LangChain 🦜️🔗 与知识增强生成
Knowledge augment prompt(知识增强提示)是一种用于在生成文本任务中引入外部知识 以提高生成文本的质量和准确性的技术。该技术可以与语言模型结合使用,以增强模型的能 力。
在传统的生成文本任务中,模型只能基于其已经学习到的训练数据进行生成。然而,训练数 据可能是有限或不完整的,导致生成的文本可能缺乏准确性或相关性。Knowledge augment prompt 的目标就是通过引入外部知识,使模型能够利用更广泛和准确的信息来生 成文本。

在文档部分的知识增强,最常用的就是检索增强生成(Retrieval-Augmented Generation)。
工作流程
RAG的整个工作流程大致是这样的:
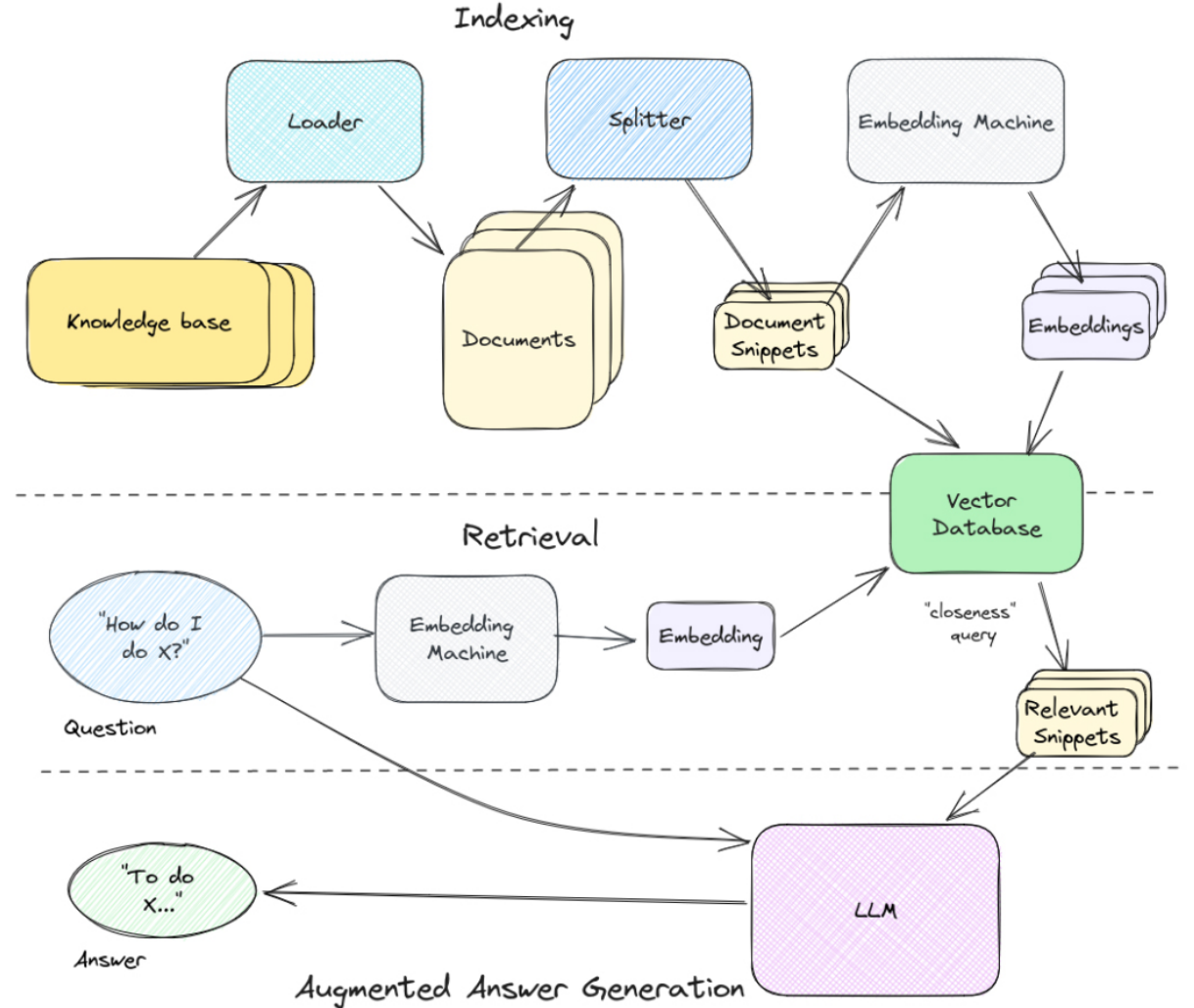
首先,索引知识库。获取知识并使用加载器将其转换为单独的文档,然后使用拆分器将其转 换为一口大小的块或片段。一旦有了这些,就把它们传递给嵌入机,嵌入机将它们转换成可 用于语义搜索的向量。将这些嵌入及其文本片段保存到矢量数据库中。
接下来是检索。它从问题开始,然后通过相同的嵌入机发送并传递到矢量数据库以确定最接 近的匹配片段,随后将用它来回答问题。
最后,增强答案生成。首先会获取知识片段,然后将它们与自定义系统提示和提出的问题一 起格式化,最后得到上下文特定的答案。
在langchain中封装了许多软件包能够让我们更方便的使用RAG,因此我们可以使用 langchain创建一个RAG QA链,下面是用langchain创建RAG QA链的一个简单示例,我们在接下来讲解原理的同时会详细讲解示例中的每一个步骤。
1
2
3
4
5
6
import os
from openai import OpenAI
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:xxxxx'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:xxxxx'
os.environ["OPENAI_API_KEY"] = "xxxxxxxxxxxxxxxxxxxxxxxxxxxx"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain import hub
# Load documents
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
# Split documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
splits = text_splitter.split_documents(loader.load())
# Embed and store splits,Chroma 是一个用于构建带有嵌入向量的 AI 应用程序的数据库
vectorstore = Chroma.from_documents(documents=splits,embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
# Prompt
# https://smith.langchain.com/hub/rlm/rag-prompt
rag_prompt = hub.pull("rlm/rag-prompt")
# LLM
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# RAG chain
from langchain.schema.runnable import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
)
rag_chain.invoke("What is Task Decomposition?")
1
AIMessage(content='Task decomposition is the process of breaking down a task into smaller subgoals or steps. It can be achieved through various methods such as using LLM with simple prompting, task-specific instructions, or human inputs. Challenges in long-term planning and task decomposition include planning over a lengthy history and adjusting plans when faced with unexpected errors.')
知识索引
为知识库建立初始索引,索引过程可归结为两个高级步骤:
- 加载:从通常存储的位置获取知识库的内容。
- 分割:将知识分割成适合嵌入搜索的片段大小的块。
加载机是 LangChain 最有用的部件之一。它们提供了一长串内置加载器,可用于从Microsoft Word 文档到整个 Notion 站点的任何内容中提取内容。在我们上面的例子中,使用了WebBaseLoader加载器,它可以从互联网上的任何网站上提取内容。
1
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")

此外:langchain中提供了许多加载机,使用方法详见文档:
- 最简单的文本加载器(TextLoader)
- CSV加载器
- 从文件目录中加载:也可以从目录中加载所有文档
- HTML加载器
- JSON加载器
- Markdown加载器
- PDF加载器
在 LangChain 中,切片器属于一个更大的类别,称为“文档转换器”(Document Transformer)。除了提供各种分割文档的策略之外,他们还提供删除冗余内容、翻译、添 加元数据等工具。在此处只关注切片器,因为它们代表了绝大多数文档转换。
从加载器出来的文档,可能包含很多内容,包含的内容越多,文档的嵌入就越“不具体”,这 意味着紧密度”搜索算法可能不太有效。通过分割,切片器将任何单个文档分割成小块的、 可嵌入的块,更适合搜索。
切片后得到的文档片段将被保存到向量数据库中,到此就完成了知识库的索引创建。
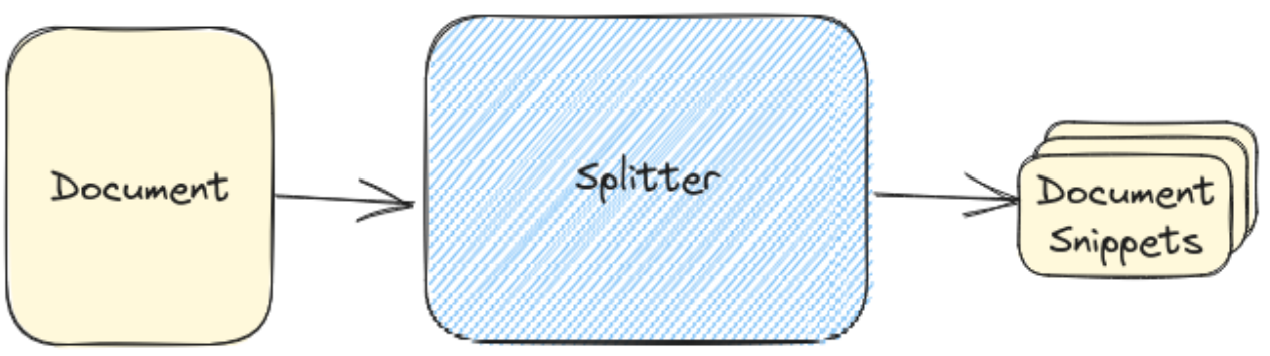
在langchain中,可以采用最简单的RecursiveCharacterTextSplitter来将Document分 割成块以进行嵌入和向量存储。例如我们上面的例子:
1
2
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
splits = text_splitter.split_documents(loader.load())
以下是langchain中的一些切割方式:
- HTML标题文本分割器(HTMLHeaderTextSplitter):元素级别拆分文本,并为每个与任何给定块“相关”的标头添加元数据。
- 按字符分割(CharacterTextSplitter):这是最简单的方法。基于字符(默认为“\n\n”)进行分割,并按字符数测量块长度。
- 拆分代码:CodeTextSplitter 允许您使用支持的多种语言拆分代码。导入枚举 Language并指定语言。
- Markdown标题文本分割器(MarkdownHeaderTextSplitter):Markdown 文件是按标题组织的。可以使用MarkdownHeaderTextSplitter将Markdown 文件按一组指定的标头拆分 。
- 按字符递归分割(RecursiveCharacterTextSplitter):对于一般文本,推荐使用此文本分割器。它由字符列表参数化。它尝试按顺序分割它们,直到块足够小。默认列表是[“\n\n”, “\n”, “ “, “”] . 这样做的效果是尝试将所有段落(然后是句子,然后是单词)尽可能长时间地放在一起,因为这些通常看起来是语义相关性最强的文本片段。
- 按Token分割:语言模型有一个令牌限制,不可超出令牌限制。因此,将文本拆分为块时,最好计算标记的数量。有很多标记器可以使用,所以当计算文本中的标记时,应使用与语言模型中使用的相同的标记生成器。
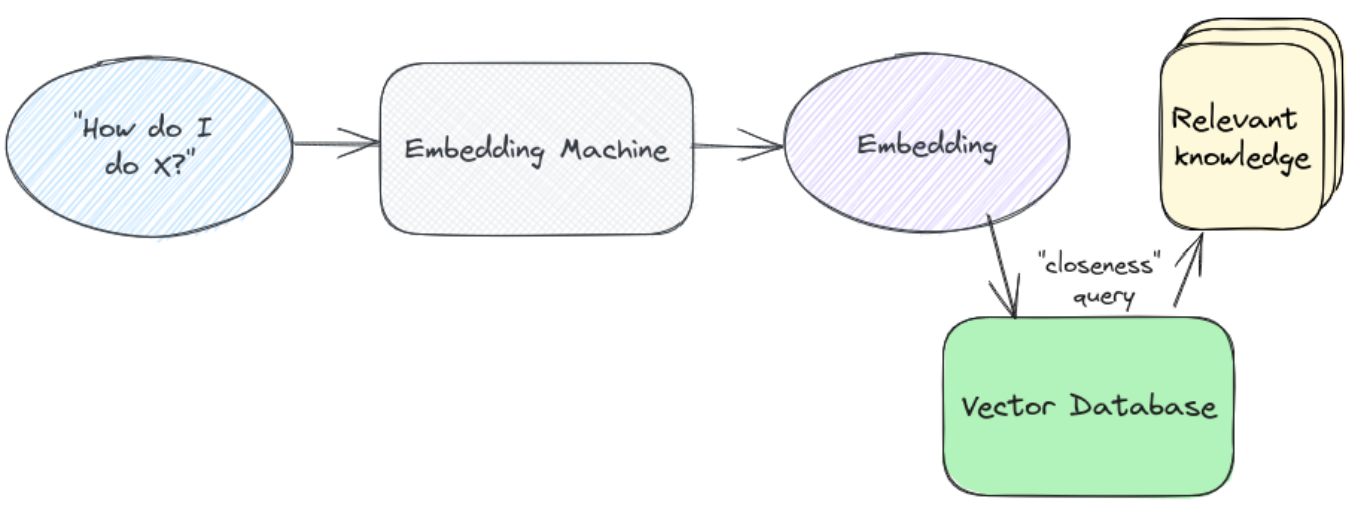
知识检索
经过上述索引操作后,便有了发送给大语言模型的正确的知识片段。但是如何从用户的问题中真正得到这些呢?这时候便需要用到检索,下图是检索步骤的示意图,它是任何“与数据聊天”系统中基础设施的核心部分。

从本质上讲,检索是一种搜索操作 —— 根据用户的输入查找最相关的信息。就像搜索一样,有两个主要部分:
- 索引:将您的知识库变成可以搜索/查询的内容。
- 查询:从搜索词中提取最相关的知识。
值得注意的是,任何搜索过程都可以用于检索。任何接受用户输入并返回一些结果的东西都 可以工作。因此,举例来说,您可以尝试查找与用户问题相匹配的文本并将其发送给大语言 模型,或者您可以通过 Google 搜索该问题并将最重要的结果发送出去 —— 顺便说一句,这 大约就是 Bing 聊天机器人的工作原理。
当今大多数 RAG 系统都依赖于语义搜索,它使用人工智能技术的另一个核心部分: Embedding(嵌入)
嵌入
在大语言模型的世界中,任何人类语言都可以表示为数字向量(列表)。这个数字向量就是一个嵌入。相似的单词最终会得到相似的数字组。在这个假设的语言空间中,两点彼此越接近,它们就越相似。可以进行基本数学计算来确定两个嵌入(以及两段文本)彼此之间的接近程度。
在完成知识的切片后,将每个知识片段通过嵌入机器(实际上是 OpenAI API 或类似机器)传递,并返回该文本的嵌入表示。然后,保存该片段以及向量数据库中的嵌入,该数据库针对数字向量进行了优化。

在langchain中,为了能够找到分割好的文档切片,需要把他们存到稍后能找到他们的地方。最普遍的方式是把每个切片的内容都嵌入,然后把切片和嵌入都存到矢量库中。
1
2
3
# Chroma 是一个用于构建带有嵌入向量的 AI 应用程序的数据库
vectorstore = Chroma.from_documents(documents=splits,embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
在查询时,首先获得用户输入的嵌入,找到向量空间中最接近的片段,提取发送给大语言模型。
langchain中提供了一些查询搜索方法:
1
2
3
4
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
len(docs) # 有多少个Document与问题相似
1
4
此外,LangChain有很多检索器 ,包括但不限于向量库,包括多查询检索器(MultiQueryRetriever) 、上下文压缩(Contextual compression) 等等
再说一说嵌入模型,嵌入模型将文本作为输入,并返回一个浮点数列表。实际上就是把文本等内容转成多维数组,可以后续进行相似性的计算和检索。
LangChain中集成了很多来自不同平台的API可以进行词嵌入编码,例如HuggingFaceHub、TensorFlowHub等,这里举一个用OpenAi进行词嵌入的方法:
1
2
3
4
5
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
res = embeddings.embed_query('hello world')
print(len(res)) # 维度为 1536
1
1536
答案生成
现在已经从知识库中提取了我们认为可以回答问题的相关信息。那么我们如何使用它来生成答案?

第一个组成部分是系统提示。系统提示给予语言模型整体指导。对于 ChatGPT,系统提示 类似于“你是一个有用的助手”。在这种情况下,我们希望它执行更具体的操作。一个简短的系统提示示例如下:
1
2
“你是一个知识机器人。您将获得知识库的提取部分(标有文档)和一个问题。使用知识库中的
信息回答问题。”
接下来,需要为AI提供阅读材料。可以通过一些结构和格式来帮助AI理解和解决问题,以 下是可以用来将文档传递给LLM的示例格式:
1
2
3
4
5
6
7
8
9
10
11
------------ DOCUMENT 1 -------------
This document describes the blah blah blah...
------------ DOCUMENT 2 -------------
This document is another example of using x, y and z...
------------ DOCUMENT 3 -------------
[more documents here...]
保持一致的格式变得很重要,一旦格式化了文档,便只需将其作为普通聊天消息发送给 LLM。在编辑系统提示时我们告诉它我们要给它一些文件,这里编辑好格式的文档便是要送入LLM的文件。
在编辑好系统提示和“文档”消息后,只需将用户的问题与它们一起发送给大语言模型即可。 以下是使用 OpenAI ChatCompletion API 在 Python 代码中的样子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
openai_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": get_system_prompt(), # the system prompt as per above
},
{
"role": "system",
"content": get_sources_prompt(), # the formatted documents as per above
},
{
"role": "user",
"content": user_question, # the question we want to answer
},
],
)
就是这样!一个自定义系统提示,两条消息,您就可以得到特定于上下文的答案!
这是一个简单的用例,可以对其进行扩展和改进。如果在来源中找不到答案该怎么办?可以 将一些指令添加到系统提示中,通常是告诉它拒绝回答,或者使用它的常识,具体取决于 AI所需的行为。您还可以让大语言模型引用其用于回答问题的具体来源。
在langchain中可以使用 LLM/Chat 模型将检索到的文档提炼为答案(例如gpt-3.5- turbo)。我们使用Runnable协议来定义链。可运行协议以透明的方式将组件连接在一 起。langchain提供了 RAG 提示,例如我们上面的代码:
1
2
3
4
5
6
7
8
9
10
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# RAG chain
from langchain.schema.runnable import RunnablePassthrough
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
)
rag_chain.invoke("What is Task Decomposition?")
除了可以在提示中心加载提示,也可以自定义提示。如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from langchain.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
rag_prompt_custom = PromptTemplate.from_template(template)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt_custom
| llm
)
rag_chain.invoke("What is Task Decomposition?")
1
AIMessage(content='Task decomposition is the process of breaking down a task into smaller subgoals or steps, which can be done using LLM with simple prompting, task-specific instructions, or human inputs. It helps in organizing and tackling complex tasks effectively. Thanks for asking!')
在有了这些基础后,可以前往官网替换想要的加载器、切片器、嵌入器、检索器、提示器等,以及自定义自己的RAG QA链。玩的开心!