Human Activity Recognition based on Wi-Fi CSI Data-A Deep Neural Network Approach
读论文时间!
基于 WiFi CSI 数据预测人类活动的深度神经网络方法
官方代码: https://github.com/Retsediv/WIFI_CSI_based_HAR
引入
使用Wi-Fi信道状态信息(CSI)是一种新颖的环境感知和人类活动识别(HAR)方法。
HAR 不仅是检测某一特定时刻的人类活动。例如,它还包括手势识别等三个主要类别和十个子类别。
接收信号强度指示器(RSSI)和通道状态信息(CSI)机制原来是为了分析WiFi信道状态和调整路由器配置使用的,不过由于人的活动也会扭曲无线电波,因此对其分析可以判断周围的活动。
RSSI 是一种指示信号强度的度量。但是它相当不稳定,不同厂商之间存在差异,并且无法准确捕获由于人的运动引起的信道变化。CSI 提供了关于信道状态的更精确信息,对于每个子载波频率上的发射机和接收机天线对,它测量传播无线信号并为不同的子信道提供幅度和相位失真。因此CSI更适合。
之前工作的不足:
- 机器学习模型的性能在很大程度上取决于环境,环境越复杂,准确度就越低。
- CSI在新环境中表现不佳。
- 公开的训练数据集存在硬件差异(例如不同数量的天线、灵敏度、频率等)
在这项工作中,我们专注于开发一个全面的基于 CSI 的人体活动识别系统,该系统考虑了硬件、数据和模型方面。我们进行了实验来分析 WiFi 配置与 CSI 数据之间的关系。我们展示了一种数据收集方法,可以执行不同类型的活动,而不需要严格的时间顺序,从而创建更接近现实的设置。我们提出了一种数据预处理工作流程,用于构建和比较基于 InceptionTime 和 LSTM 的分类模型。
背景知识
Wi-Fi 网络内的移动用户会影响多径传播。 Wi-Fi 信道也由静止物体(如家具)反射的信号组成。不同的活动也会导致额外的反射。

严谨地,CSI 表示从发射机(记为 x)到接收机(记为 y)的信号变化
\[y=Hx+n\]- 其中 H 是一个由 CSI 值组成的复数矩阵
- n 是信道噪声。
对应于20 MHz 和40 MHz 的信道带宽,正交频分复用(Orthogonal Frequency Division Multiplexing, OFDM)将总带宽分为 56 或 114 个子带宽。每个子载波的 CSI 为:
\[h=|h|e^{j\theta}\]- 其中 \(|h|\) 表示幅度
- θ 表示相位。
为了测量CSI,发射机发送长训练符号(LTS),其中包含每个子载波的预定义信息。当接收器接收到LTS时,它估计了CSI,其差异为原始和接收到的LTS。然而,在现实世界系统中,CSI受到多径信道、接收/传输处理、硬件和软件错误的影响。
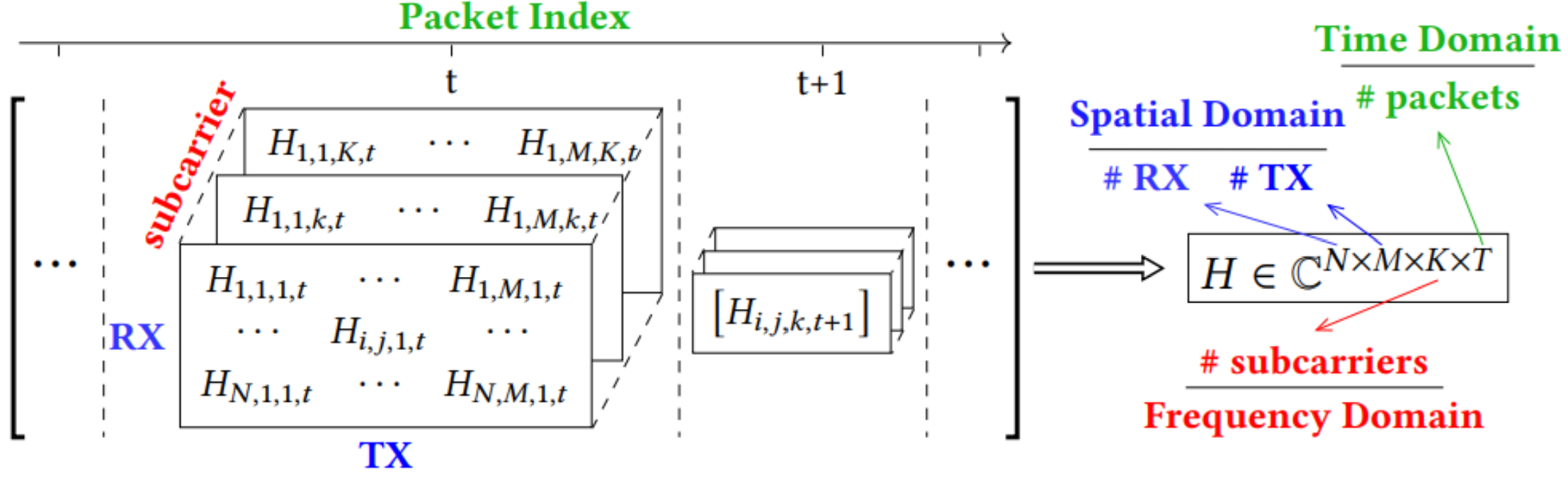
如图,CSI 矩阵由 5 Ghz 频带的 114 个复数 H 矩阵或 2.4 Ghz 的 56 个组成,维度为 $N_{T_x} \times N_{R_x}$。56 和 114 是根据 CSI 提取工具可以处理的子载波数量来定义的。Tx代表transmitter发射器数量,TX
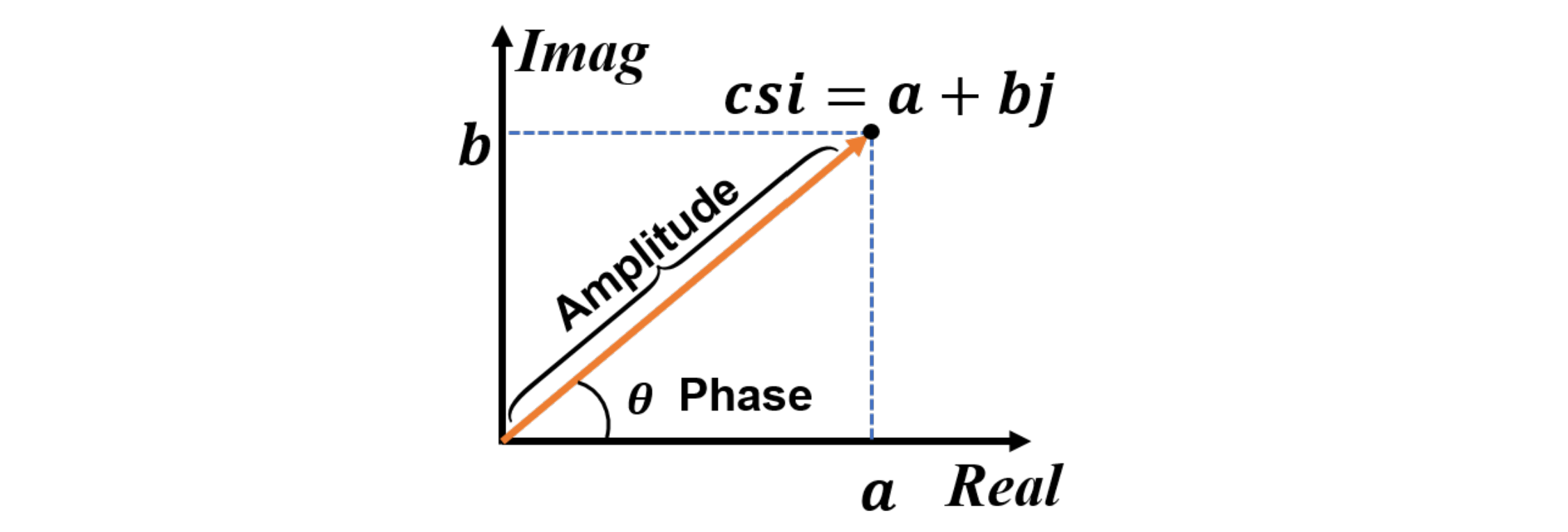
CSI由复数形式的信号组成:
\[csi = a + bj\]每个这样的条目代表了从发射器到接收器发送的原始信号引起的振幅和相位变化。振幅和相位的计算方法如图:
在行走时,由于人会改变姿势和房间的位置,振幅和相位经常且迅速地发生变化。我们关注的是快速可变的变化,这是我们寻找的模式。我们希望看到的模式是从之前的活动(例如没人)到当前活动(例如有人走过)的 CSI 值如何变化——两个活动之间的过渡。
我们绘制 CSI 数据图以观察数据随时间的变化,并通过它来寻找模式。一个这样的图表的例子如图所示。在此示例中,步行区域位于 x 轴上,我们可以清楚地看到“步行”和“不活动”数据之间的模式。
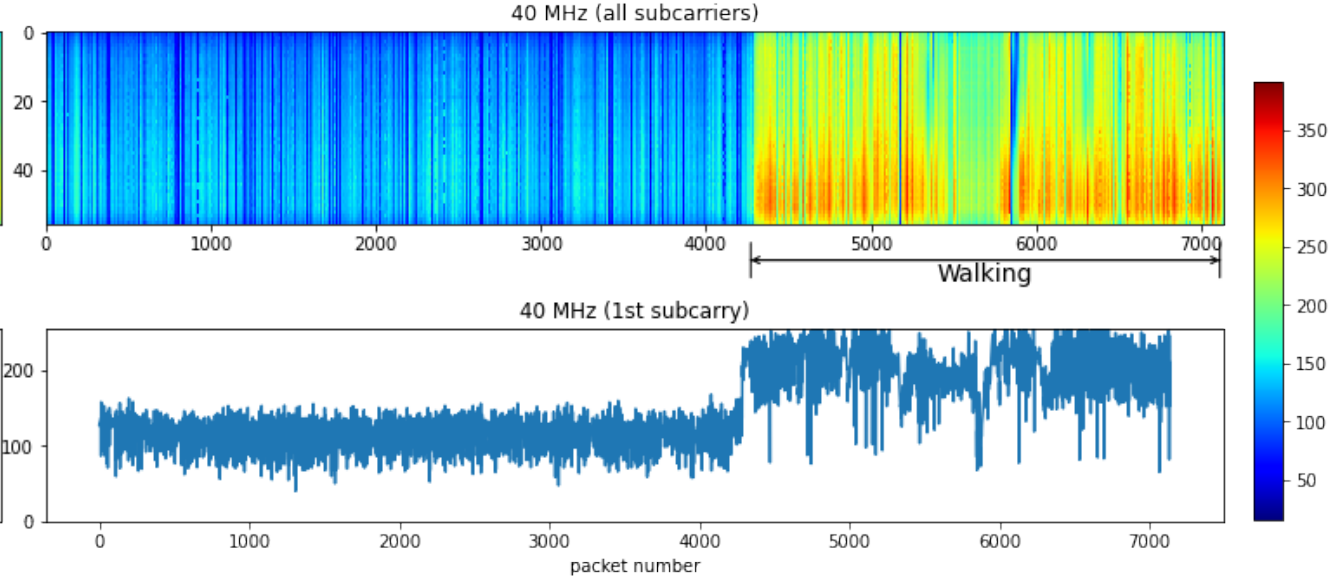
- 图显示了特定Wi-Fi 频道下的 CSI 值
- y 轴对应于子载波
- x 轴代表时间线并显示每个 CSI 小包编号
- 该图形中每个点的颜色与右侧颜色条上的对应值相同。
- 单载波图使用简单的折线图可视化单个子载波。
实验
实验的目标是从路由器配置中选择最佳选项,包括:
- 信道 Channel
- 带宽 Bandwidth
- 频率 Frequency
- 天线数量 Antenna
- 发射器和接收器的位置(同一房间或不同房间)Position
- 手势 Gesture
选择的方法是比较在相同的人体运动模式(行走)下,在不同的信道、带宽等上测量到的振幅和相位,将结果绘制成图形,并选择对比度更高的配置,以便更容易地观察到活动模式。
实验一:Channel
WiFi频道是无线网络中用于发送和接收数据的 Wi-Fi 频率带中的较小信道。路由器使用的频率带不同,可以使用的具体信道数量也有所不同:在 2.4G 频率下有 11 个信道,在 5G 频率下有 45 个信道。值得注意的是,5G 频率下的信道号不是连续编号的,目前可使用最大的信道号为 173。
在设置WiFi网络时,建议选择1、6或11号频道。这些频道比其他频道具有更好的WiFi性能,因为它们与其他频道不重叠。实验中选择了3,7,10,11四个频道实验(人走过)

上图的实验配置:
- Bandwidth 40 MHz
- Channels 3, 7, 10, 11
- Frequency 2.4 GHz
- Antennas 2Rx vs 2Tx
实验二:Bandwidth
在 IEEE 802.11n (一种使用多个天线以提高数据速率的无线网络标准) 的情况下,可以使用的带宽为 20MHz、40MHz 或 80MHz(后者的硬件不支持)。较高的带宽对应于更高的数据吞吐量。然而,它减少了可以使用的频道。
如图所示,带宽为40MHz时,行走区域在实验中得到了更好的突出显示,行走区域与“沉默”区域之间的差异大于20MHz。然而,40MHz 的带宽为系统增加了更多的噪声,40MHz 处幅值方差比20MHz 处要大。
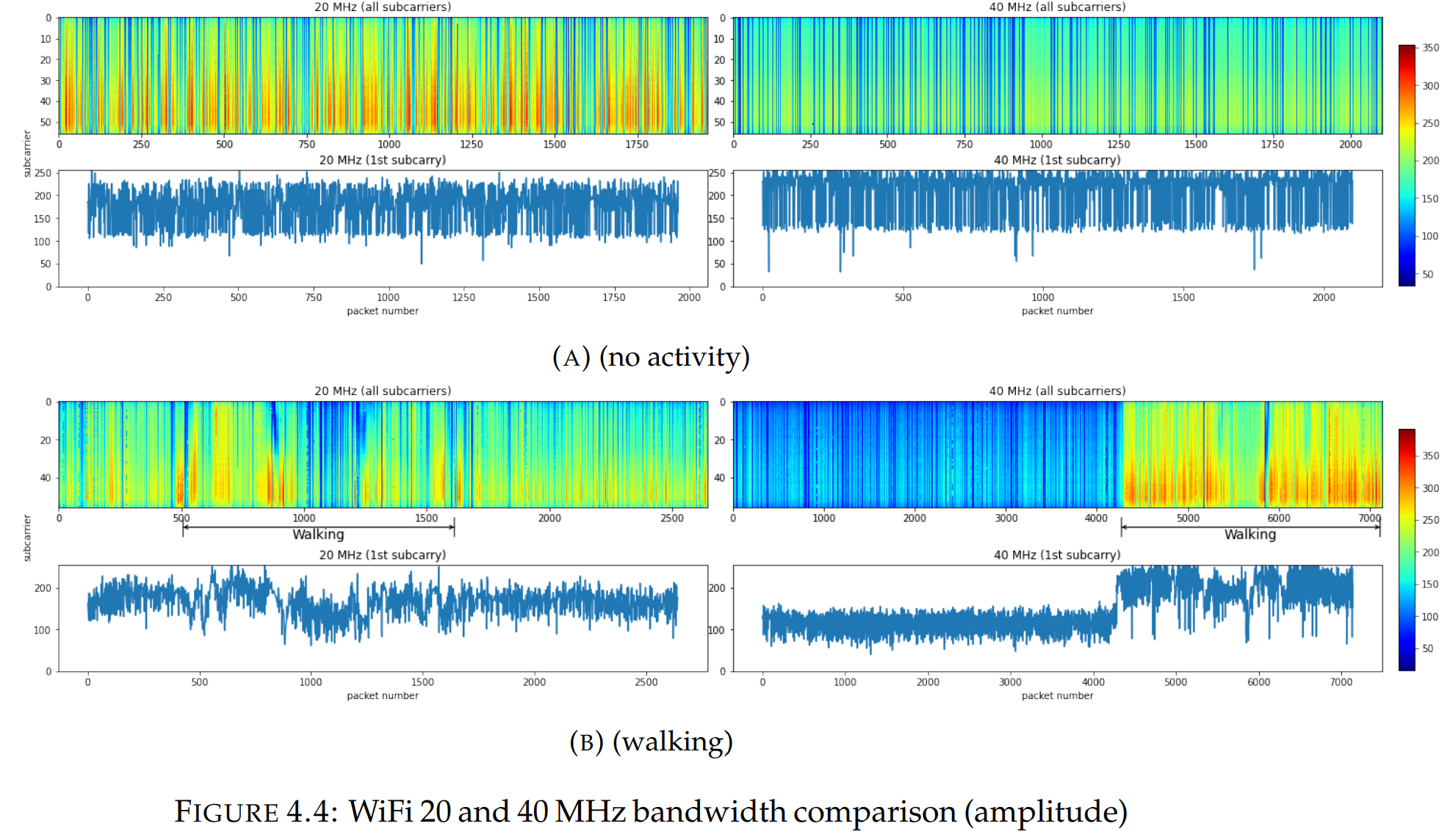
上图的实验配置:
- Bandwidths 20, 40 MHz
- Channel 11
- Frequency 2.4 GHz
- Antennas 2Rx vs 2Tx
构建了一个负责Tx-Rx通信、CSI计算以及数据捕获以进行进一步分析的系统。它由两个程序组成,一个用于发送常量wifi包,另一个用于接收并计算CSI。由于路由器没有足够的空间来保存大量的数据,因此需要使用这种方法来减少所需的存储空间。
实验三:Frequency
Wi-Fi网络有0.9、2.4、3.6和5 ghz 频率可供使用。然而,只有2.4和5 ghz 最常见且流行,因此我们只关注它们。一般来说,就WiFi 覆盖范围而言,2.4 ghz比5 ghz 更胜一筹,但5 ghz 的速度要快得多。在5 ghz频段的振幅比2.4 ghz频段小,更少的数据噪声。
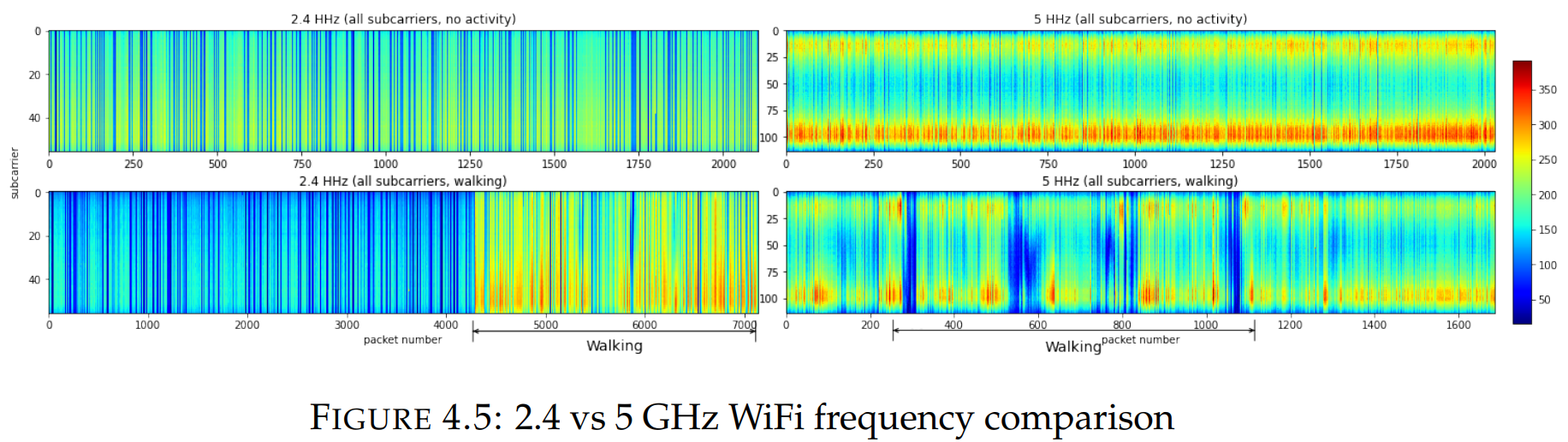
上图的实验配置:
- Bandwidths 40 MHz
- Channel 11
- Frequency 2.4, 5
- GHz Antennas 2Rx vs 2Tx
实验四:Antenna
TP-LINK TL-WR4300 有三个天线(这三个都可以在 5 GHz 频率下工作,但只有两个可以在 2.4 GHz 频率下工作)。不同的天线配置(发送器路由器上启用的天线数量和接收器路由器上的天线数量)被测试以了解它们的数量如何影响检测步行活动的能力。
实验表明,当一个人不在视线范围内时:
- 1Rx×1Tx配置无法实际检测到活动。
- 1Rx x 2Tx 和 2Rx x 1Tx 配置与 3Rx x 2T 和 2Rx x 2Tx 的结果相比表现较差。在行走开始和结束时振幅发生了变化,但这种变化本身非常短暂,并且在活动过程中没有观察到任何变化。
- 3Rx x 2T 和 2Rx x 2Tx 配置,活动模式更清晰地显示出来,并且可以观察到活动期间振幅的变化。
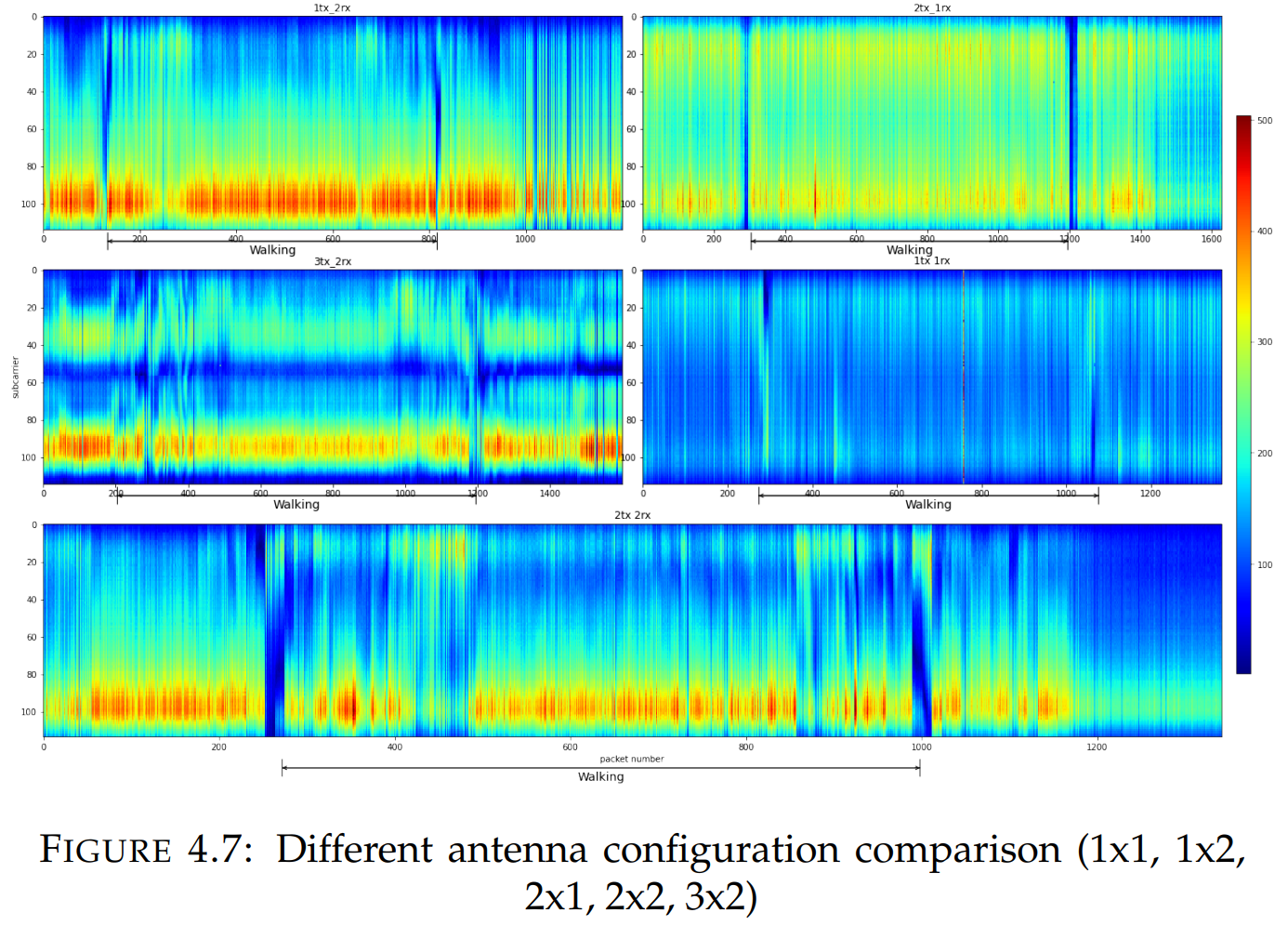
上图的实验配置:
- Bandwidths 40 MHz
- Channel 60
- Frequency 5 GHz
- Antennas 1Rx x 1Tx, 2Rx x 2Tx, 2Rx x 1Tx, 1Rx x 2Tx, 2Rx x 3Tx
我们可以得出结论,当人不在视线范围内时,我们需要至少两个接收器天线和两个发射器天线来检测“步行”活动。
实验五:Position
如果发射器和接收器路由器位于不同的(相邻)房间。然后在两个房间都进行了“步行”活动。结果如图,在两个房间的数据中,活动没有发现任何差异,这是预期的。

上图实验设置:
- Bandwidths 40 MHz
- Channel 11
- Frequency 2.4 GHz
- Antennas 2Rx vs 2Tx
如果发射器和接收器路由器位于相同房间内。之后在两个路由器都存在的房间里进行“行走”活动,然后在另一个房间进行。结果如图所示。在有路由器的房间里人类活动可以很容易地被检测到,但当一个人在另一个房间时,不可能检测到。
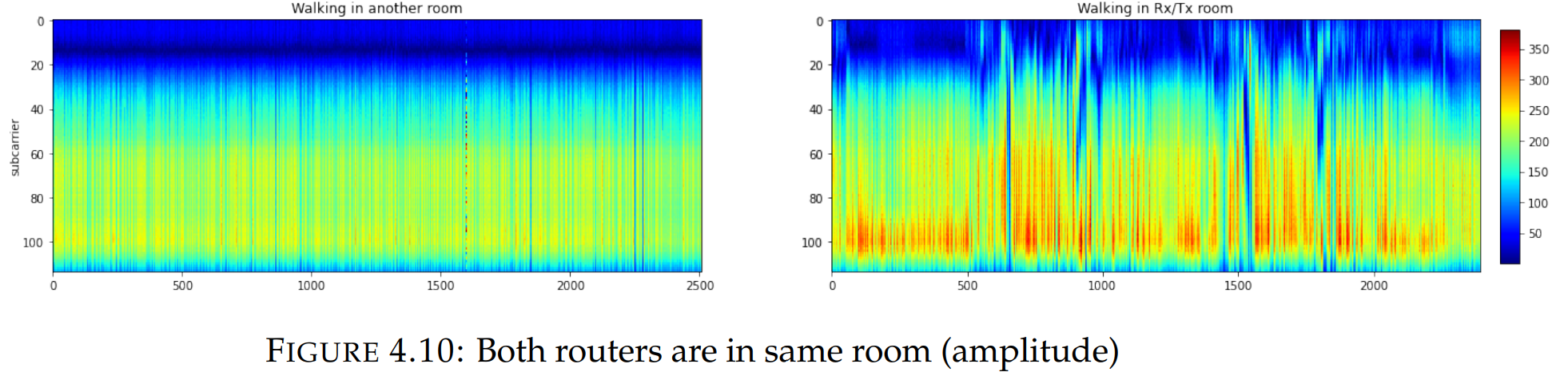
上图实验设置:
- Bandwidths 40 MHz
- Channel 60
- Frequency 5 GHz
- Antennas 2Rx vs 2Tx
实验六:Gesture
实验演示了手臂移动的手势:垂直移动的手臂,稍作停顿,横向移动五次。根据结果(如图4.11所示),当手臂垂直和水平移动时,有特定的数据模式,因此我们可以区分它们。
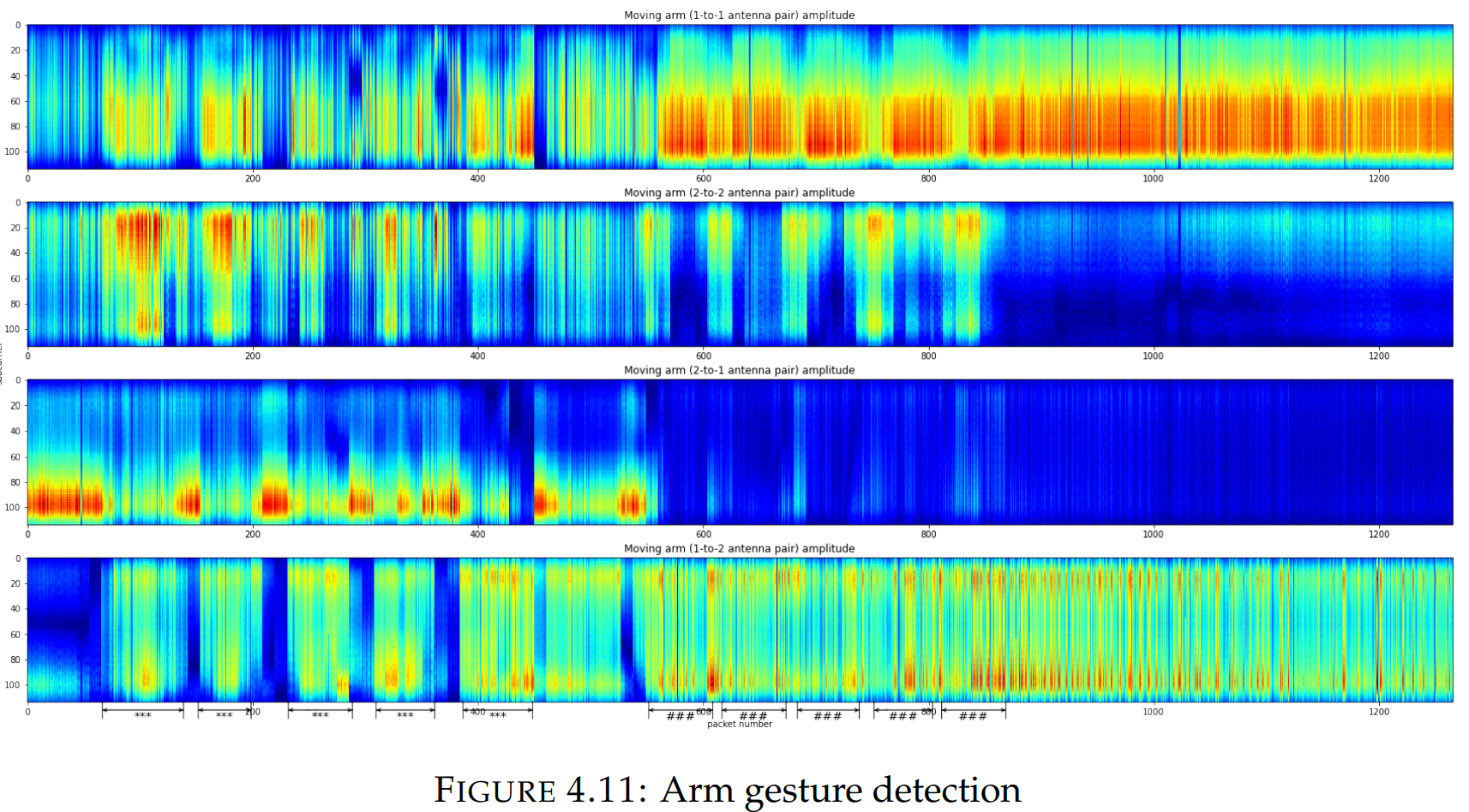
上图实验设置:
- Bandwidths 40 MHz
- Channel 60
- Frequency 5 GHz
- Antennas 2Rx vs 2Tx
然而对于手掌移动手势:垂直移动的手掌,稍作停顿,横向移动。根据结果,随着时间的推移,数据发生了一些变化,但是很难找到区分水平和垂直手掌运动的数据模式,并检测到它们的确切时间范围。这可能是因为手掌运动非常小(与手臂相比),并且不会影响 CSI 数据太多。
注:Widar3.0是一个有效的基于CSI的手势识别模型,识别手掌运动是可行的。
总结一下:
- 接收器和发射器上至少需要两个天线。
- 推荐使用 5 ghz 频段,因为它不会受到邻居节点的影响。
- 带宽越大越好,因为即使在噪声增加的情况下,它也能提供更多的灵敏度,但稍后可以消除这种影响。
- 为了获得更好的信道可扩展性,最好选择不重叠的信道。使用第 11 个信道的步态区域模式比其他信道具有更强的对比度。
- 如果房间内没有接入点或客户端路由器,就无法检测到活动和动作。
- 使用 WiFi CSI 来识别手势需要进一步研究。
数据集
我们收集了一个新的数据集。执行的活动:行走、坐、站、躺、起床、下床以及房间内没有人时的不活动。总共使用了三个不同的房间,其平面图如图所示。每个CSI包都标记有图像、图像中的人的活动和人的边框盒
- Activities: walking, sitting, standing, lying, getting up, getting down, no activity
- Size: 1.2 Gb (no images), 9.1 Gb (with images)
- Labels: activity, person bounding box coordinates
- # of people involved: 1
- # of rooms used: 3
- WiFi router TP-Link TL-WDR4300
- Bandwidth 40 MHz
- Channel 60
- Frequency 5 GHz
- Antennas 2Rx x 2Tx
- of subcarriers 114

数据处理
相位处理
即使拥有最好的硬件和配置,CSI 数据也存在大量噪声,因此无法直接使用原始相位信息。它受到载波频率偏移(CFO)和采样速率偏移(SFO)的影响。当发射机和接收机在传输包之前没有精确同步它们的时间和相位时,就会发生CFO。SFO是由模数转换器引起的,并且随子载波的不同而不同,因此每个子带最终都有不同的误差。
例如,如果收发器时钟差异为50秒,则在5 GHz WiFi频段上,这会导致8π的相位变化。根据这一点,由于人类移动而产生的相位变化通常小于0.5π,因此无法从相位变化中观察到这一点。
由于我们不知道 CFO 和 SFO,因此原始相位信息没有用。不过线性变换方法旨在解决这个问题。如图,在去噪之后,相位数据变得更加平滑,我们看到在行走过程中,相位发生了变化。
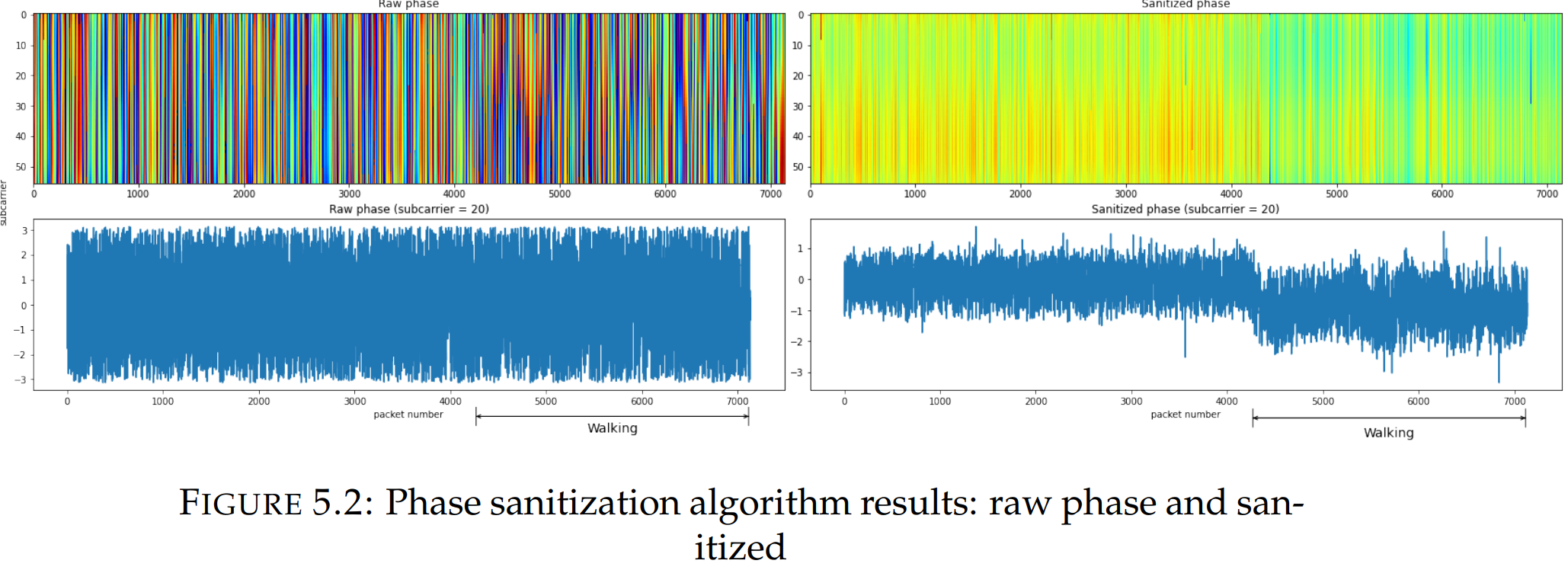
异常值剔除
振幅和相位数据包含由跃迁速率、功率适应、热噪声等引起的噪声。因此,它会引入一些非人为因素造成的信号异常值。Hampel标识算法是为了解决这个问题。其结果如图所示。

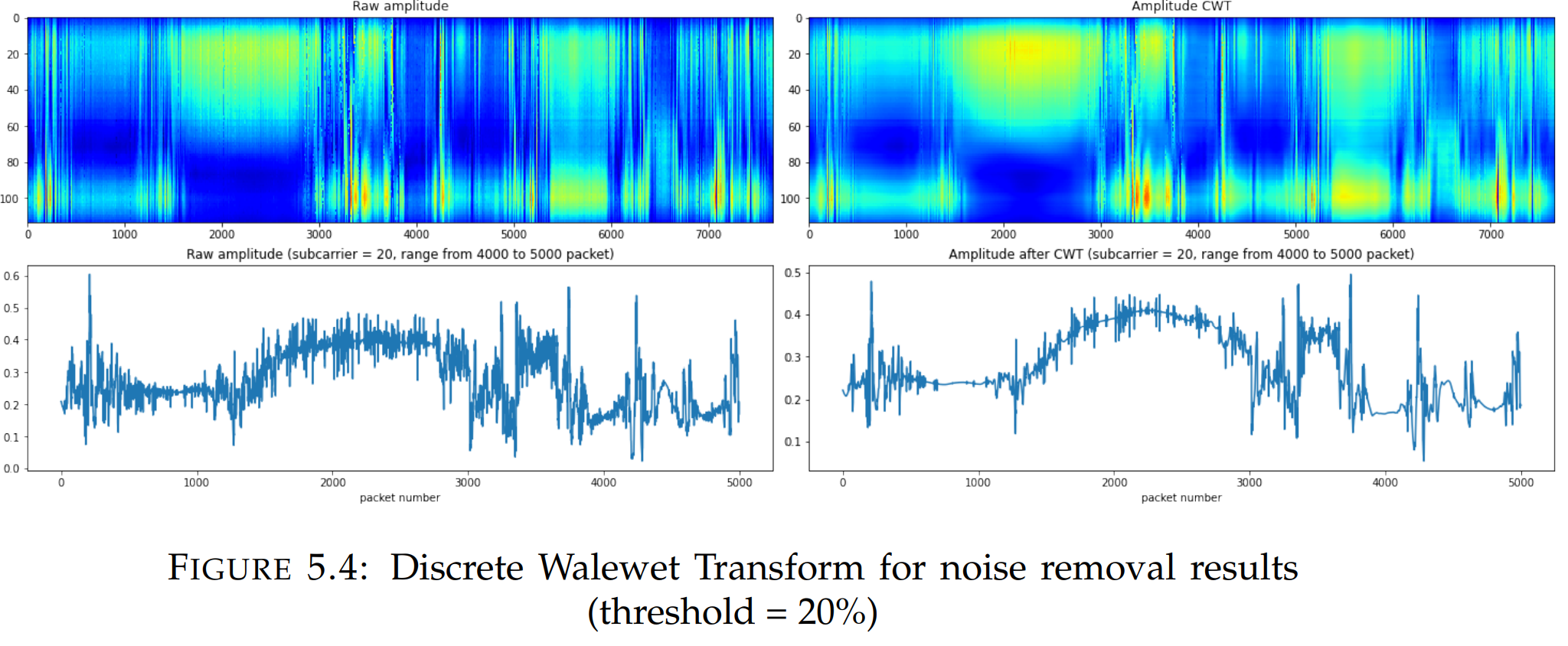
基于离散小波变换的降噪
使用基于离散小波变换的降噪算法。为此目的,使用了Pywt库。效果如图。
模型
总的来说,数据处理和模型的处理流程如图
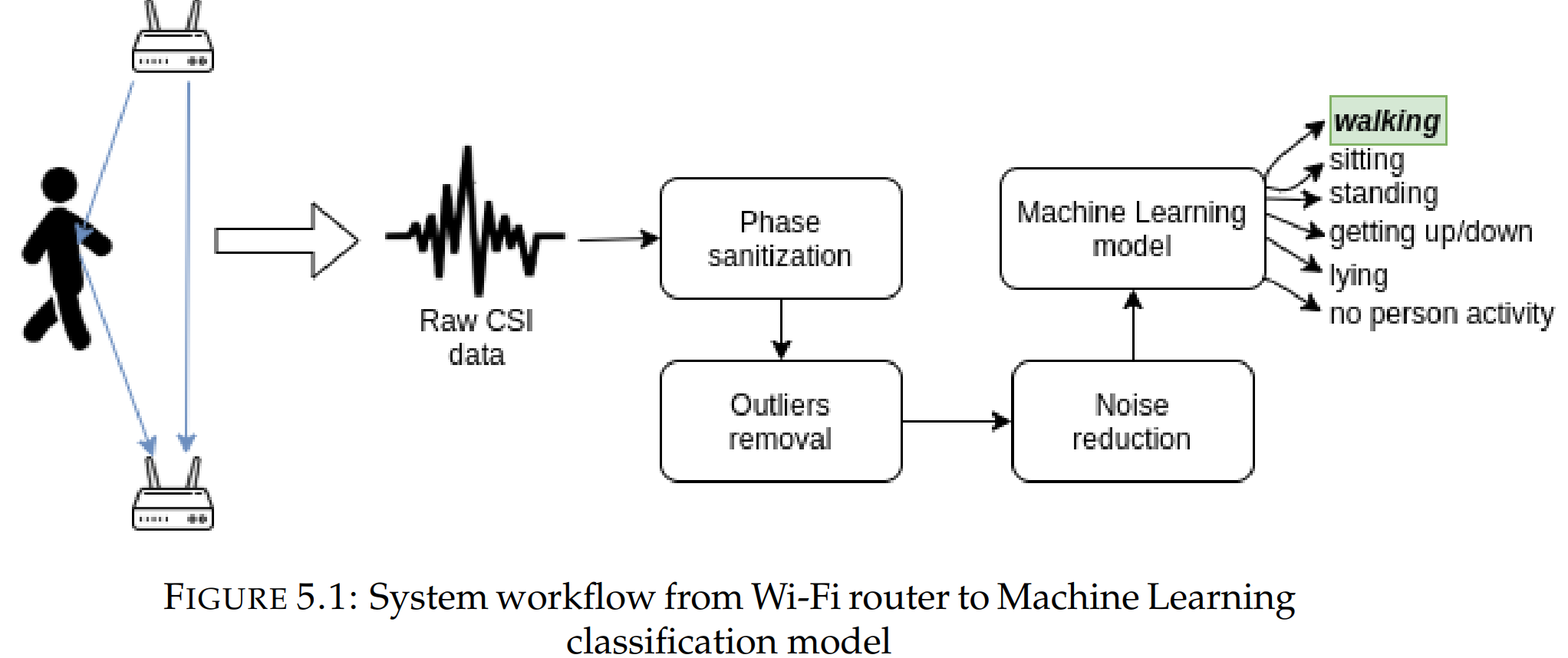
在实验中,接收器路由器和发射器路由器各有两个天线。因此总共有四对天线。每一对天线都有每个子载波的CSI数据(相位和振幅)。因此,我们接收到的每一个CSI包包含 4 * 114 * 2 = 912个特征。这些特征被用于模型训练。
此外,我们需要考虑人们不会立即改变他们的活动,这种过渡可能需要一些时间。 此外,由于环境特性和反射波,模型必须能够学习模式随着时间的推移。 数据作为序列馈入模型,它们之间有若干步之差。 目标是在该序列末尾检测到执行的活动。
InceptionTime 模型
InceptionTime 模型提出了一种基于深度一维卷积神经网络架构,用于时间序列分类问题。他们在其架构精度以及训练时间方面都取得了很有希望的结果,与类似的架构相比,它们更小。
Hassan Ismail Fawaz et al. “InceptionTime: Finding AlexNet for Time Series Classification”. In: (Sept. 2019).
InceptionTime 模型是由 inception 网络组成的集成模型,后面跟着一个全局平均池化层和一个具有 softmax 激活函数的密集层。该模型由以下层组成:
- 一个用于降低输入序列维度的瓶颈层
- 一个大小为 3 的最大池化层,输入也会通过此层
- 瓶颈层的输出被馈送到三个一维 卷积层,卷积核大小分别为 10、20 和 40
- 最大池化层的输出输入到一个单一的一维卷积层, 卷积核大小为 1
- 最后,所有四个卷积层的输出在最后一层进行串联
输入数据为长度为 1024 的 CSI 数据序列。该序列标签是在该序列结束时执行的活动类。第一个卷积层的输入通道数等于(子载波数)*(天线对数)*2 = 1024,其中“2”表示相位和幅度。数据集按序列分段,步长为 8 个时间点。这意味着第二个序列在时间上比第一个序列移动了八个包。
使用交叉熵损失函数作为损失函数。在 Google Colab 的 Nvidia K80 GPU 上进行训练,训练了大约 50 个周期,耗时约 10 小时。
在训练了50个周期后,模型在验证数据上的准确率达到了38.2%;然而,在训练完数据后,它达到了99.2%。我们在这里看到了过拟合的问题,主要原因是可能数据量不足,因为我们尝试了不同的验证和训练子集,但没有得到更好的结果。
LSTM 模型
RNN 模型在序列数据上表现良好,而其 LSTM 改进有助于长期依赖关系。根据这一点,我们使用以下模型架构进行了测试:
- 一个双向 LSTM 层,隐藏层大小为 256
- 五个大小分别为 512、256、128、7 的密集层,以及激活函数为 ReLU。最后一个密集层就是系统的输出。
模型的输入是一段长为 1024 的 CSI 数据序列。该序列标签是在该序列结束时执行的操作。使用它,我们尝试模拟一个实时的 HAR 系统。数据集被划分为以 16 个时间步长为间隔的子序列。这意味着第二个序列在时间上比第一个序列延迟了八个包。
使用交叉熵损失函数。模型使用Python PyTorch框架构建。训练在Google Colab服务上进行,Nvidia K80 GPU。经过60个时期的训练大约需要7个小时。
在模型训练后,其验证数据准确率为61.1%,精确度为59%,召回率为55%,测试数据准确率为87.8%。生成的混淆矩阵如图所示。该模型也受到过拟合的影响,但程度不如前一个模型。此外,准确性要高得多。因此,我们可以得出结论,在没有大量可用训练数据的情况下,基于LSTM的方法在这种情况下效果更好。
