训练 MSVQA 与分析
运行项目方法
我们模型的代码仓库:Gitee,首先需要获取项目源代码并且放到深度学习服务器上。
准备数据集
- MSVD-QA下载网址(需要上网下载)
- 视频文件下载网站,拉到底选择YouTubeClips.tar
- youtube_mapping.txt 下载网址(需要上网下载)
步骤:
- 第一个链接会下载下来一个压缩包,解压,里面有一个
video文件夹。 - 把第二个链接下载的所有视频放到
video文件夹下。 youtube_mapping.txt放在MSVD-QA文件夹下。- 将整个MSVD-QA文件夹上传到服务器代码文件夹下的
data文件夹下。
MSVD-QA文件夹结构:
1
2
3
4
5
6
7
8
9
10
11
12
.
│ readme.txt
│ test_qa.json
│ train_qa.json
│ val_qa.json
│ youtube_mapping.txt
│
└─video
-4wsuPCjDBc_5_15.avi
-7KMZQEsJW4_205_208.avi
-8y1Q0rA3n8_108_115.avi
-8y1Q0rA3n8_95_102.avi
预处理
处理视觉特征:
首先从pretrained model下载 resnext-101-kinetics.pth,这是resnext的权重文件,之后就不用预训练了。将.pth文件放入data/文件夹中。
1
2
3
4
5
6
7
8
9
10
11
python preprocess/preprocess_videos.py --annotation_file data/msvd-qa/train_qa.json --model resnet101
python preprocess/preprocess_videos.py --annotation_file data/msvd-qa/train_qa.json --model resnext101
python preprocess/preprocess_videos.py --annotation_file data/msvd-qa/val_qa.json --model resnet101
python preprocess/preprocess_videos.py --annotation_file data/msvd-qa/val_qa.json --model resnext101
python preprocess/preprocess_videos.py --annotation_file data/msvd-qa/test_qa.json --model resnet101
python preprocess/preprocess_videos.py --annotation_file data/msvd-qa/test_qa.json --model resnext101
处理问题:
下载glove pretrained 300d word vectors 到data/glove/ 然后处理为 pickle 文件:
1
python txt2pickle.py
然后处理问题:
1
2
3
4
5
python preprocess/preprocess_questions.py --dataset msvd-qa --glove_pt data/glove/glove.840.300d.pkl --mode train
python preprocess/preprocess_questions.py --dataset msvd-qa --mode val
python preprocess/preprocess_questions.py --dataset msvd-qa --mode test
–output_dir /root/autodl-fs
做完这一步之后,data文件夹下应该如下:
1
2
/msvqa/data# ls
glove msvd-qa resnext-101-kinetics.pth
1
2
3
msvqa/data/msvd-qa# ls
frames msvd-qa_val_questions.pt train_qa.json video
msvd-qa_train_questions.pt msvd-qa_vocab.json val_qa.json youtube_mapping.txt
训练模型
在options文件夹中修改训练参数,然后:
1
python train.py --msvd_data_path ./data/msvd_qa_data
模型分析
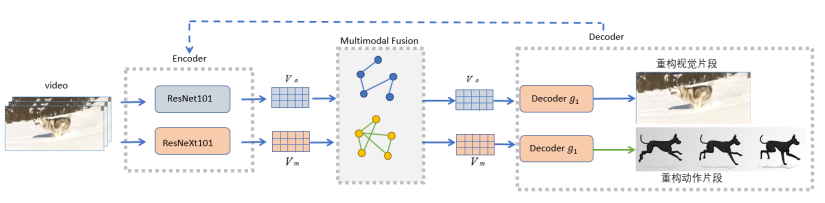
我们完整的模型图如下:
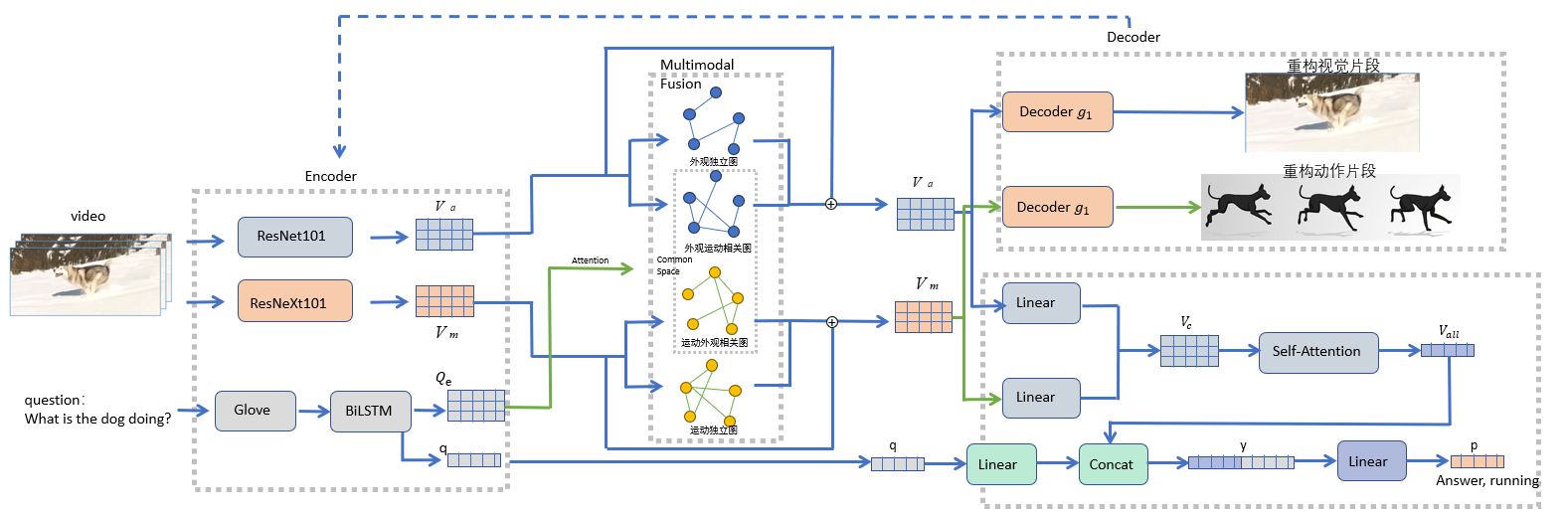
一共分为四个模块:
- 编码器模块负责提取了视频静态的外观特 征和动态的动作特征以及问题的特征提取;
- 多模态融合模块负责将通道内的关系和通道 间的联系合并到外观和运动特征中;
- 答案生成模块负责将视觉外观特征和视觉动作特征 进行融合,再将视频中的每一个片段特征进行了融合,最后特征维度映射为答案分类数 目;
- 自编码器模块可以更好地提升编码器模块的特征提取效果与多模态融合模块的融合 效果。
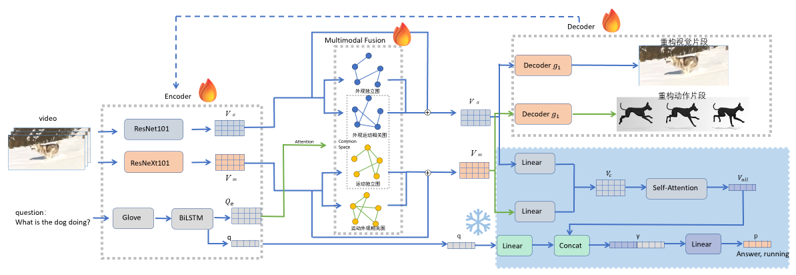
编码器模块
视频方面,将一个视频进行均匀地切分,每个视频表示为 c 个连续的片段,每个片 段包含了 f 帧的图像,图图像的像素大小固定为 h×w,通过预训练模型分别提取了视频静态的外观特征和动态的动作特征,最终所得到的外观特征表示 $V_a$,动作特征表示 $V_m$。其中,选用了 ResNet101 来提取视频静态的外观特征。选用了 ResNeXt101 来提取视频动态的动作特征。
ResNet101 是深度残差网络 (Residual Network)系列中的一个较深、较复杂的模型,具有 101 层深度。ResNet101 在图像处理领域被广泛应用,并在许多任务中取得了优秀的表现。它通过残差连接和 跳跃连接的设计,克服了深度神经网络训练中的梯度消失和梯度爆炸问题,使得网络 可以更好地学习到有效的特征表示。并且由于 ResNet101 在大规模图像数据集上进行 了预训练,它可以提供具有较高泛化能力的特征表示。这使得我们可以利用这些预训 练的权重,在较小规模的视频数据集上进行微调或迁移学习,从而加快训练过程并提高模型性能。 更多理论细节:Deep Residual Learning for Image Recognition
ResNeXt101 是在 ResNet 的基础 上进一步发展而来的模型,采用了类似 Inception 模块的结构,将多个分支 (cardinality)并行使用,从而增加网络的宽度和信息交互的能力。相比于传统的 ResNet 结构,ResNeXt101 在保持模型深度不变的情况下,通过增加网络的宽度和并行 性,进一步提升了模型的特征提取能力和表示能力。这种设计可以更好地利用现代 GPU 并行计算的优势,提高训练效率,并在一定程度上减少了参数量。更多理论细节:Aggregated Residual Transformations for Deep Neural Networks
文本方面,首先将训练集中所有问题出现的高频单词整理为词汇表,通过词汇表对 单词进行唯一编码,以此每个句子可以表示为一串单词索引序列。使用预训练的 GloVe 词向量表对问题中的每一个单词进行编码表示。将每一个单词表示为 300 维特征向量,便得到了问题的单词特征 $Q_w$。分别使用了两个 BiLSTM 来提取句子的嵌入 特征 $Q_e$ 和语义特征 q。
选用了 Glove 模型完成问题的词嵌入。GloVe(Global Vectors for Word Representation)是一种用于学习词向量表示的模型,旨在利用全局的词汇统计信息来 学习每个词的分布式表示,使得相似语义的词在向量空间中更加接近。GloVe 模型基于词共现矩阵,通过最小化词向量空间中词向量之间的点积和对数词频之间的差异来 训练词向量。这种方法结合了基于全局统计信息和基于局部上下文的方法,既考虑了词与词之间的关联性,又能够捕捉到词在不同上下文中的语义信息。更多理论细节:GloVe:Global Vectors for Word Representation
选用了 BiLSTM 来完成问题的特征提取。双向长短时记忆网络(Bidirectional Long Short-Term Memory,BiLSTM)是一种深度学习模型,常用于序列数据的建模和处 理。BiLSTM 模型结合了正向和反向两个方向的 LSTM(长短时记忆网络),能够捕 捉序列数据中的双向依赖关系,并在很多自然语言处理任务中取得较好的性能。简单 来说,BiLSTM 模型由两个方向的 LSTM 组成,分别沿着时间序列前向和后向进行处 理。这样,在每个时间步,模型可以同时考虑当前时刻之前和之后的信息,从而更好 地理解序列数据中的上下文信息。更多理论细节:双向长短期记忆神经网络
多模态融合模块
外观和运动通道对于视频理解都至关重要。为了充分揭示这两个通道中的补充信息, 我们不仅需要从视频剪辑中提取外观和运动特征,还需要考虑每个通道内视频剪辑之间 的关系以及每个视频剪辑两个通道之间的关系。为此,模型的多模态融合部分将通道内 的关系和通道间的联系合并到外观和运动特征中。
通过将各个片段作为节点,将两个片段之间的特征值拼接后组为边,一共构建了四个多头图注意力网络。在外观通道中,我们构建了两个无向完整图网络,包括外观独立 图和外观运动相关图;对于运动通道,我们也使用两个图网络来学习上下文嵌入,包括 运动独立图和运动外观相关图。它们的目标与外观通道中的图形相同。外观运动相关图 和运动外观相关图形成了公共空间。句子的嵌入特征$Q_e$用于了每个多头图注意力网络 的注意力部分。最后采用了残差连接,将基于关系推理过程的结果特征与最初提取的视 觉特征进行相加。
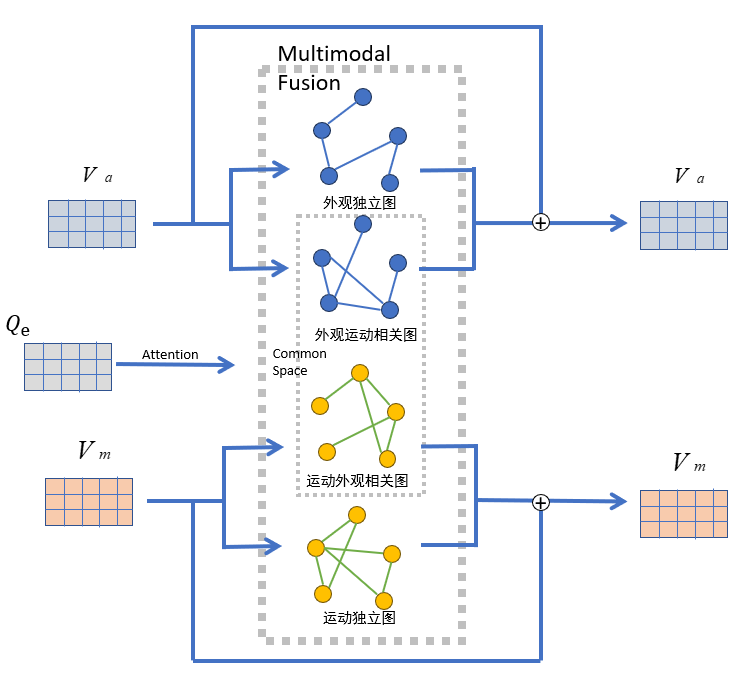
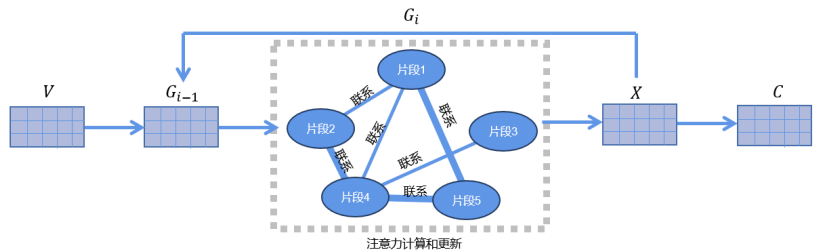
其中,图注意力网络(Graph Attention Network,简称 GAT)是一种深度学习模型, 用于处理图数据,尤其是节点具有复杂关系的图数据,比如社交网络、推荐系统中的用 户-物品关系等。GAT 基于注意力机制,它允许模型在学习图数据时专注于重要的节点, 从而更好地捕获节点之间的关系。与传统的图卷积网络(GCN)相比,GAT 引入了注意力系数,通过学习权重来指导信息在图中的传播,因此更灵活地适应了不同节点之间的 关系。GAT 的核心思想是利用节点之间的特征和关系来计算注意力系数,然后根据这些 注意力系数对节点特征进行加权求和,以生成更新后的节点表示。这种注意力机制允许 模型动态地调整节点之间的关注程度,从而更好地捕获节点之间的复杂交互。更多理论细节:Graph Attention Networks
对于每一个图注意力网络,将一层图注意力网络迭代多层,拿到最后一层的输出 X, 作为特征 C。
答案生成模块
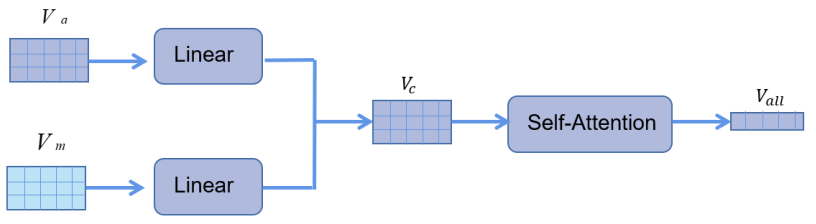
在答案生成模块中,首先视觉外观特征和视觉动作特征进行融合,得到了表示每个 片段的外观-动作融合视觉特征$V_c$。进而将视频中的每一个片段特征进行了融合,通过自 注意力的机制得到整个视频的融合特征表示$V_{all}$。
自注意力(Self-Attention)是一种注意力机制,最初在自然语言处理中广泛应 用,特别是在序列到序列的模型中。自注意力允许模型在处理序列数据时动态地关注序 列中不同位置的元素,并根据它们的相关性来进行加权。自注意力机制的核心思想是通 过计算每个元素与其他元素之间的相似度得到权重,然后将这些权重作为加权系数,对 序列中的元素进行加权求和,以生成更新后的表示。这种机制使得模型能够在不同的上 下文中调整关注的重点,从而更好地捕捉序列中元素之间的长程依赖关系。
至此,模型得到了与文本交互后的融合视觉特征,现在只需要要通过该视频信息回 答问题。具体来说,将语义特征 q 通过一层线性层后,与视觉特征$V_{all}$进行拼接,得到 融合特征 y。最后特征维度映射为答案分类数目。由于在MSVD-QA数据集中答案是单个单词,答案分类数目即为词汇表大小,1854类多分类。

自编码器模块
受自编码器启发,为了更好地提升编码器模块(ResNet101、ResNeXt101)的特征提 取效果与多模态融合模块的融合效果,分别实现了负责重构视觉片段的解码器 $g_1$ 和负 责重构动作片段的解码器$g_2$。重构后的片段将与原视频片段求损失更新编码器模块与多 模态融合模块的参数。
自编码器(Autoencoder)是一种无监督学习模型,用于学习数据的有效表示。它通 过将输入数据压缩到一个低维编码空间,然后再从该编码空间中重构原始数据,从而实 现数据的压缩和解压缩过程。自编码器包含两个主要部分:编码器(Encoder)和解码器 (Decoder)。编码器将输入数据映射到编码空间中,通常是一个低维的表示;解码器则 将编码后的表示映射回原始数据空间,尽可能地重构输入数据。自编码器的训练过程旨 在最小化输入数据与解码后的数据之间的重构误差。这通常通过最小化重构损失函数 (如均方误差)来实现。训练自编码器时,模型会学习到如何在编码空间中捕获输入数 据的重要特征,并在解码时尽可能地还原原始数据。
实验设置与结果
数据集
对于视频问答任务,我们使用了 MSVD-QA 数据集。MSVD-QA 数据集是一个用于 视频问答任务的数据集,其全称为 “Microsoft Research Video Description Corpus with Question-Answer Pairs”。从微软研究院视频描述 (MSVD) 数据库中收集了 1970 段修剪 过的视频。该数据库包含 50,500 对由 NLP 算法自动生成的问题-答案对,其中包括五 种一般类型的问题:what、how、when、where 和 who。平均视频长度约为 10 秒,平 均问题长度约为 6 个单词。因此,这是一个小规模数据集,包含简短的问题。我们在该 数据集上进行实验,以测试我们的模型在真实世界中的短视频上的泛化能力。

第一阶段
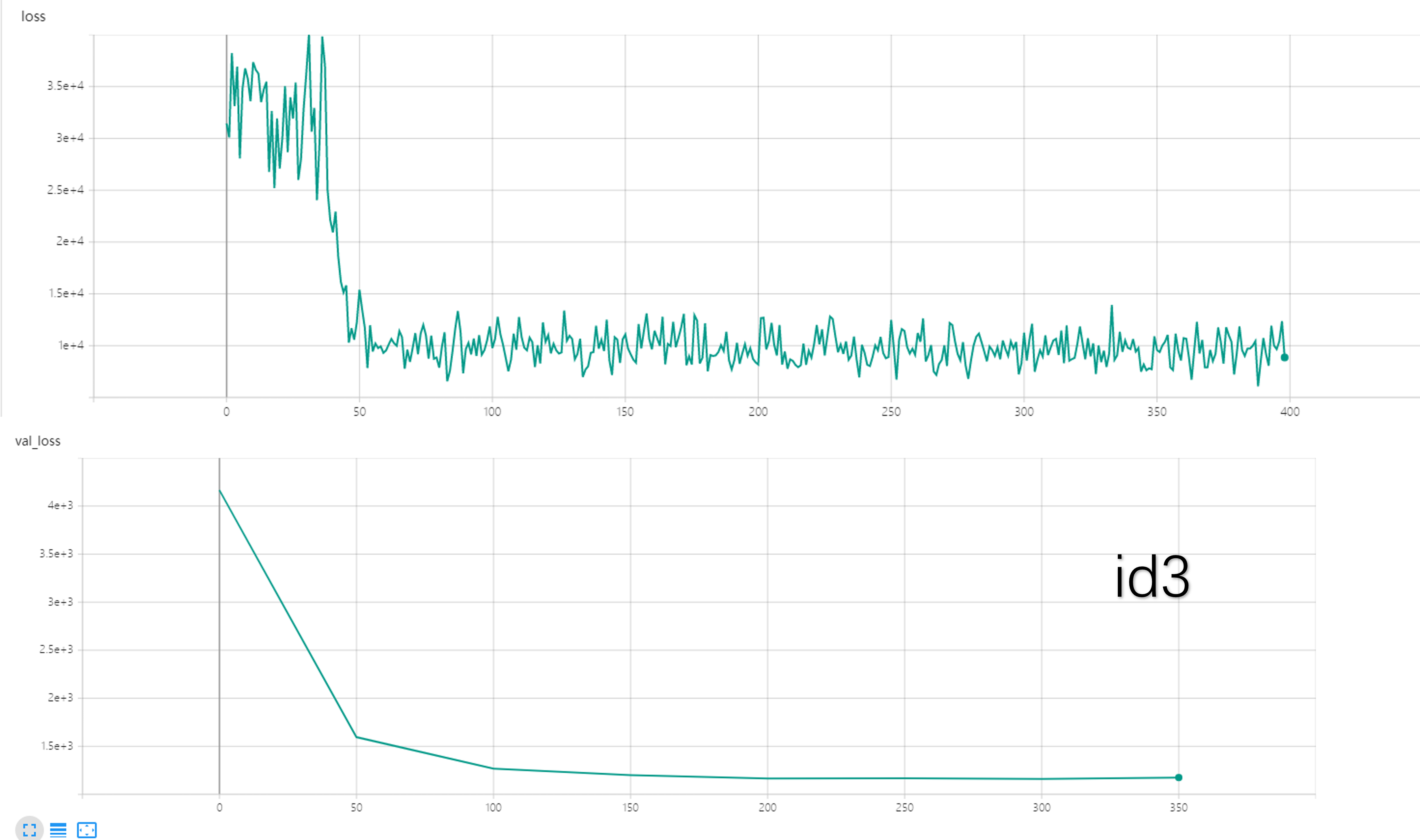
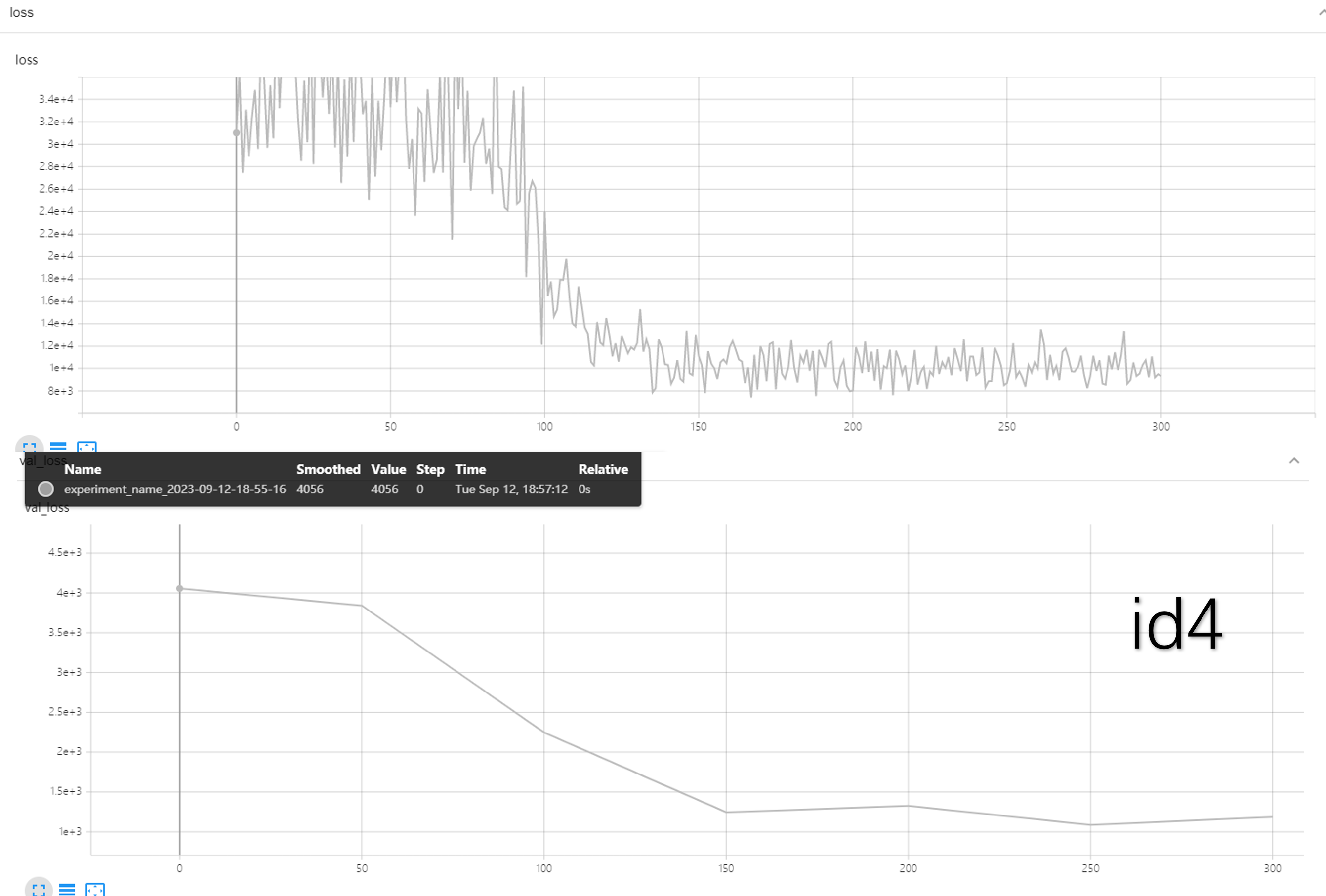
整个实验过程分两个阶段进行。第一阶段是自编码器模块的训练。这一阶段的训练意在提升编码器模块的特征提取效果与多模态融合模块的融合效果,将重构的视频片段与原视频片段求平均平方误差。
第一阶段结果如下:
| id | image_height | image_width | batch_size | num_frames_per_clip | lr | layer2 | layer3 | layer4 | inner_dim | z_size=768 | loss | val_loss |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 100 | 100 | 8 | 16 | 0.00001 | z-512 | 512-256 | 256-512 | 512 | 768 | min(8302)||avg(10000) | min(1199) |
| 2 | 128 | 128 | 8 | 16 | 0.00001 | z-512 | 512-1024 | 1024-512 | 512 | 768 | 6578||10000 | 1227 |
| 3 | 100 | 100 | 8 | 16 | 0.000025 | z-512 | 512-1024 | 1024-512 | 512 | 768 | 6077||10000 | 1161 |
| 4 | 100 | 100 | 8 | 16 | 0.00001 | z-256 | 256-512 | 521-256 | 512 | 768 | 7424||10000 | 1086 |


第二阶段
第二阶段是整体模型的训练,在第一阶段编码器模块和多模态融合模块的训练结果下继续训练。这一阶段产生视频问答任务的结果。后续主要分析第二阶段的训练结果。

第一次实验(standard1)一共训练了 3866 个批次,batch_size=8,耗时 1小时24分钟。第一次实验是试验性的,并没有使用自编码器来优化编码器部分,更接近参考模型 DualVGR。第一次实验并没有跑到收敛,最后的 avg_loss=5.342,avg_acc=0.1913。

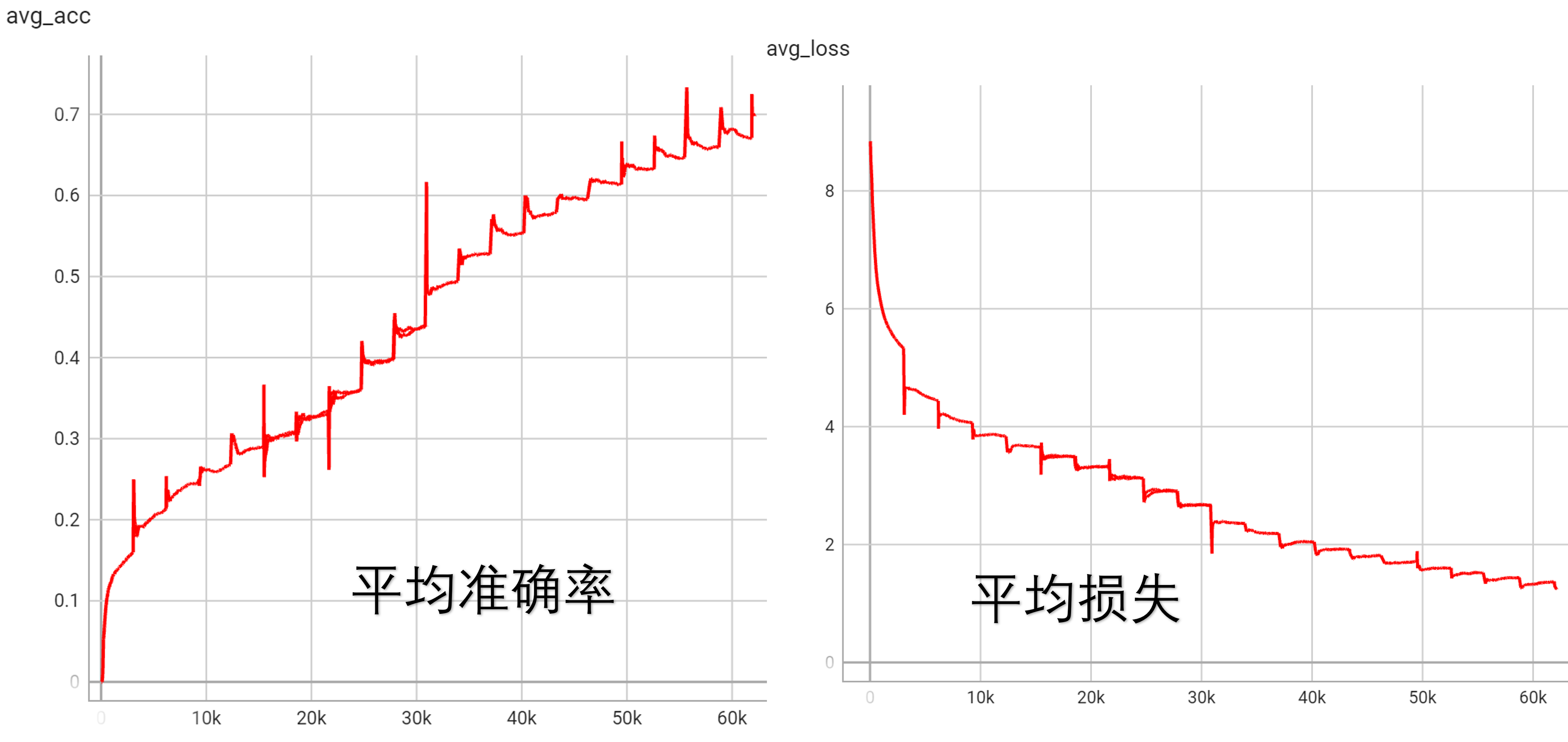
第二次实验(standard2)一共训练了 3万 个批次,batch_size=10,耗时 20小时26分钟。其中,首先跑了300批次的自编码器来优化编码器部分,最后损失收敛到1000左右。(注意自编码器图上没有求平均,batch_size=10,总损失为 1万)

然后是平均准确率和平均损失,一共训练了 3万 个批次,batch_size=10,耗时 20小时26分钟。虽然在训练集上准确率仍然有上升的趋势,但是从验证集上看,准确率已经趋于稳定因此没有进一步的训练。


有几个点可以分析:
- 相比于 DualVGR,在去掉自编码器以外,仅仅是将 ResNet 与 ResNext 加入训练的区别。然而使用了更多参数之后,训练结果没有变好。
- 在训练集的准确度和验证集的准确度上出现了很大的差别,意味着模型过拟合了。
- 注意到在训练集上的准确率和损失,在一个 epoch 结束后会发生一次跳跃式的改变,尚没有搞清楚背后的原因是什么。
- 在加入更多参数之后,显存容量变得捉襟见肘,训练的时间也大大增长了。注意到一个 epoch 大约为 3000 batch,因此只训练了 10 个 epoch 就需要 20 小时,而原来的 DualVGR 训练 10 个 epoch 只需要 14 分钟。
第三次实验(standard3)是从第二次实验的 1.5万 批次开始继续实验,一直训练到 6万 批次。由于是继续实验,没有使用自编码器来优化编码器部分。与第二次实验不同的是,第二次实验学习率为 1e-5,第三次实验学习率为 1e-4

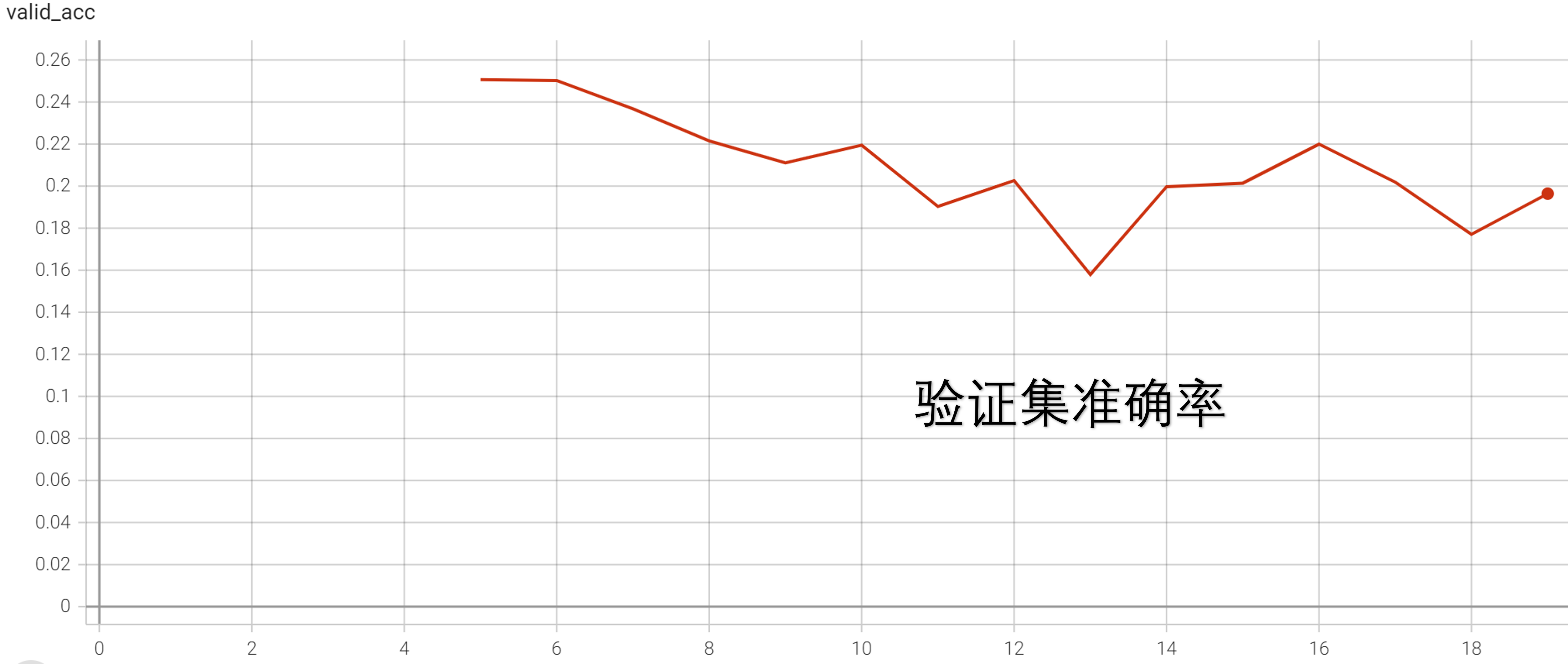
同样的,虽然在训练集上准确率仍然有上升的趋势,但是从验证集上看,准确率已经趋于稳定,因此没有进一步的训练。
由于第三次实验是从第二次实验继续实验得来的,我们将两次实验放在一起看:
使用TensorBoard
所有的实验我们使用一块 RTX 3090 完成。tf-logs文件夹存放了TensorBoard可视化结果,可以通过如下命令看到实验结果:
1
tensorboard --logdir tf-logs
一个小教程:TensorBoard简单使用
对应的参数可以查看仓库附件存放实验结果,只保留了自动记录的控制台消息console.log。与tf-logs文件夹中的结果对应,包含:
- standard2
- standard3
- standard4
其他
重要信息总结:
- 损失函数(第一阶段):MSELoss
- 损失函数(第二阶段):
- 交叉熵损失(Softmax分类器)
- 一致性损失(论文独有方法,对于两个输出嵌入向量多视图任务设计了一个一致性约束)
- 差异损失(论文独有方法,确保特定嵌入和通用嵌入可以捕获不同的信息)
- 优化器:Adam
- 正则化:梯度裁剪,Dropout,BatchNorm1d,BatchNorm3d,LayerNorm(注意力)
- 参数量:
- 0.4亿(resnet_101)
- 0.5亿(resnext_101)
- 0.8亿(AE解码器)
- 0.2亿(其他)
- 1.9亿(总)
- 参数初始化:在创建图神经网络时需要去掉自环、规范化邻接矩阵;xavier_uniform_初始化权重
- 样本量:3W(训练集);6K(验证集)
- 数据集大小:2GB
- GPU:RTX3090
- 显存消耗:至少16GB
- 训练时间:几小时(第一阶段);约一天(第二阶段)
代码组织:
data文件夹存放数据集data_laoder文件夹存放数据加载器和数据集类img文件夹存放参考图片model文件夹存放模型代码,是工作的核心options文件夹存放复杂处理命令行参数的类preprocess文件夹存放预处理视频和问题文本的类results文件夹存放实验结果tf-logs文件夹存放TensorBoard可视化结果util文件夹存放代码中用到的小工具train.py训练模型
一些细节:
- 预处理视频特征主要是将视频切片,转换为 tensor。将一个视频进行均匀地切分,每个视频表示为 $c$ 个连续的片段,每个片段包含了 $f$ 帧的图像,图图像的像素大小固定为$h×w$,因为是彩色视频所以通道数 channel = 3。
- 如果切对应ResNet101的视频,结果是torch.Size([c, f, channel, w, h])。如果切对应ResNext101的视频,结果是torch.Size([c, channel, f, w, h])
- 预处理问题主要将自然语言问题使用Glove编码成为tensor。
- 模型有两个优化方式:第一个是传统的视频问答计算损失和优化模型;第二个是通过自编码器重构视频来优化编码器Encoder,提升编码效果。
此外,我们的项目参与了第九届中国国际“互联网+”大学生创新创业大赛。探索该项目的实用场景,我们提出了两种模型的现实应用场景:
- 快速加入视频平台搜索系统。根据原生搜索系统检索出来的粗粒度的视频集合,加上对用户文字描述的进一步分析,返回精准的搜索结果。
- 快速加入视频制作者工作流。自动构建素材库,提供智能检索服务。


其余可以参考:
总结&未来展望
此项目为2023年省级大学生创新创业训练计划,基于深度学习的视频问答题目的模型。
这个模型本质是DualVGR一个小小的改进,具体可以看上面的参考链接,几个模型的架构都是比较相似的。不如说当我再次回顾原论文时发现,我们做的这么一些小小的改进,对比原论文的工作来说,好比只是在一栋大楼上加了一个小小的装饰。
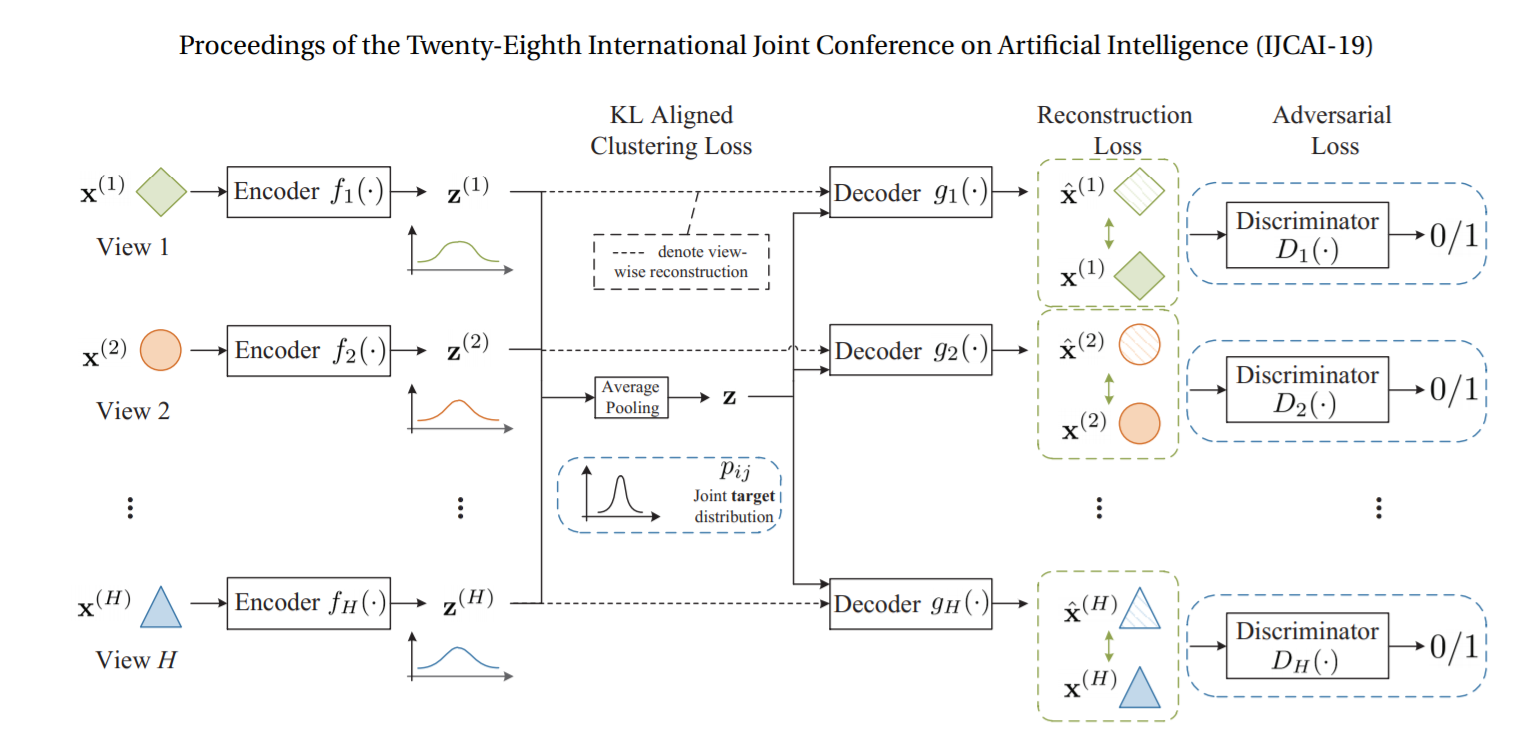
我们预定的工作计划是在原来的模型上加上自编码器与对抗生成网络。思路受对抗的不完全多视图聚类(AIMC)方法启发,AIMC的模型图如下:
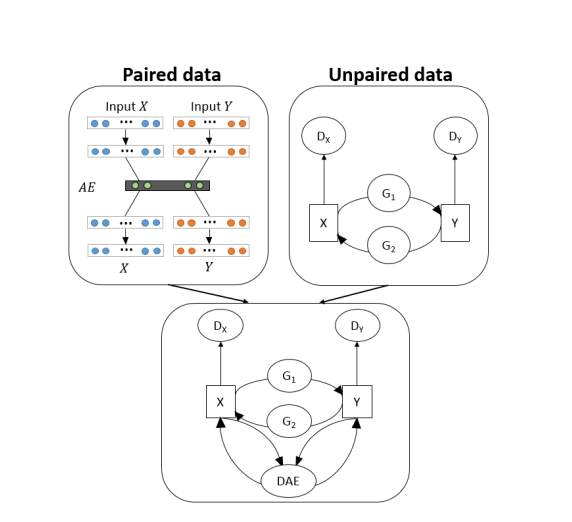
在代码上,自编码器与对抗生成网络架构的一个很好的参考是 VIGAN,模型如下:
项目完成时,完成了对整个项目的重构(DualVGR)、自编码器部分代码编写、以及初步的实验。由于效果一般,并且预估对抗生成网络的加入也不会对模型效果起到显著作用,对抗生成网络的计划被无限搁置了。如果要为这个不算成功的项目找一些原因,应该是下面这些:
- 人员专业能力不强。对论文的理论部分,特别是一些早期深度学习论文涉及大量数学知识,对于这些部分的理解不到位或者搞不懂,一知半解。
- 人员动手能力不强。深度学习的成果建立于大量的实验之上,这种动手能力既需要坚实的代码功底,也需要对深度学习框架的熟悉。这种动手能力需要在一个又一个实战项目中不断磨练。
- 优先级。作为本科生而言,最重要的且花费时间最多的是自己的绩点,做大创以及科研,在大二时期只能排在第二位。在很多时候,我们什么都要,但是我们没有什么都要的能力,就不得不面临“鱼与熊掌”的问题。
- 交流。在做大创时主要的外援有两个,一个是学长,一个是导师,然而在最后总结的时候来看,我们的交流太少了。导师和学长都有自己的工作,很难会关注大创,需要我们自己主动去联系他们做交流。而我作为负责人不是很外向,更喜欢自己去探索,也许失去了一些纠正方向的机会。
- 前期快速验证计划的缺失。为了验证一个思路是否可行,可以快速实现一个小模型来验证。不过也正是由于之前的原因,导致无法快速实现验证用的小模型。在确认思路走不通的时候,已经浪费了太多时间。
此项目是我们小组用于学习、练手与实验的第一个项目。作为一个大创项目,以及用于练手的项目,很难能做出SOTA的结果。在深度学习发展如此迅速的今天,在这个大创项目周期还没有结束的时候(2024.02.18),这个模型已经远远落后于时代了。
但,当我们把眼光放得小一点,只把它当做一个大创项目来说,它的工作量已经足够了,也让我们学习到了深度学习的前沿知识,领略到了深度学习的魅力,为我们后续的工作与学习奠定了基础。