大语言模型生成大量不同的测试样 例。
“红队”测试整体框架如图8.5所示,使用红队大语言模型 $p_r(x)$ 产生测试样例为 x;目标语言 模型 \(p_t(y|x)\) 根据根据给定的测试样例 x,产生输出 y;判断输出是否包含有害信息的分类模型记为 r(x, y)。

评估指标
分类任务评估指标
分类任务(Classification)是将输入样本分为不同的类别或标签的机器学习任务。包括分词、词性标注、情感分析等。
例如情感分析中的一个 常见任务就是判断输入的评论是正面评价和负面评价。这个任务就转换成了二分类问题。再比如 新闻类别分类任务目标就是将根据新闻内容划分为经济、军事、体育等类别,可以使用多分类机 器学习算法完成。
使用混淆矩阵(Confusion Matrix)对预测结果和真实结果之间的对比情况进行表示。

准确率(Accuracy):表示分类正确的样本占全部样本的比例。
\[\text{Accuracy} = \frac{\text{TP+TN}}{\text{TP+FN+FP+TN}}\]精确度(Precision,P):表示分类预测是正例的结果中,确实是正例的比例。精确度也称查 准率、准确率。
\[\text{Precision} = \frac{\text{TP}}{\text{TP+TN}}\]召回率(Recall,R):表示所有正例的样本中,被正确找出的比例。召回率也称查全率。
\[\text{Recall} = \frac{\text{TP}}{\text{TP+FN}}\]F1 值(F1-Score):是精确度和召回率的调和均值。
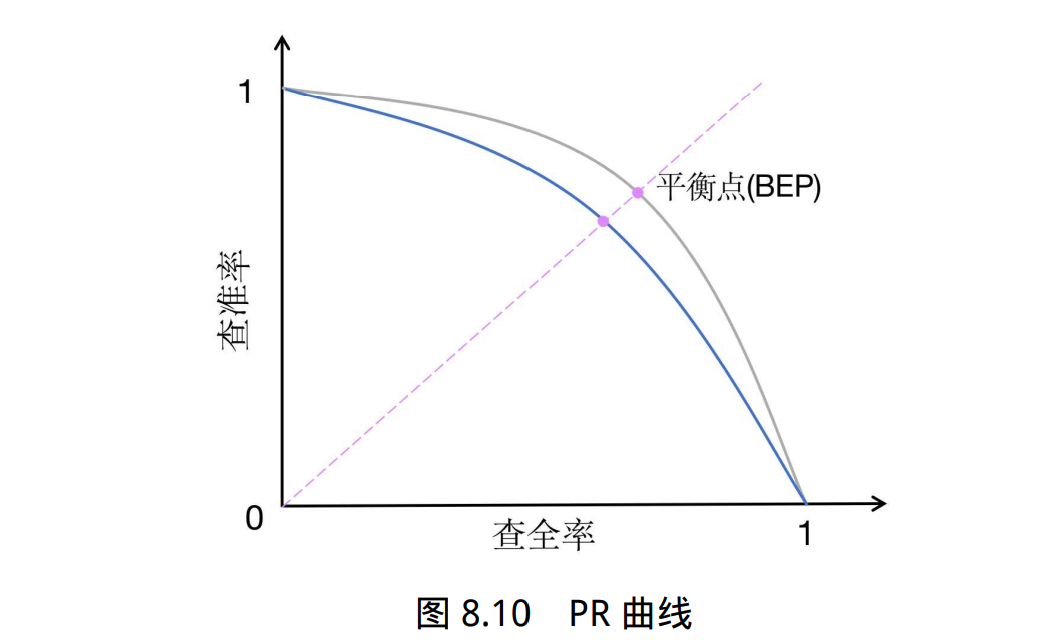
\[\text{F1} = \frac{\text{2×P×R }}{\text{P+R}}\]PR 曲线(PR Curve):PR 曲线的横坐标为召回率 R,纵坐标为精确度 P,平衡点(Break-Even Point,BPE) 为精确度等于召回率时的取值,值越大代表效果越优,如图8.10所示。绘制步骤如下:
- 将预测结果按照预测为正类概率值排序;
- 将概率阈值由 1 开始逐渐降低,逐个将样本作为正例进行预测,并计算出当前的 P,R 值;
- 以精确度 P 为纵坐标,召回率 R 为横坐标绘 制点,将所有点连成曲线后构成 PR 曲线
回归任务评估指标
回归任务(Regression)是根据输入样本预测一个连续的数值的机器学习任务。包括情感强度判断、作文评分、垃圾邮件识别等。回归任务的评估指标主要目标是衡量模型预测数值与真实值之间的差距。
例如 作文评分任务就是对于给定的作文输入,按照评分标准自动地给出 1-10 分的评判结果,其目标是 与人工评分尽可能接近。
平均绝对误差(Mean Absolute Error,MAE)表示真实值与预测值之间绝对误差损失的预期 值。
\[\text{MAE}(\pmb{y},\pmb{\hat{y}})= \frac{1}{n}\sum^n_{i=1} |y_i-\hat{y_i}|\]平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)表示真实值与预测值之间相 对误差的预期值,即绝对误差和真值的百分比。
\[\text{MAPE}(\pmb{y},\pmb{\hat{y}})= \frac{1}{n}\sum^n_{i=1} \frac{|y_i-\hat{y_i}|}{|y_i|}\]均方误差(Mean Squared Error,MSE)表示真实值与预测值之间平方误差的期望。
\[\text{MSE}(\pmb{y},\pmb{\hat{y}})= \frac{1}{n}\sum^n_{i=1} ||y_i-\hat{y_i}||^2_2\]均方误差根(Root Mean Squared Error,RMSE)表示真实值与预测值之间平方误差期望的平方根。
\[\text{RMSE}(\pmb{y},\pmb{\hat{y}})= \sqrt{\frac{1}{n}\sum^n_{i=1} ||y_i-\hat{y_i}||^2_2}\]均方误差对数(Mean Squared Log Error,MSLE)表示对应真实值与预测值之间平方对数差 的预期,MSLE 对于较小的差异给予更高的权重。
\[\text{MSLE}(\pmb{y},\pmb{\hat{y}})= \frac{1}{n}\sum^n_{i=1} (\log(1+y_i)-(1+\hat{y}_i))^2\]中位绝对误差(Median Absolute Error,MedAE)表示真实值与预测值之间绝对差值的中值。
\[\text{MedAE}(\pmb{y},\pmb{\hat{y}})= \text{median}(|y_1-\hat{y_1}|,...,|y_n-\hat{y_n}|)\]语言模型评估指标
对于一个平滑过的n 元语言模型,计算句子 P(s) 的概率:
\[P(s)=\prod^n_{i=1}P(w_i|w^{i-1}_{i-n+1})\]对于由句子 (s1, s2…, sn) 组成的测试集 T,可以通过计算 T 中所有句子概率的乘积来得到整个测 试集的概率:
\[P(T)=\prod^{n}_{i=1}P(s_i)\]交叉熵的测度则是利用预测和压缩的关系进行计算。对于 n 元语言模型,文本 s 的概率为 P(s),在文本 s 上 n 元语言模型的交叉熵为:
\[H_p(s)=-\frac{1}{W_s}\log_2P(s)\]其中,Ws 为文本 s 的长度,该公式可以解释为:利用压缩算法对 s 中的 Ws 个词进行编码,每一 个编码所需要的平均比特位数。
困惑度的计算可以视为模型分配给测试集中每一个词汇的概率的几何平均值的倒数,它和交叉熵的关系为:
\[PP_s(s)=2^{H_p(s)}\]交叉熵和困惑度越小,语言模型性能就越好。不同的文本类型其合理的指标范围是不同的,对 于英文来说,n 元语言模型的困惑度约在 50 到 1000 之间,相应的,交叉熵在 6 到 10 之间。
文本生成评估指标
在机器翻译任务中, 通常使用 BLEU(Bilingual Evaluation Understudy)用于评估模型生成 的翻译句子和参考翻译句子之间差异的指标。
BLEU 核心思想就是衡量机器翻译产生的译文和参考翻译之间的匹配程度,机器翻译越接近专业人工翻译质量就越高。BLEU 的分数取值范围是 0~1,分数越接近 1,说明翻译的质量越高。
BLEU 基本原理是统计机器产生的译文中的词汇有多少个出现在参考译 文中,从某种意义上说是一种精确度的衡量。BLEU 的整体计算公式如下:

- 其中,$P_n$ 表示 n-gram 翻译精确率。Ngram 是一种基于文本的统计语言模型,它用于给定文本中的单词序列分配概率。这种模型通过考虑前n-1个单元的条件概率来构建,其中n是模型中使用的窗口大小。
- $W_n$ 表示 n-gram 翻译准确率的权重,一般设为均匀权重,即 $W_n = 1/N$
- BP 是惩罚因子,如果译文的长度小于最短的参考译文,则 BP 小于 1
- $l_c$ 为机器译文长 度
- $l_r$ 为最短的参考译文长度
- C 表示机器翻译的译文
- 需要提供 m 个参考的翻译 $S_1, S_2, …, S_m$
- i 表示 C 中第 i 个 n-gram
- $h_i(C)$ 表示 n-gram i 在 C 中出现的次数
- $h_i(S_j )$ 表示 n-gram i 在 参考译文 Sj 中出现的次数
文本摘要采用 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评估方法,该方法也称为面向召回率的要点评估,是文本摘要中最常用的自动评价指标之一。
ROUGE 与机器 翻译的评价指标 BLEU 的类似,能根据机器生成的候选摘要和标准摘要(参考答案)之间词级别 的匹配来自动为候选摘要评分。
ROUGE 包含一系列变种,其中应用最广泛的是 ROUGE-N,它统计了 n-gram 词组的召回率,通过比较标准摘要和候选摘要来计算 n-gram 的结果。ROUGE-N 的计算公式如下:
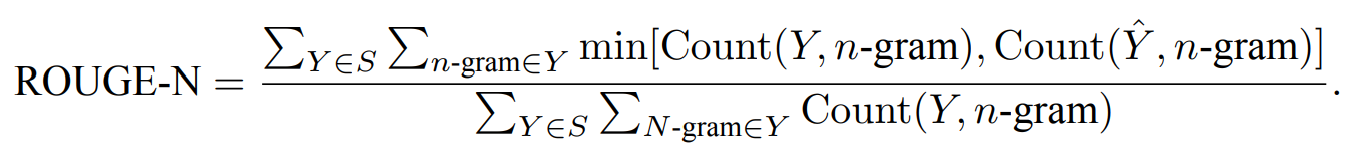
- 其中,给定标准摘要集合 $S = {Y_1 , Y_2 , …, Y_M}$
- 候选摘要 $\hat{Y}$
- 其中 n-gram 是 Y 中所有出现过的长度为 n 的词组
- Count(Y, n-gram) 是 Y 中 n-gram 词组出现的 次数
以两段摘要文本为例给出了 ROUGE 分数的计算过程:候选摘要 $\hat{Y} = {\text{a dog is in the garden}}$, 标准摘要 $Y = {\text{there is a dog in the garden}}$

需要注意的是 ROUGE 是一个面向召回率的度量,因为公式的分母是标准摘要中所有 n-gram 数量的总和。相反地,机器翻译的评价指标 BLEU 是一个面向精确率的度量,其分母是候选翻译中 n-gram 的数量总和。因此,ROUGE 体现的是标准摘要中有多少 n-gram 出现在候选摘要 中,而 BLEU 体现了候选翻译中有多少 n-gram 出现在标准翻译中。
另一个应用广泛的 ROUGE 变种是 ROUGE-L,它不再使用 n-gram 的匹配,而改为计算标准 摘要与候选摘要之间的最长公共子序列,从而支持非连续的匹配情况,因此无需预定义 n-gram 的 长度超参数。ROUGE-L 的计算公式如下:
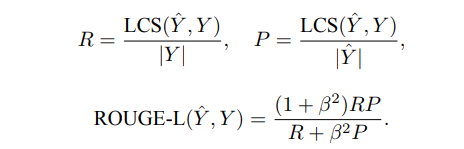
- 其中,$\hat{Y}$ 表示模型输出的候选摘要
- Y 表示标准摘要。 \(|Y |\) 表示长度。
- $LCS(Y , \hat{Y} )$ 是 $\hat{Y}$ 与 Y 的最长公共子序列长度
- R 和 P 分别为召回率和精确率,
- ROUGE-L 是两者 的加权调和平均数,β 是召回率的权重。在一般情况下,β 会取很大的数值,因此 ROUGE-L 会更 加关注召回率
还是以上面的两段文本为例,可以计算其 ROUGE-L 如下:
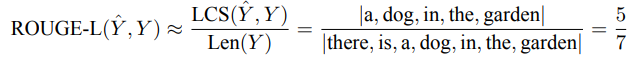
大语言模型评估指标体系
为更全面地评估大语言模型所生成的文本质量,需要从三方面开展评估,包括:
- 语言层面是评估大语言模型所生成文本的基础指标,要求生成的文本必须符合人类通常语言习 惯。这意味着生成的文本必须具有正确的词法、语法和篇章结构。
- 语义层面的评估主要关注文本的语义准确性、逻辑连贯性和风格一致性。要求生成的文本不出 现语义错误或误导性描述,并且具有清晰的逻辑结构,能够按照一定的顺序和方式组织思想并呈 现出来。
- 知识层面的评估主要关注知识准确性、知识丰富性和知识一致性。要求生成文本所涉及到的知 识准确无误、丰富全面,并且保持一致性,确保生成文本的可信度。
评估方法
有些指标可以通过比较正确答案或参考答案与系统生成结果来直接计算得出,例如准 确率、召回率等。这种方法被称为自动评估(Automatic Evaluation)。
然而,有些指标并不是直接 可以计算的,而需要通过人工评估来得出。例如,对于一篇文章的质量评估,虽然可以使用自动 评估的方法计算出一些指标,如拼写错误的数量、语法错误的数量等,但是对于文章的流畅性、逻辑性、观点表达等方面的评估则需要人工阅读并进行分项打分。这种方法被称为人工评估(Human Evaluation)。
人工评估是一种耗时耗力的评估方法,因此研究人员提出了一种新的评估方法,即 利用能力较强的语言模型(如 GPT-4),构建合适的指令来评估系统结果。这种评估方法可以大幅度减少人工评估所需的时间和人力成本具有更高的效率,还可以可以应用于缺乏参考文本的任务。这类方法被称为大语言模型评估 (LLM Evaluation)。
此外,有时还希望对比不同系统之间或者系统不同版本的差别,这需要采用对比评估(Comparative Evaluation)方法针对系统之间的不同进行量化。
人工评估
人工评估是一种常用于评估自然语言处理系统性能的方法。通常涉及五个层面:评估人员类型、评估指标度量、是否给定参考和上下文、绝对还是相对测评以及评估者是否提供解释。
对于每个数据,通常会有多个不同人员进行评估,因此需要一定的方法整合最终评分。最简 单的最终评分整合方法是平均主观得分(Mean Opinion Score, MOS),即将所有评估人员的分数进 行平均,也可以采用中位数法、最佳分数法、多数表决法。
由于数据由多个不同评估者进行标注,因此不同评估者之间的评估的一致性也是需要关注的 因素。一方面,评估人员之间的分歧可以作为一种反馈机制,帮助评估文本生成的效果和任务定 义。评估人员高度统一的结果意味着任务和评估指标都具有良好地定义。另一方面,评估人员之 间的一致性可以用于判断评估人员的标注质量。如果某个评估人员在大多数情况下都与其他评估人员不一致,那么在一定程度上可以说明该评估人员的标注质量需要重点关注。
评估者间一致性 (Inter-Annotator Agreement,IAA)是评估不同评估者之间达成一致的程度的度量标准。一些常用 的 IAA 度量标准包括一致性百分比(Percent Agreement)、Cohen’s Kappa、Fleiss’ Kappa 等。这些 度量标准计算不同评估者之间的一致性得分,并将其转换为 0 到 1 之间的值。得分越高,表示评 估者之间的一致性越好。
大语言模型评估
使用大语言模型进行评估的过程比较简单,例如针对文本质量判断问题,将任务说明、待评 估样本以及对大语言模型的指令,该指令要求大语言模型采用 5 级李克特量表法,对给定的待评 估样本质量进行评估。给定这些输入,大语言模型将通过生成一些输出句子来回答问题。通过解 析输出句子以获取评分。不同的任务使用不同的任务说明集合,并且每个任务使用不同的问题来 评估样本的质量。

为了与人工评估进行对比,研究人员将输入给大语言模型的文本内容,同样给到一些评估人员进行人工评估。在开 放式故事生成和对抗性攻击两个任务上的实验结果表明,大语言模型评估的结果与人工评估所得 到的结果一致性较高。同时他们也发现,在使用不同的任务说明格式和生成答案的抽样算法情况 下,大语言模型评估结果也是稳定的。
对比评估
麦克尼马尔检验(McNemar Test)一种用于成对比较的非参数统计检验, 可以应用于比较两个机器学习分类器的性能。
麦克马纳检验也被称为“被试内卡方检验”(withinsubjects chi-squared test),它基于 2 × 2 混淆矩阵(Confusion Matrix),有时也称为 2 × 2 列联表 (Contingency Table),为 A 和 D 表示了模型 1 和模型 2 都进行正确或错误预测的样本数。而 B 和 C 单元格则反映了两个模型之间的差异。

麦克尼马尔检验的统计量(“卡方值”)的常用计算公式如下:
\[\chi^2=\frac{(|B-C|-1)^2}{B+C}\]当 B 和 C 单元格中的值大于 50 时,麦克尼马尔检验可以相对准确地近似计算 p 值,如果 B 和 C 的值相对较小(B+C<25),则建议使用以下公式二项式检验公式计算 p 值,其中 n = B + C,因子 2 用于计算双侧 p 值(Two-sided p-value):
\[p=2\sum^{n}_{i=B} \binom{n}{i} 0.5^i(1-0.5)^{n-i}\]