基于WiFi CSI数据检测人体活动
基于WiFi CSI数据检测人体活动
目标为基于WiFi CSI数据,训练深度学习模型实现分类:无人、摔倒、其他人体活动(例如行走)
数据采集
第一次采集

一个样本的格式:
- 数据包数量:1000(浮动)
- 发射器数量:2
- 接收器数量:3
- 载波数:30
单个样本的可视化方法如下,横轴为数据包编号,纵轴为载波数,图像展示的是振幅,展示了所有(发射器,接收器)对,一共6对。
摔倒(一个样本):
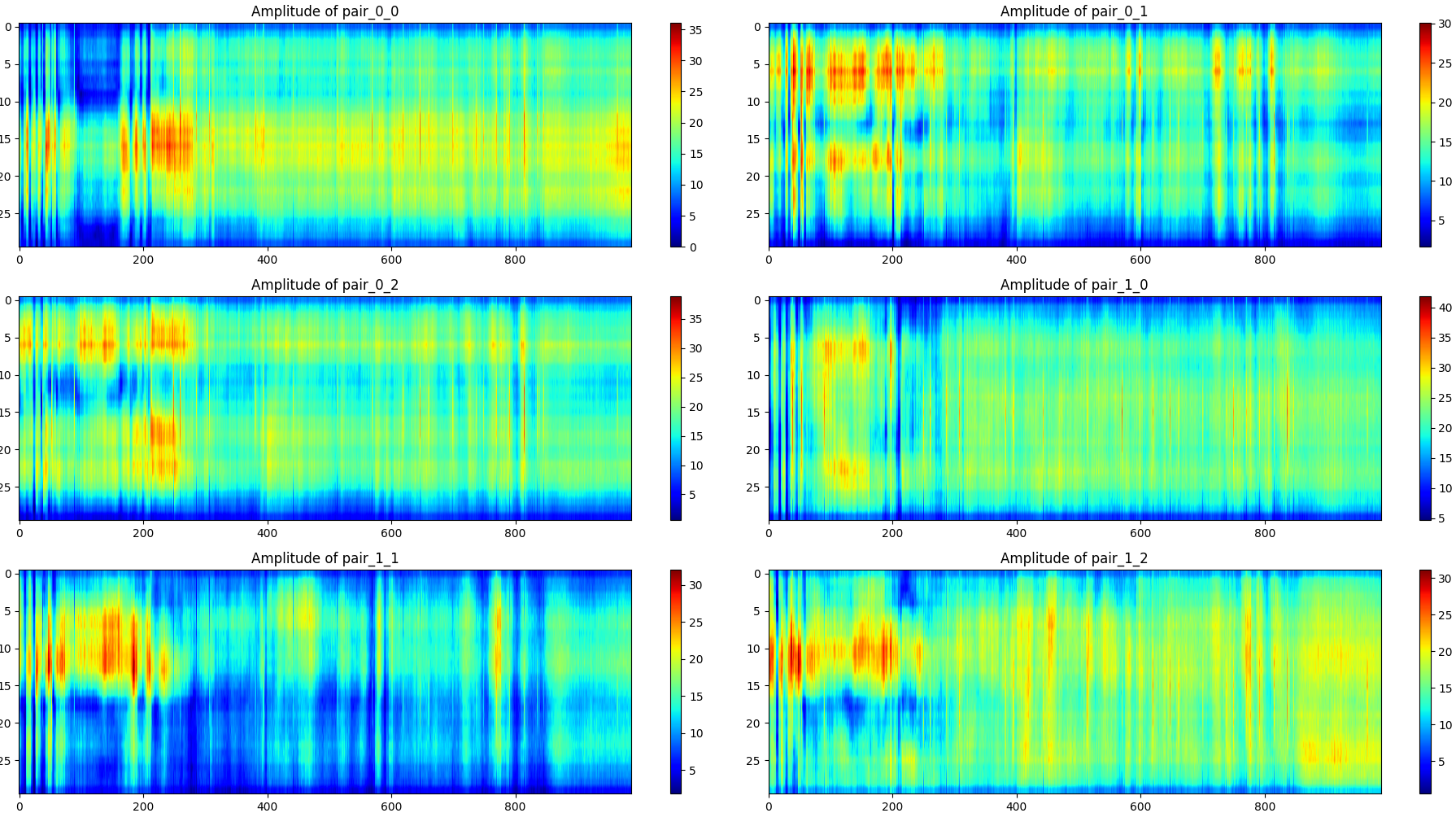
无人(一个样本):
![]()
站立(一个样本):
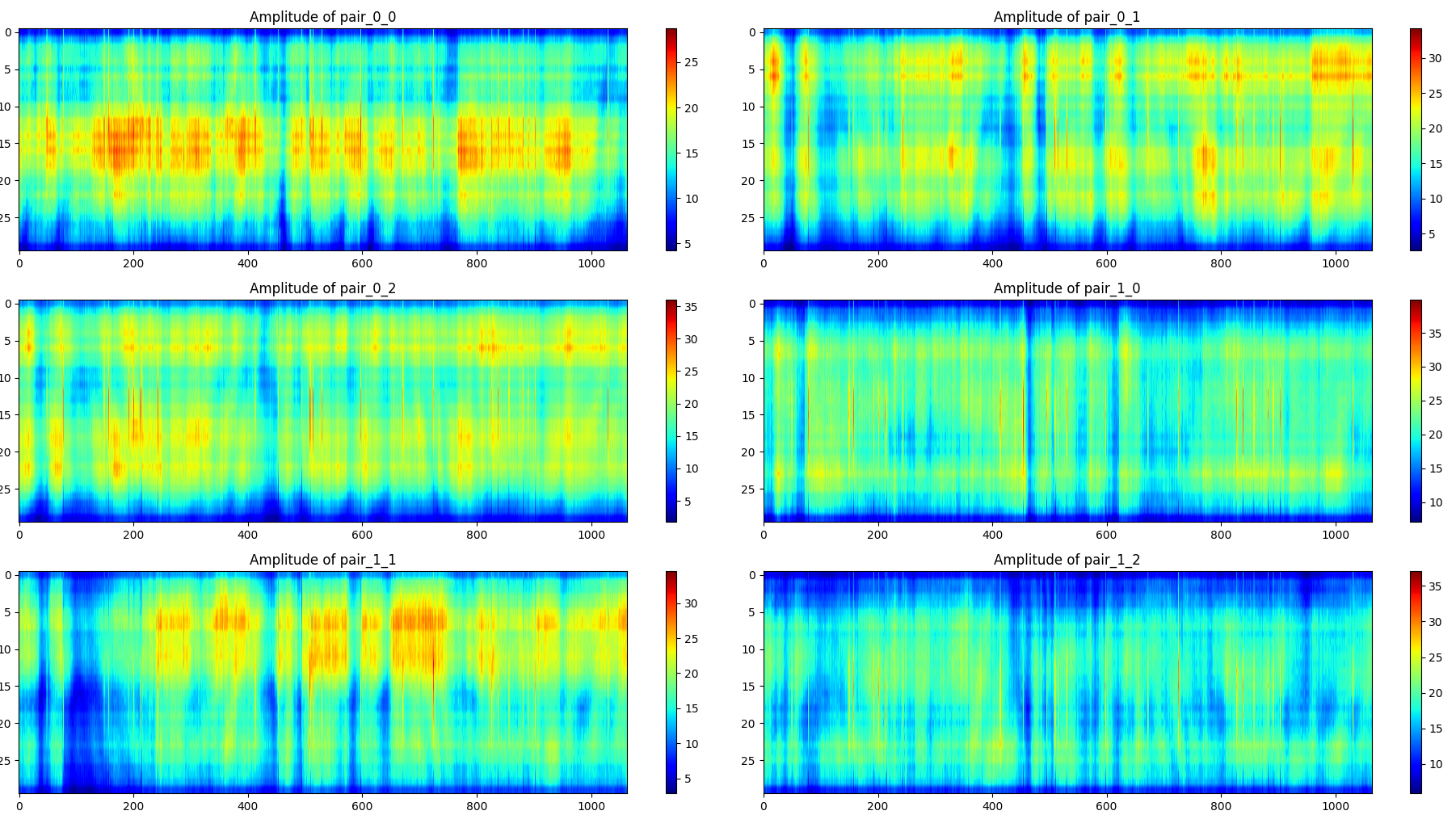
第一次采集的数据样本较少,为实验性质的测试。
第二次采集

样本总数在300左右。一个样本的格式:
- 数据包数量:400(浮动)
- 发射器数量:2
- 接收器数量:3
- 载波数:30
单个样本的可视化方法如下,横轴为数据包编号,纵轴为载波数,图像展示的是振幅,展示了所有(发射器,接收器)对,一共6对。
无人(一个样本):
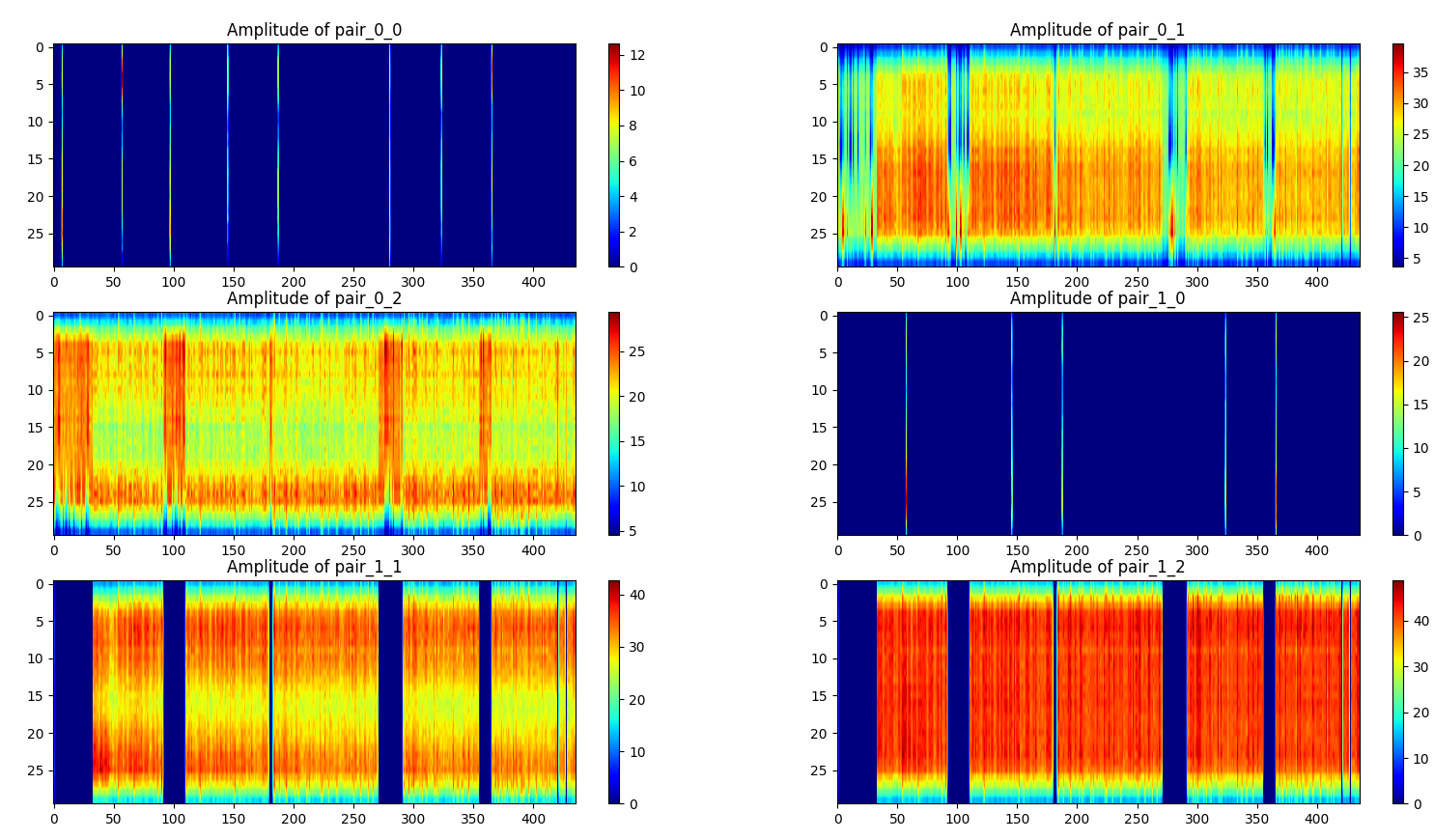
行走(一个样本):
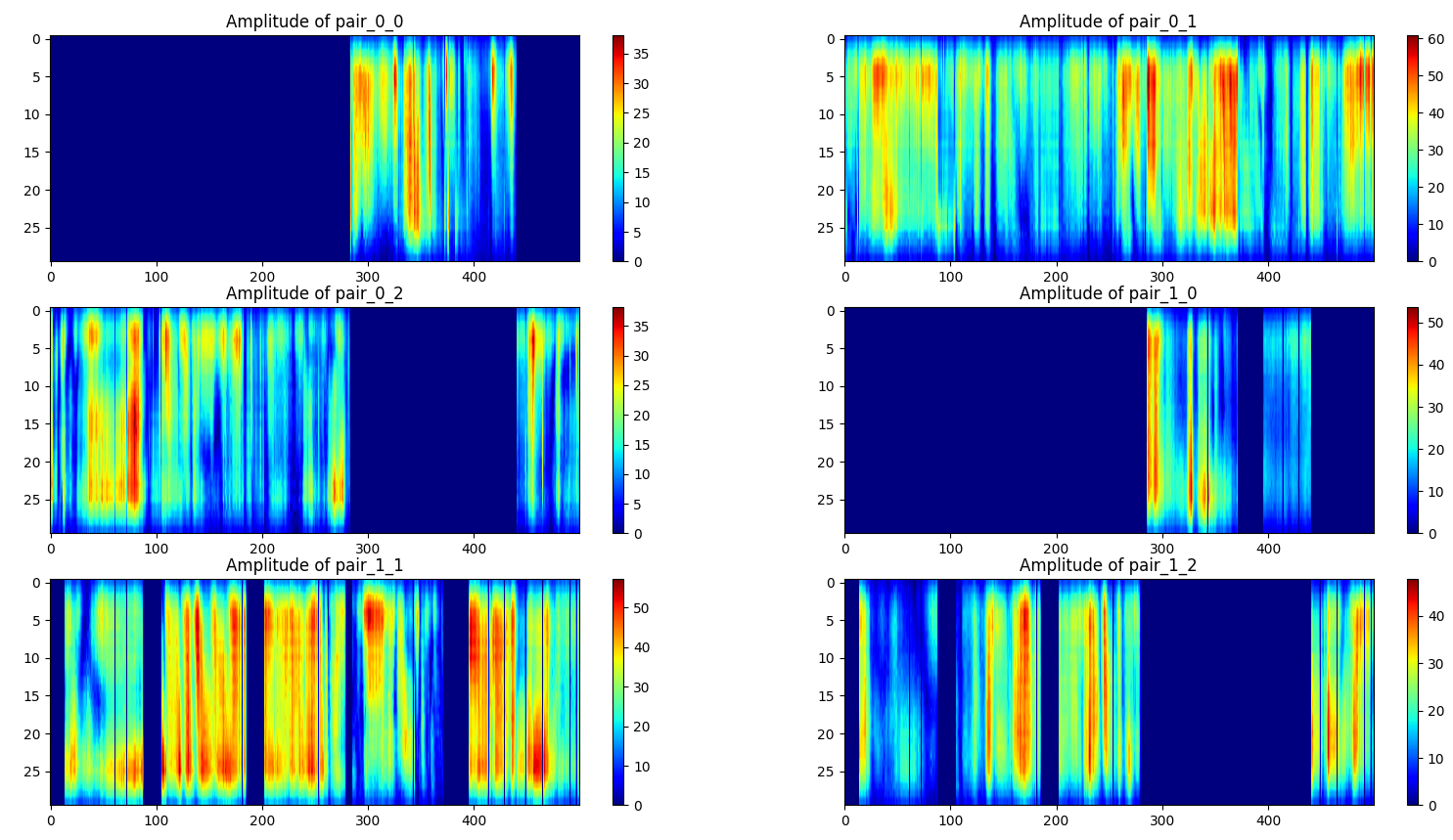
摔倒(一个样本):
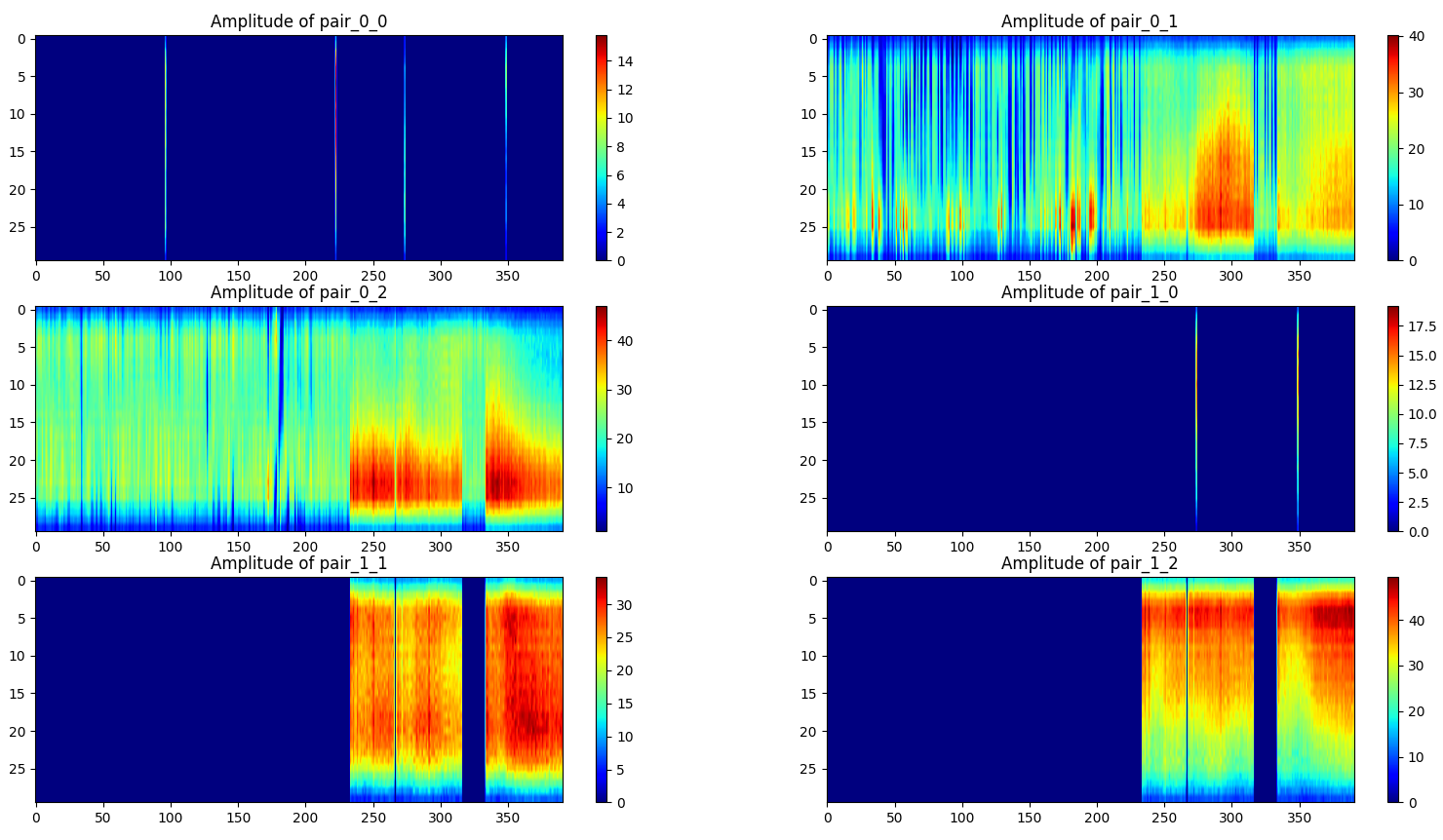
第二次采集数据时使用了新的环境配置方法,但从数据质量上看似乎不如第一次,会有一些(发射器,接收器)对没有信号记录。
数据处理
对第二次采集到的300个样本进行处理:
- 对于数据包数量小于400的样本,忽略。
- 对于数据包数量大于等于400的样本,截取中间的400个数据包。
- 对每个样本的6个(发射器,接收器)对进行数值上的相加(由于上面提到的,有些对没有信号记录),因此每个样本的维度为(数据包数量,载波数)
- 对每个样本进行归一化。
当环境中有人的存在时,大约一半的样本中数据包小于400,为了利用更多的样本,在几次实验中改为忽略“数据包数量小于380的样本”
处理后的每个类别的数据:

模型
- 代码仓库
- 前置知识:BiLSTM
- 前置知识:Transformer
BiLSTM

调参记录:
| Learning rate | Hidden dim | Num layers | Dropout | Bidirectional | Training Accuracy | Validation Accuracy |
|---|---|---|---|---|---|---|
| 0.0005 | 256 | 2 | 0.2 | TRUE | 1 | 0.84 |
| 0.0005 | 256 | 1 | 0.2 | TRUE | 1 | 0.84 |
| 0.0005 | 128 | 1 | 0.2 | TRUE | 1 | 0.84 |
| 0.0005 | 128 | 1 | 0.4 | TRUE | 1 | 0.84 |
| 0.0005 | 64 | 1 | 0.2 | TRUE | 1 | 0.81 |
| 0.0005 | 256 | 2 | 0.2 | FALSE | 1 | 0.79 |
| 0.0005 | 256 | 1 | 0.2 | FALSE | 1 | 0.79 |
| 0.001 | 256 | 2 | 0.2 | TRUE | 0.6626 | 0.6818 |
每个批次损失:

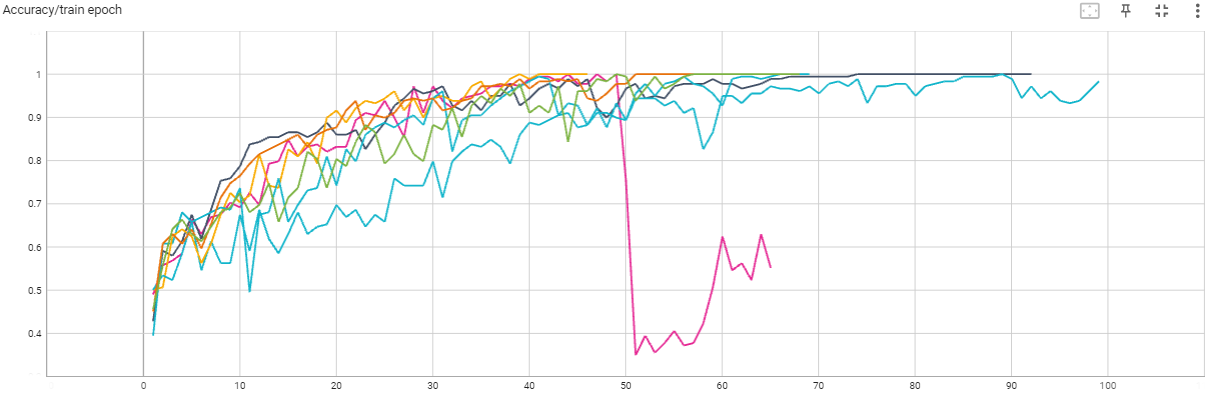
每代(epoch)训练集准确率:
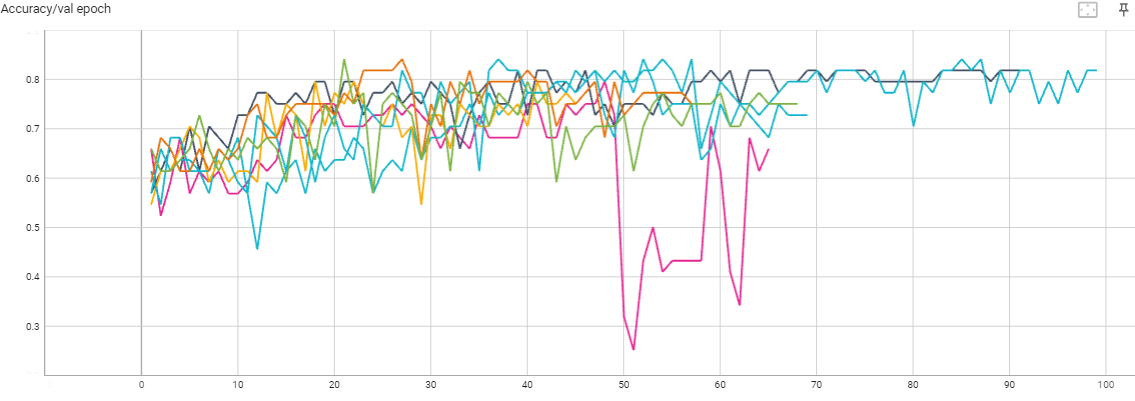
每代(epoch)验证集准确率:
其他信息:
- 损失函数:交叉熵损失(Softmax分类器)
- 优化器:Adam
- 正则化:使用Dropout,权重衰减
- 参数量(最好的模型):205187
- 参数初始化:Xavier初始化
- 样本量:约300,每个类别约100(共3类),训练集与验证集比例为4:1
- 数据集大小:约26MB
- GPU:RTX4090
- 显存消耗:4G足够
- 训练时间:训练到收敛小于10分钟
Transformer

调参记录:
| Value Dimension | Attention Dimension | Decode Sequence Length | Decode Layers | Encode Layers | Heads | Learning Rate | Weight Decay | Training Accuracy | Validation Accuracy |
|---|---|---|---|---|---|---|---|---|---|
| 32 | 16 | 4 | 4 | 4 | 4 | 0.0001 | 0 | 1 | 0.96 |
| 32 | 16 | 8 | 4 | 4 | 4 | 0.0001 | 0 | 1 | 0.96 |
| 32 | 16 | 4 | 2 | 2 | 2 | 0.001 | 0 | 1 | 0.94 |
| 16 | 8 | 4 | 2 | 2 | 2 | 0.001 | 0 | 1 | 0.88 |
| 10 | 5 | 8 | 3 | 3 | 3 | 0.001 | 0 | 1 | 0.81 |
| 10 | 5 | 4 | 2 | 2 | 2 | 0.001 | 0 | 1 | 0.81 |
| 16 | 8 | 4 | 4 | 4 | 4 | 0.001 | 0 | 1 | 0.81 |
| 16 | 8 | 4 | 2 | 2 | 4 | 0.001 | 0 | 1 | 0.81 |
| 10 | 5 | 16 | 3 | 3 | 3 | 0.001 | 0 | 1 | 0.79 |
| 10 | 5 | 4 | 3 | 3 | 3 | 0.001 | 0 | 1 | 0.79 |
| 16 | 8 | 4 | 2 | 2 | 2 | 0.001 | 0.01 | 0.99 | 0.79 |
| 10 | 5 | 1 | 3 | 3 | 3 | 0.001 | 0 | 0.98 | 0.77 |
| 10 | 5 | 100 | 3 | 3 | 3 | 0.001 | 0 | 1 | 0.77 |
| 10 | 5 | 3 | 3 | 3 | 3 | 0.001 | 0.01 | 0.98 | 0.77 |
| 16 | 8 | 4 | 1 | 1 | 2 | 0.001 | 0 | 1 | 0.75 |
| 10 | 5 | 300 | 3 | 3 | 3 | 0.001 | 0 | 1 | 0.68 |
| 32 | 16 | 4 | 4 | 4 | 4 | 0.001 | 0 | 无法收敛 | 无法收敛 |
各个参数的意义:
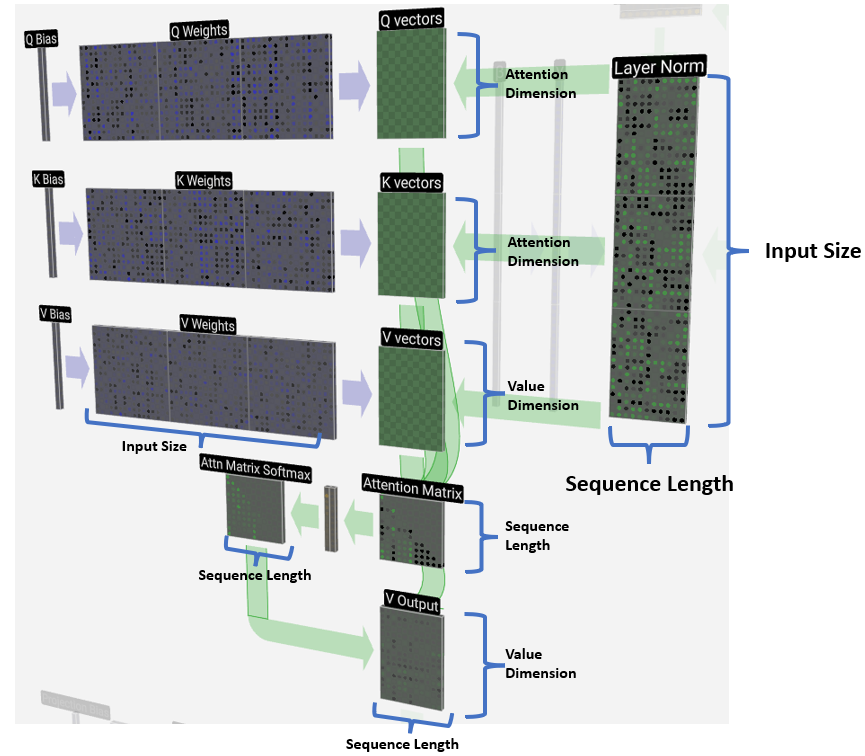
每个批次损失:

每代(epoch)训练集准确率:

每代(epoch)验证集准确率:

其他信息:
- 损失函数:交叉熵损失(Softmax分类器)
- 优化器:Adam
- 正则化:使用L2正则化,layer normalization(Transformer),权重衰减
- 参数量(最好的模型):168003
- 样本量:约300,每个类别约100(共3类),训练集与验证集比例为4:1
- 数据集大小:约26MB
- GPU:RTX4090
- 显存消耗:4G足够
- 训练时间:训练到收敛小于10分钟
本文由作者按照 CC BY 4.0 进行授权