训练 DualVGR
跑模型时间!
论文笔记:https://qmmms.github.io/posts/DualVGR-A-Dual-Visual-Graph-Reasoning-Unit/
挑选服务器
在论文中,实验都是在两个NVIDIA RTX 2080Ti GPU上运行的,在实际训练中,显存至少需要8GB,请注意这个最低限度。
在自己的实验中选用了一块RTX 3080,14 min 可以训练 10 个epoch。
在2024年2月8号,一块RTX 3080在 AutoDL 平台上每小时租金 0.88 人民币。
获取代码
github仓库:https://github.com/MM-IR/DualVGR-VideoQA
一般来说,可以在服务器上使用 git clone 获取仓库代码,但是请注意远程服务器没有代理,可以先在自己电脑上下载好代码,再上传服务器。
前期配置
远程服务器上需要安装的python包包括:
1
2
3
4
pip install opencv-python
pip install h5py pyyaml
pip install nltk pandas
pip install scikit-learn termcolor easydict
数据集下载
README文档要求在MSRVTT-QA, MSVD-QA网站下载数据集。
- MSVD-QA下载网址(需要上网下载)
- 视频文件下载网站,拉到底选择YouTubeClips.tar
- youtube_mapping.txt 下载网址(需要上网下载)
步骤:
- 第一个链接会下载下来一个压缩包,解压,里面有一个
video文件夹。 - 把第二个链接下载的所有视频放到
video文件夹下。 youtube_mapping.txt放在MSVD-QA文件夹下。- 将整个MSVD-QA文件夹上传到服务器代码文件夹下的
data文件夹下。
MSVD-QA文件夹结构:
1
2
3
4
5
6
7
8
9
10
11
12
.
│ readme.txt
│ test_qa.json
│ train_qa.json
│ val_qa.json
│ youtube_mapping.txt
│
└─video
-4wsuPCjDBc_5_15.avi
-7KMZQEsJW4_205_208.avi
-8y1Q0rA3n8_108_115.avi
-8y1Q0rA3n8_95_102.avi
处理视觉特征
- 在
preprocess_features.py代码中把文件路径改好。 num_clips需要按照论文中的实验细节部分设置好。
命令:
1
python preprocess/preprocess_features.py --gpu_id 0 --dataset msvd-qa --model resnet101
bug修正提示:preprocess/datautils/msvd_qa.py的27行路径修改好
记得改名输出文件data/msvd-qa/msvd-qa_appearance_feat.h5
处理动作特征
首先从pretrained model下载 resnext-101-kinetics.pth,这是resnext的权重文件,之后就不用预训练了。将.pth文件放入data/preprocess/pretrained/文件夹中。
命令:
1
python preprocess/preprocess_features.py --dataset msvd-qa --model resnext101
bug修正提示:preprocess/preprocess_features.py的build_resnext函数的路径需要修改
记得改名输出文件data/msvd-qa/msvd-qa_motion_feat.h5
处理问题文本
下载glove pretrained 300d word vectors 到data/glove/ 然后处理为 pickle 文件:
1
python txt2pickle.py
修改好preprocess/preprocess_questions.py的数据集路径:
1
args.annotation_file = './data/MSVD-QA/{}_qa.json'.format(args.mode)
然后处理问题:
1
2
3
4
5
python preprocess/preprocess_questions.py --dataset msvd-qa --glove_pt data/glove/glove.840.300d.pkl --mode train
python preprocess/preprocess_questions.py --dataset msvd-qa --mode val
python preprocess/preprocess_questions.py --dataset msvd-qa --mode test
bug修正提示:第一次运行会提示下载
punkt
Resource punkt not found. Please use the NLTK Downloader to obtain the resource: >>> import nltk >>> nltk.download('punkt')需要在python命令行中运行如上两条命令,但是由于下载国外服务器上的资源所以很慢,需要使用
vim在/etc/hosts文件添加一行:
然后可以运行命令顺利下载资源。(hosts文件原理略)
训练
训练所用命令:
1
python train.py --cfg configs/msvd_qa_DualVGR.yml
即使用configs/msvd_qa_DualVGR.yml中的配置,运行train.py文件。
bug修正1
config.py98行需要修改,因为yaml包的方法过期了
1
yaml_cfg = edict(yaml.load(f, Loader=yaml.FullLoader))
bug修正2
把所有 cuda:1 改成 cuda:0,因为只租了一块GPU
bug修正3
遇到问题‘lengths‘ argument should be a 1D CPU int64 tensor, but got 1D cuda:0 Long tensor
原因是torch 版本导致的错误,解决方法找到torch的库,修改如下的实现 在torch\nn\utils\rnn.py 第244行附近
1
2
3
_VF._pack_padded_sequence(input, lengths, batch_first)
改为
_VF._pack_padded_sequence(input, lengths.cpu(), batch_first)
bug修正4
遇到问题RuntimeError: mat1 and mat2 shapes cannot be multiplied (2048x32768 and 2048x768)
解决:根据论文video_motion_feat: [Tensor] (batch_size, num_clips, visual_inp_dim),这里为torch.Size([256, 8, 32768]),最简单的做法是将model/models.py46行硬编码
1
self.visual_motion_input_unit = nn.Linear(32768, module_dim)
然后,不出意外的话,代码就可以跑了。
TensorBoard可视化
AutoDL 平台支持TensorBoard,会自动加载放在/root/tf-logs的TensorBoard文件。
如果你了解过 TensorBoard 的基本使用,在train.py中的适当位置加入代码:
1
2
3
4
5
6
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('/root/tf-logs')
writer.add_scalar('Train/Accuracy', train_accuracy, epoch)
writer.add_scalar('Train/Loss', avg_loss, epoch)
writer.add_scalar('Valid/Accuracy', valid_acc, epoch)
writer.close()
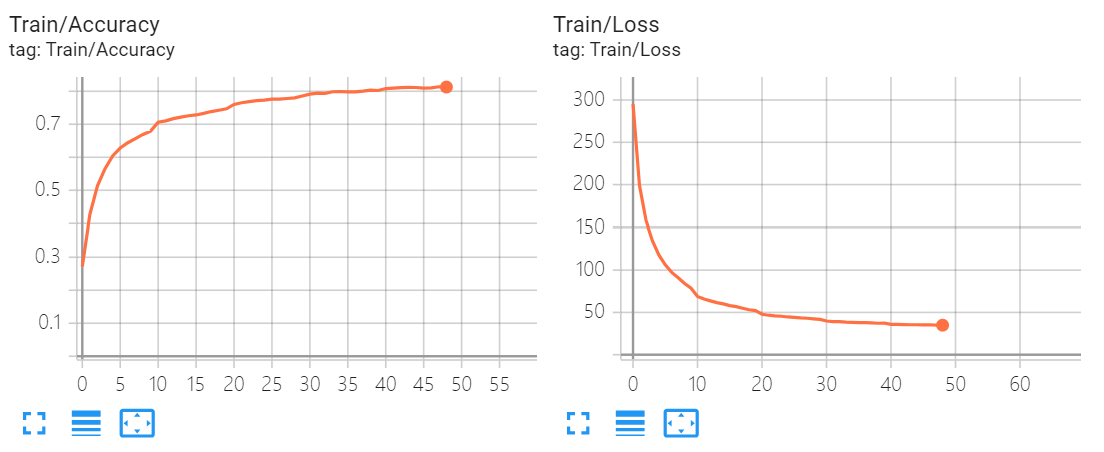
然后在模型训练中可以看到损失和准确率: