基于知识蒸馏的视频问答模型
读论文时间!
是 DualVGR 的改进,大部分与其相同
介绍
视频问答旨在模型需要对视频以及视频对应的问题进行分析与理解后,对该问题的正确答案进行分类,答案的类别即在一个固定数量的答案集中。为了解决该任务,本方法搭建了一个基于知识蒸馏的视频问答模型,一个以包括了视频和问题的多模态特征作为输入的答案分类模型。本文依据 DualVGR 对模型整体框架进行了建模。在此基础上,为了实现压缩模型,以及使用大模型丰富的多模态知识来优化小模型的特征学习过程的目的,本文提出了一种多模态知识蒸馏的方式,来进一步提升模型性能。
视频问答的困难与挑战包括:
- 在理解复杂问题时,问题提问的方式、提问的意图以及问题所针对的视频重点等都是复杂多样的,这就需要机器对问题的各个方面有较好的理解。
- 在处理视频上,视频语义的学习是机器理解视频信息的关键所在。而视频具有静态图像所不具有的时序性,对于类似“男人在做什么?”的动作类问题来说,有一些动作就不能仅凭分析单帧的静态图像而推理出来。这种动态序列的分析就需要机器不仅可以观察到视频中的静态图像的信息,识别图像中的各个目标以及分析各个目标之间的关系,还要能够识别动态序列下各个对象的动作特征,并且具有一定的推理能力。
- 视频问答任务是一种跨模态的任务,需要处理来自多个模态的信息,包括对视频和问题之间的综合理解。如何有效地融合各个模态的信息来获得答案,也是该任务所面临的挑战。
对此,本文结合注意力机制和图卷积网络等方法建立深度学习模型,综合利用了注意力机制在加强视觉和文本特定区域特征关注程度上的优势,以及图卷积网络在视频节点间关系推理上的有效性。
同时,模型挖掘了视频中静态的外观特征与动态的动作特征之间的独有特征和关联关系,并通过应用知识蒸馏的方法,在对模型进行压缩的同时进一步加强了外观特征与动作特征之间的融合。本文主要研究内容包括了以下几个方面:
- 通过注意力机制加强特定区域特征关注。首先通过自注意力机制对问题特征中各个单词的注意力进行强化,以降低问题中一些不重要的单词的关注程度。同时,通过以问题为导向,计算视觉特征中各个片段上的注意力权重,以将机器的关注点放在与问题更加相关的视频片段中。并且在视频外观独有特征与关联特征融合和视频的各个片段特征融合时,同样使用了自注意力的机制来提升特征的融合效果。
- 通过图卷积网络进行视频节点间的关系推理。本文采用了多头图卷积的方式,并将每个图卷积头得到的特征进行连接,作为卷积结果。为了更充分的使用图卷积挖掘与推理视频节点关系,采用了多层图卷积的方式,并在图卷积过程中融入注意力的机制,以加强对视频各个节点之间关系的学习。同时,在该步骤中不仅推理了视频的外观特征和动作特征,还使用了损失函数约束的方式挖掘了在外观中与动作视觉信息相关联的特征与在动作中与外观视觉信息相关联的特征,进一步地提取了外观和动作之间潜在关联关系。
- 通过知识蒸馏进一步优化模型。本文在训练教师模型的基础上,构造并训练了一个相对轻量的学生模型来改善模型性能。而其在减少模型可训练参数,对模型进行轻量化的同时,还达到了加强多个模态之间的特征融合的效果。通过添加损失函数的方式,将教师模型中多模态融合后的知识蒸馏出来,用于学生模型中单模态的学习。这样学生模型在单模态训练过程中便可以得到丰富的多模态的信息,在训练初期更早地进行多模态之间的交互,以改善之后的多模态的融合效果。
相关工作
首先在视频特征提取时,一般通过在 ImageNet 上预训练模型对静态的外观特征进行提取,其网络模型包括 VGG、ResNet 等,使用 Kinetics 上预训练的模型提取动态的动作特征,其网络模型如 C3D。
对于问题文本特征的提取,主要使用预先训练好的词向量表来对每个单词进行编码,将单词表示为定长的向量,包括Word2Vec、Glove 等,接着通过循环神经网络对文本的语义特征等进一步提取,如BiLSTM。
对于视频问答任务来说,视频外观特征、视频动作特征和问题文本特征之间的交互与融合是研究的重点所在。对此,涌现出了各种各样的实现方式,而研究人员大多借鉴了在视觉问答中略有成效的经验方法,包括注意力机制、图卷积网络等。
最后,在答案的生成上,一般采用分类的方式进行。根据在固定数量的答案集合中计算得到的各个候选答案的概率分布,在训练时使用交叉熵损失函数计算损失,在预测时概率最高的即为预测答案。
如今的视频问答任务虽然受到了学术界的广泛关注,但相较于更早的视觉问答和文本问答等,其研究现状仍有诸多不足。
- 视频问答的数据集中,问答形式仍以选择式为主,动态生成答案的方式缺失,这显然相较于一个真正智能的问答系统来说仍有一定距离。
- 在视频特征提取上,仍主要通过预训练模型提取外观和动作特征表征视频,方法较为单一,如何有效的提取视频信息并完整的表征视频语义仍然是一个值得研究的方向。
- 在视频和问题文本之间的交互与融合上,主要还是采用注意力、图卷积等方式进行特征的增强以及对象关系推理,对于对象级的静态特征和动态特征之间的交互与文本词级特征和视频帧级特征之间的协同仍需要更多的尝试。
模型
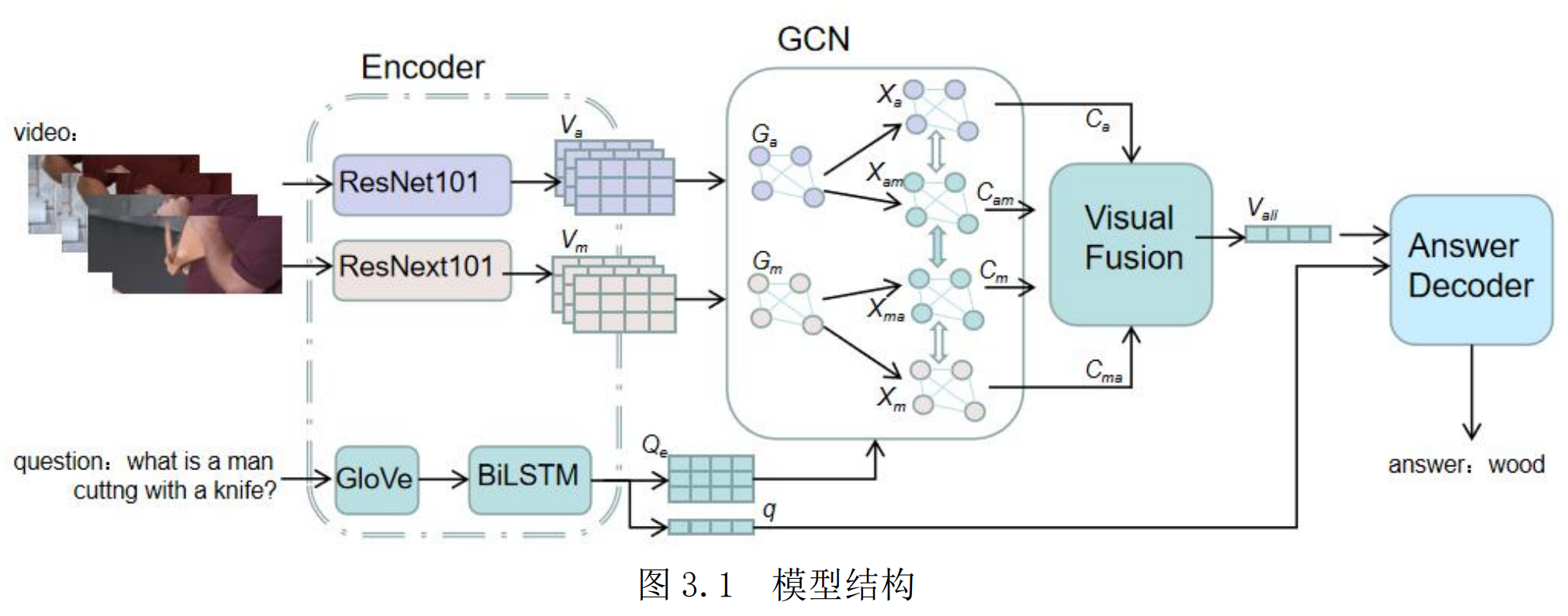
- 首先包括了视觉特征和文本特征的编码模块,通过预训练模型提取视频特征,得到外观特征和动作特征,同时使用预训练词向量表编码问题中的单词,之后通过 BiLSTM 处理来更好地提取了视频帧和问题单词的上下文信息。
- 接着是视觉-文本交互模块,该模块主要采用了注意力的机制以及多头图卷积的方式,分别对视觉与文本信息进行了交互,减少了无关信息对模型的干扰,同时对视频各片段间关系进行推理。
- 然后是视觉特征融合模块,该模块同样采用了注意力的机制对独有和关联特征融合及外观和动作特征进行融合,以及对各个片段的视觉特征进行了融合,得到了融合的视觉特征。
- 最后是答案生成模块,其通过融合视觉特征以及文本语义特征,通过解码器实现了对最终答案的分类。
- 分别训练了可训练参数较多的教师模型,以及在教师模型指导下的体量相对较小的学生模型。教师模型与学生模型在模型结构上完全相同,只是在图卷积部分略有差异。在教师模型中,为了更充分的使用图卷积挖掘信息,本方法采用了多层图卷积的方式。而在学生模型中,为了达到减少可训练参数的目的,仅使用了单层的图卷积进行训练。
编码
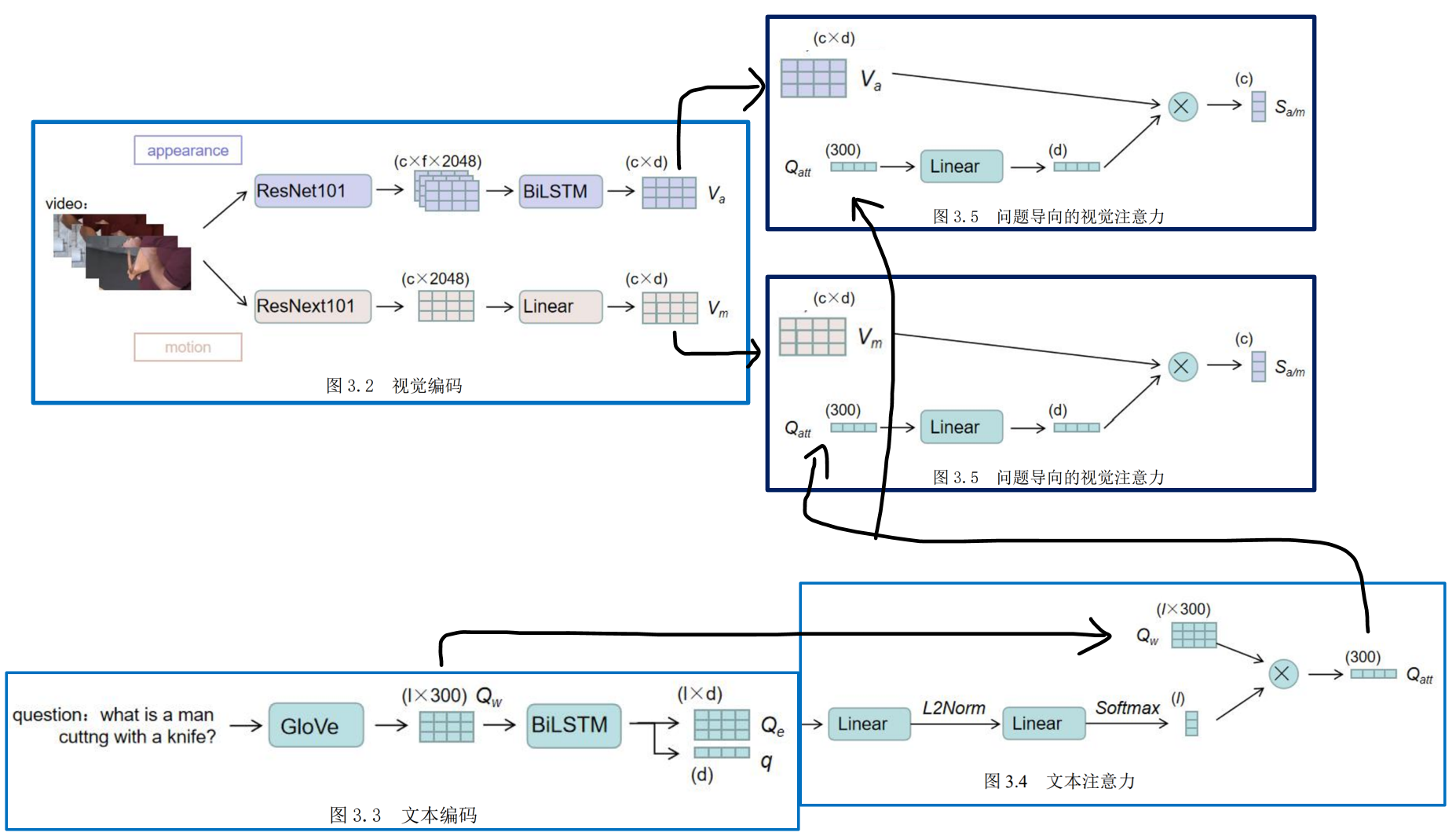
视频方面,将一个视频进行均匀地切分,每个视频表示为 c 个连续的片段,每个片段包含了 f 帧的图像,图图像的像素大小固定为h×w,通过预训练模型分别提取了视频静态的外观特征和动态的动作特征,最终所得到的外观特征表示 $V_a$,动作特征表示 $V_m$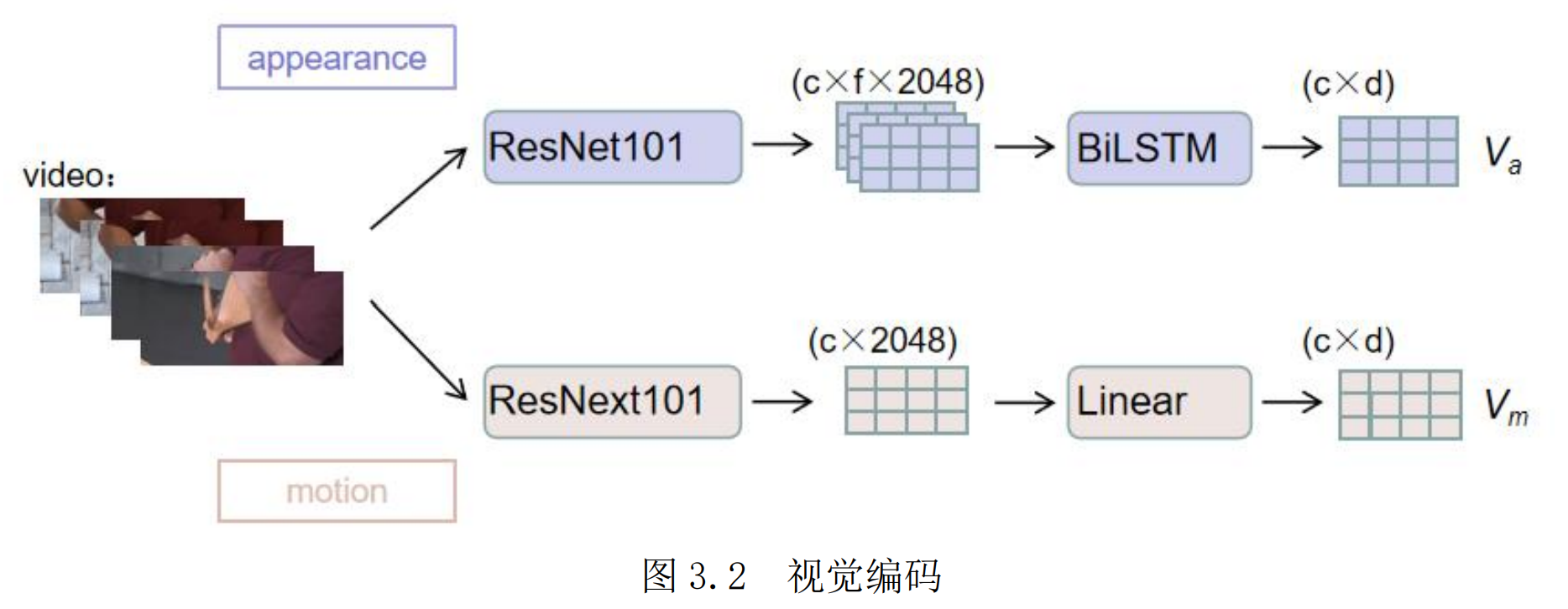
文本方面:
- 首先将训练集中所有问题出现的高频单词整理为词汇表,通过词汇表对单词进行唯一编码,以此每个句子可以表示为一串单词索引序列
- 使用预训练的GloVe 词向量表对问题中的每一个单词进行编码表示。将每一个单词表示为300维特征向量,便得到了问题的单词特征 $Q_W$
- 分别使用了两个 BiLSTM 来提取句子的嵌入特征Qe和语义特征q。

注意力方面,通过对嵌入特征 Qe计算各个单词的注意力得分以作为权重,对单词特征Qw 进行加权求和,以得到问题的整体表示。最后将注意力得分α与单词编码特征Qw进行加权求和,便得到了整个句子的注意力特征 Qatt
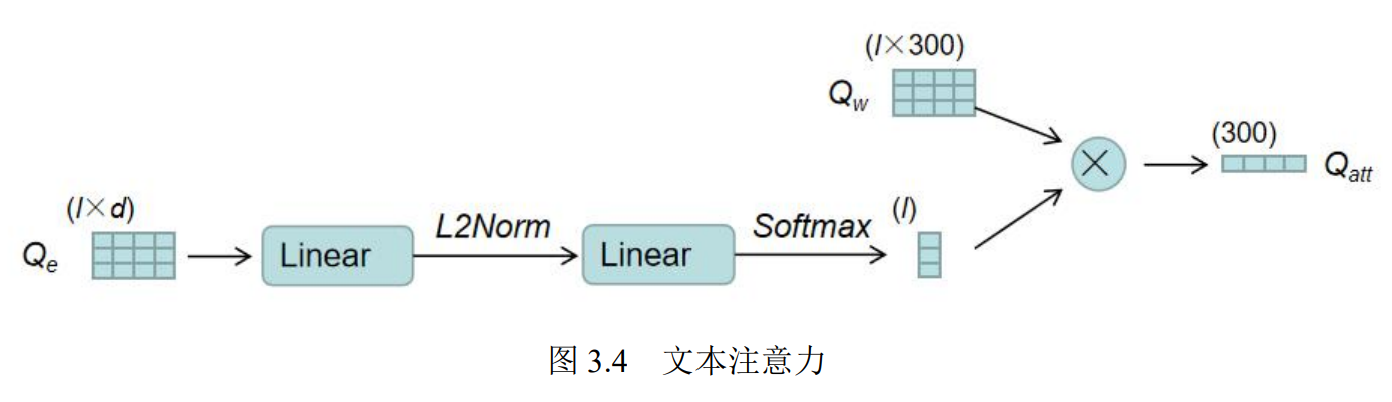
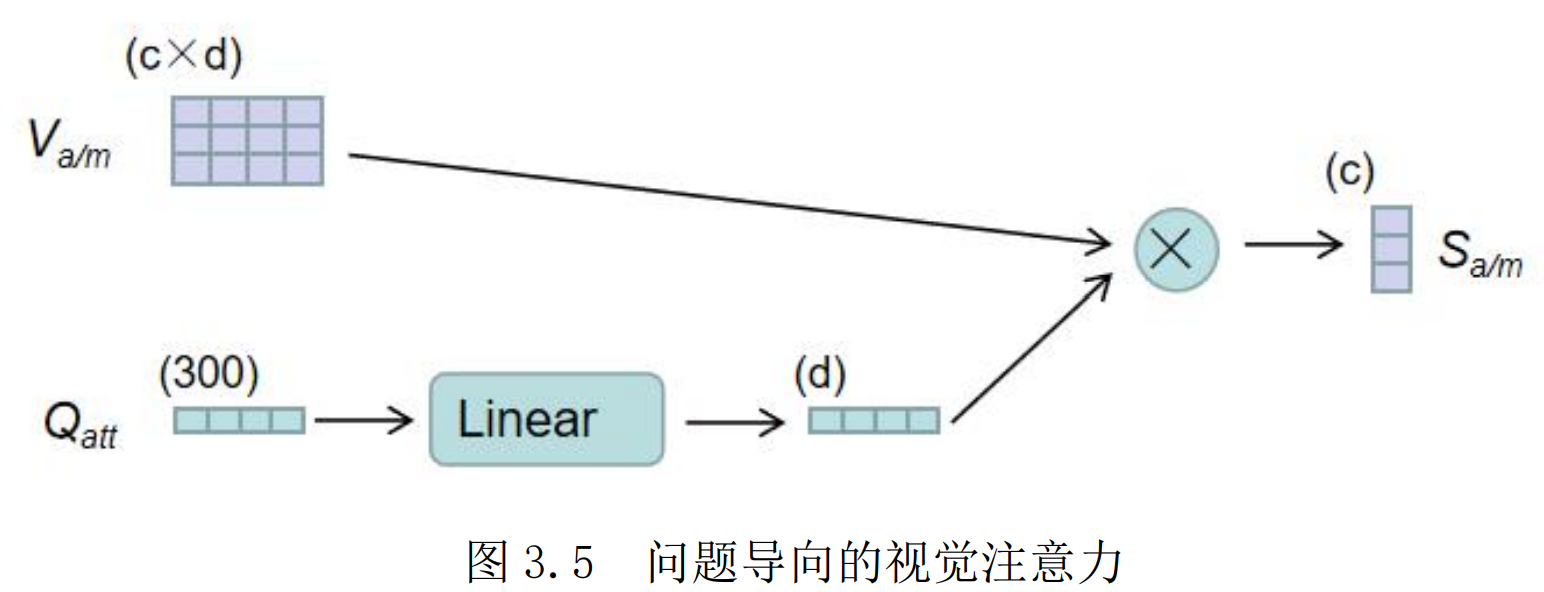
在回答某个问题时,可能该问题只与视频的某几个片段相关。所以在这里将以问题为导向的注意力作用在视频的各个片段上,以获得视频各个片段的注意力得分,来重点关注某些片段而适当忽略某些片段。最后得到视觉特征各个片段的得分Sa/m
编码总结:
多模态融合
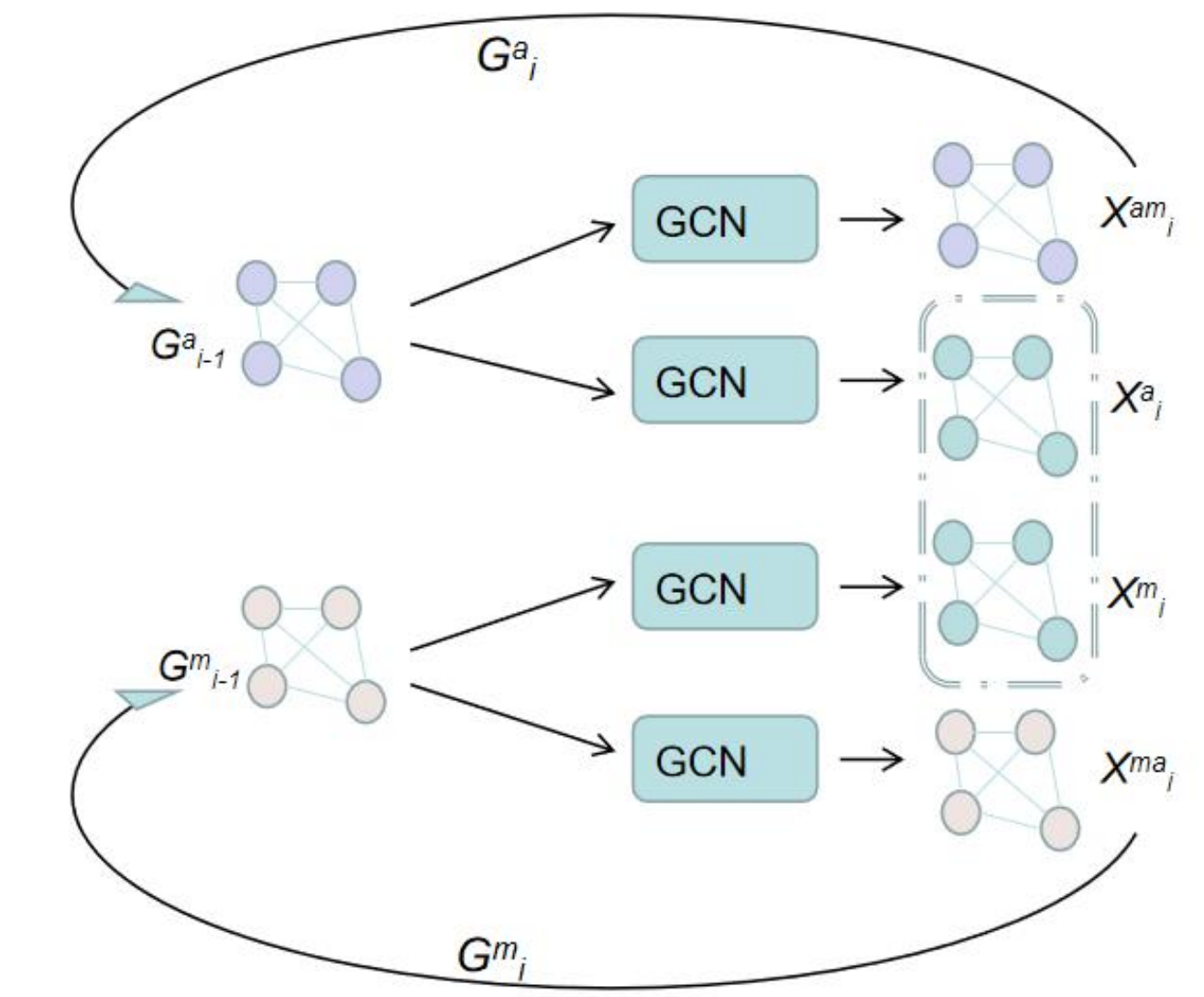
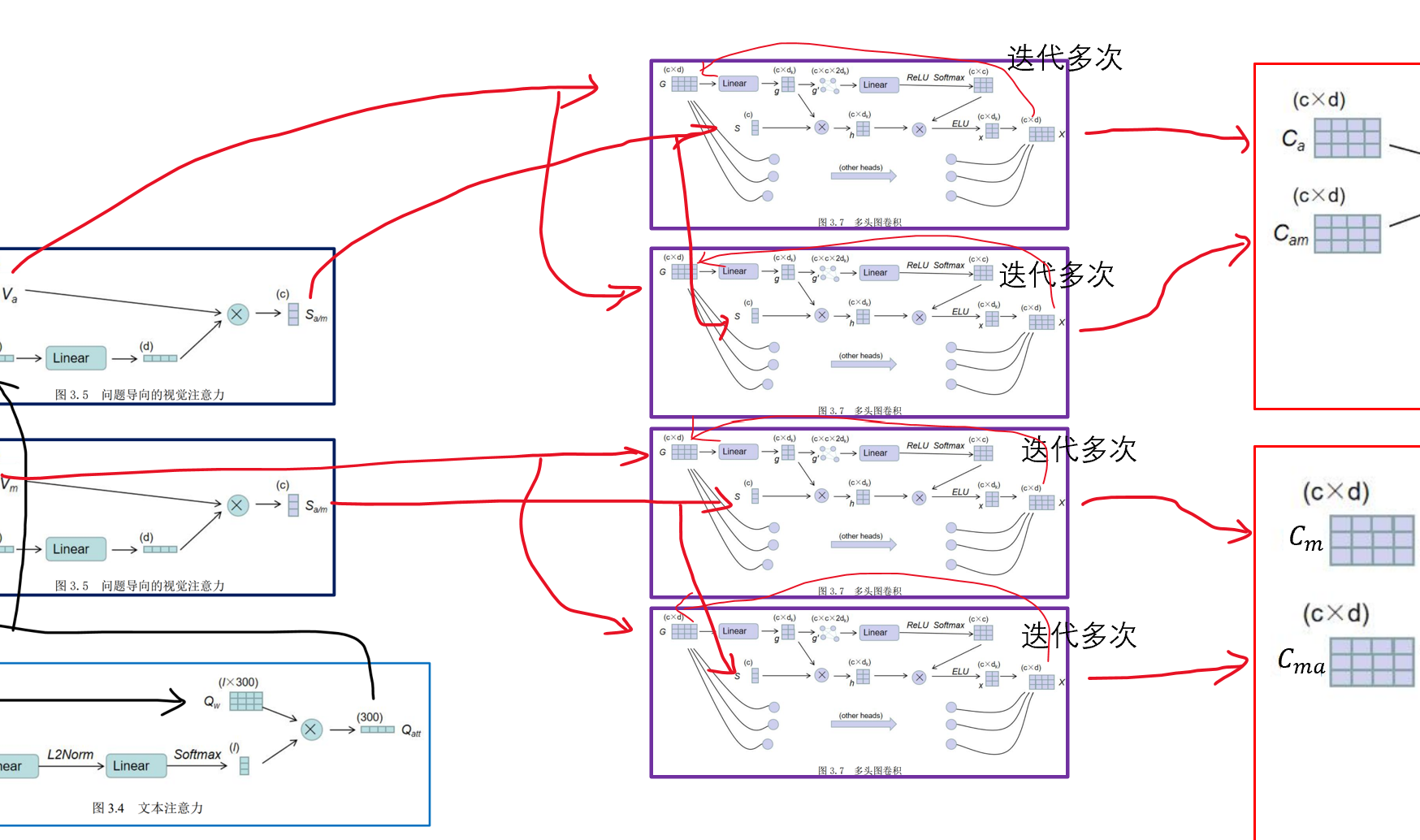
图卷积部分:先看一层GCN如何计算:在每一层的 GCN 中,其通过了 k 个图卷积头进行处理,每个头的计算方式一样,最后将各个头的结果进行拼接。
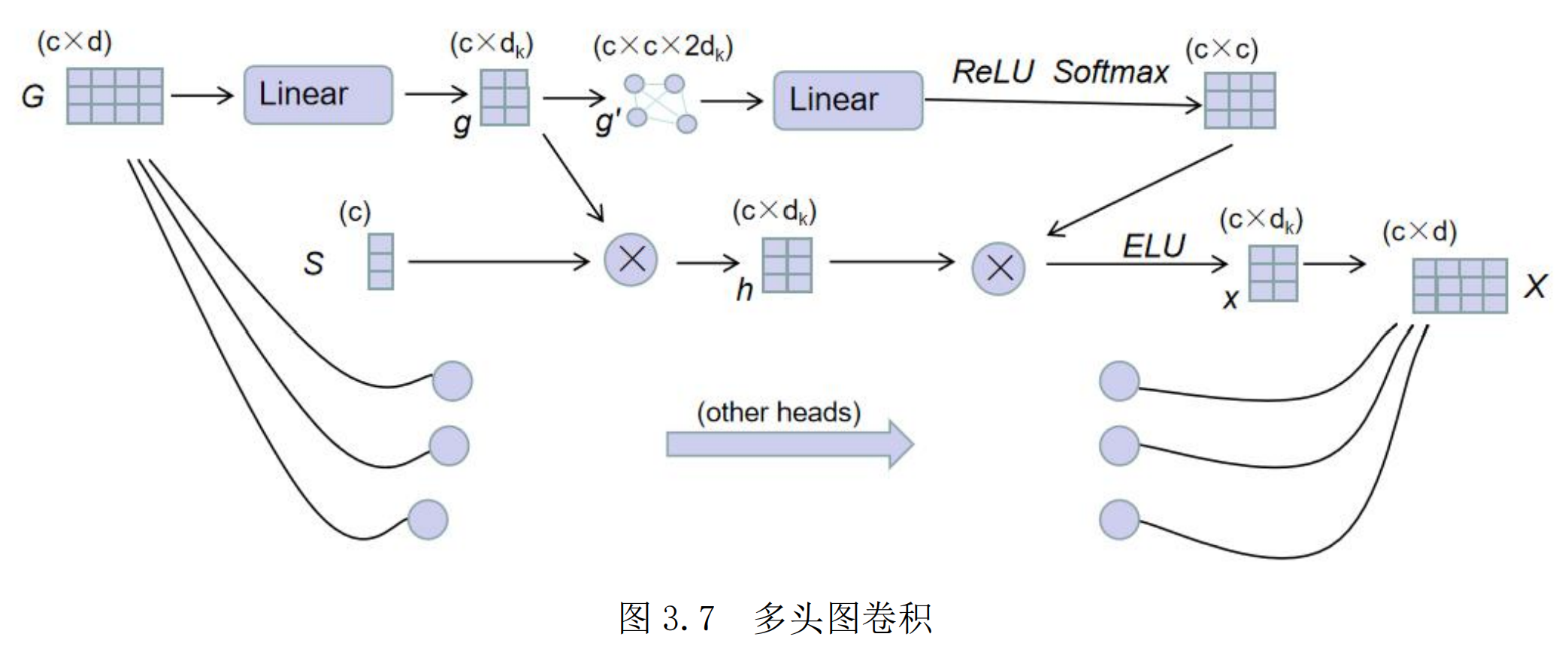
一个头的计算过程:
- 输入特征G来自上一层GCN的输出X,如果是第一层,则来自视觉特征V
- 将输入特征G通过一层线性层映射后将其作为该图卷积头所要处理的视觉特征g
- 接着通过将g与视觉注意分数S 进行相乘,达到对重要片段重点关注的目的,得到了注意力下的视觉特征 h
- 将各个片段作为节点,将两个片段之间的特征值拼接后组为边,把 g 构造成为了一个无向全连接的图 g’
- 接着使用注意力的机制,通过图特征g’得到了每两个节点之间关系的权重大小 $\beta$
- 将β与视觉特征 h 相乘,以通过各个片段之间的关系权重大小来得到每个片段基于全部片段的关系所得到的特征,通过 ELU 激活函数得到x
- 将各个头的结果进行拼接得到本层输出X
这样一层GCN迭代多层,拿到最后一层的输出X,作为特征C。
到此为止总结一下:
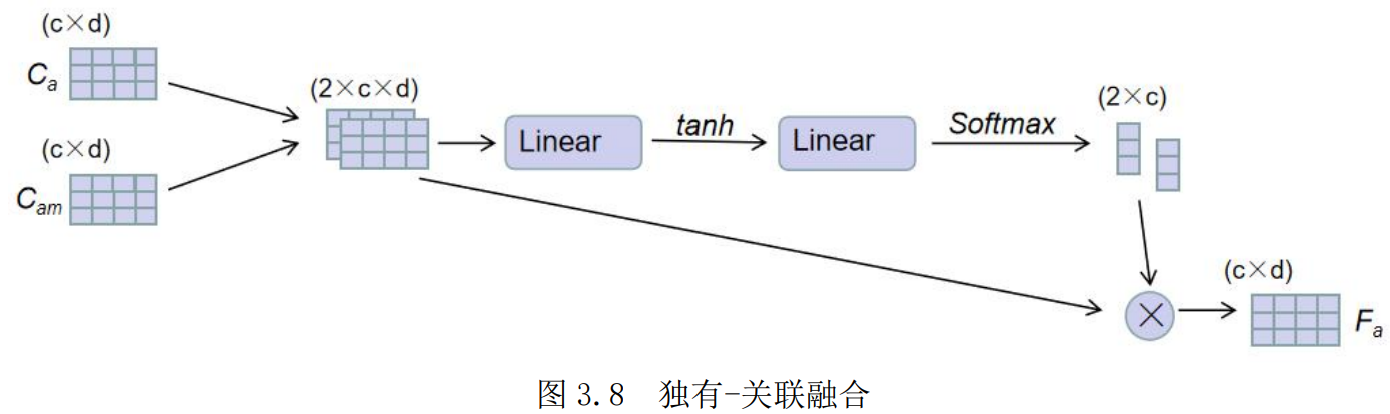
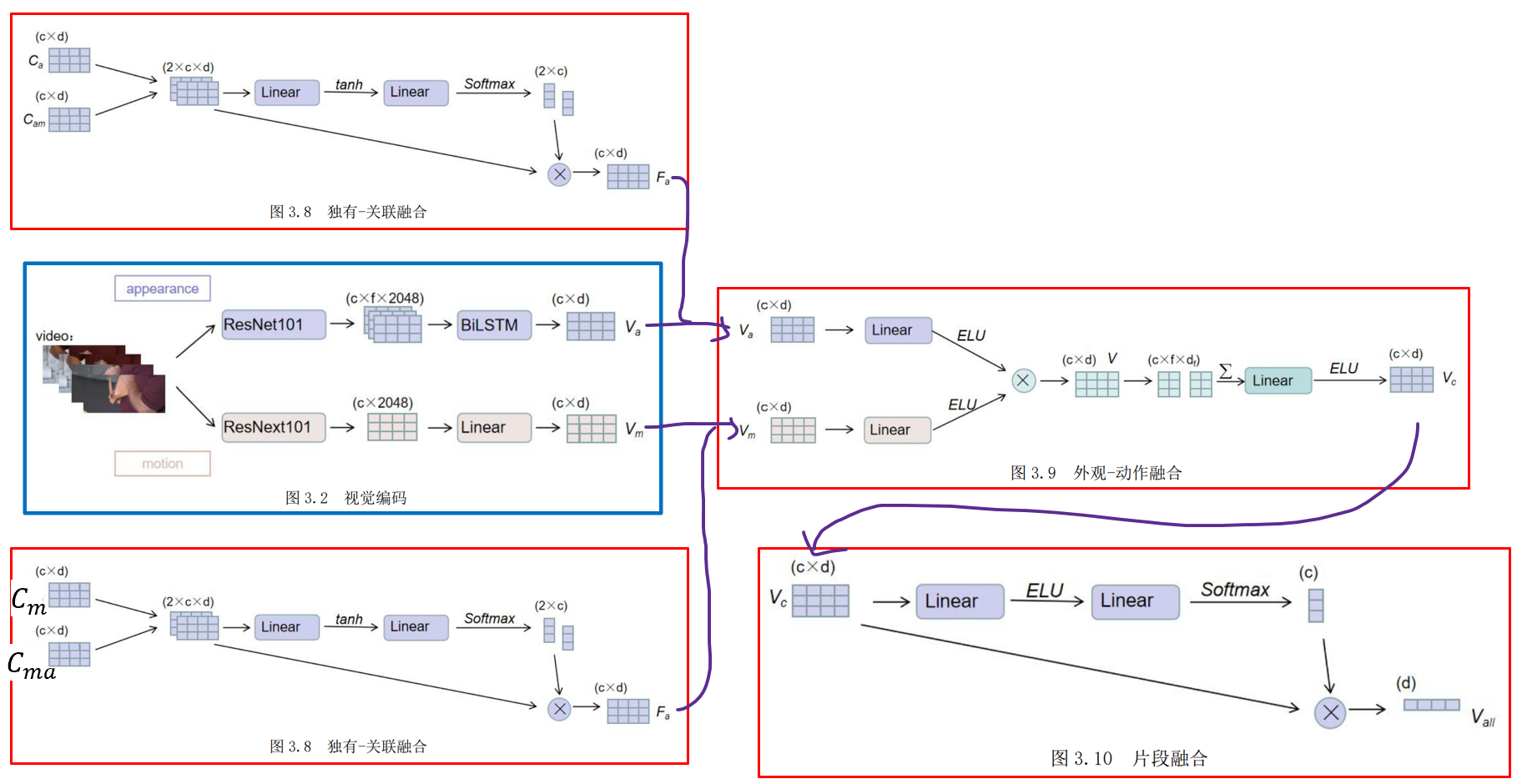
视觉融合模块部分:为了更好地突出视觉特征中独有特征和关联特征各自的重要性,首先将外观的独有特征 Ca和联合动作 Cam拼接,计算对于两类特征的注意力权重,得到了融合的外观特征Fa。对于Fb同理。
采用了残差连接,将基于关系推理过程的结果特征与最初提取的视觉特征进行相加,即 Va = Va + Fa
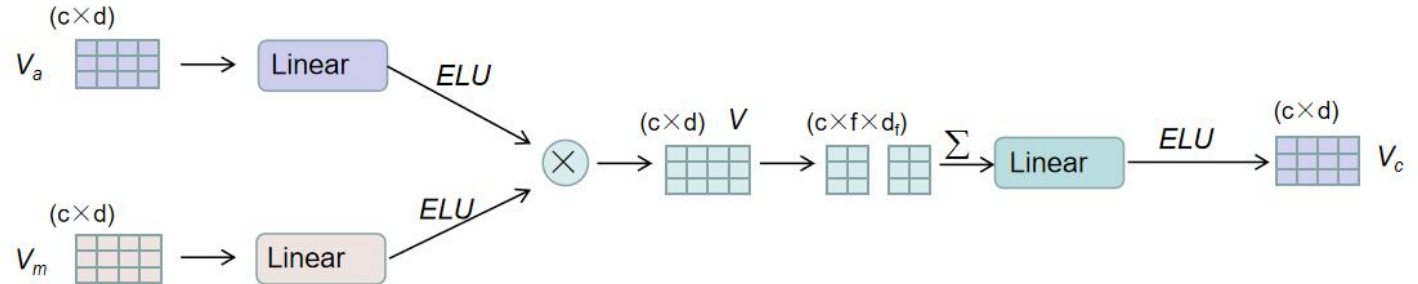
再将视觉外观特征和视觉动作特征进行融合,得到了表示每个片段的外观-动作融合视觉特征Vc
进而将视频中的每一个片段特征进行了融合,通过自注意力的机制得到整个视频的融合特征表示:
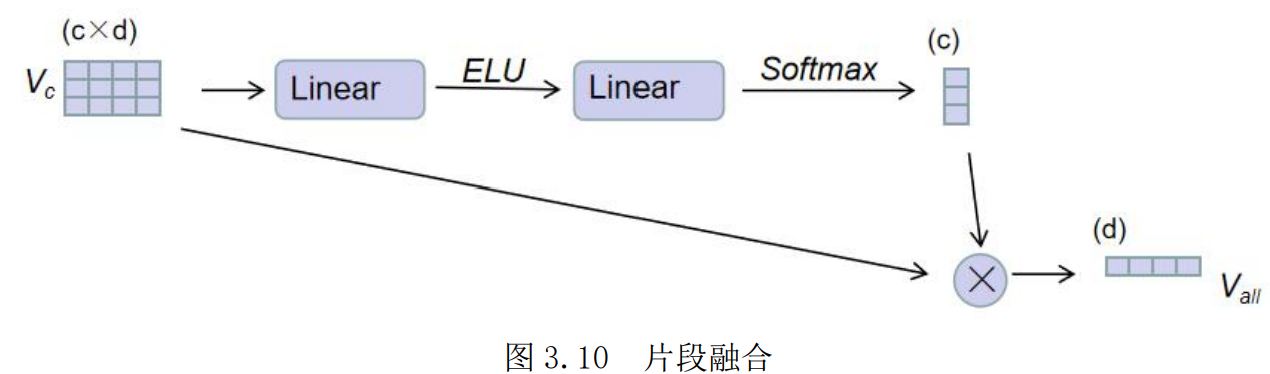
总结一下:
答案生成模块
至此,模型得到了与文本交互后的融合视觉特征,现在只需要要通过该视频信息回答问题。首先,将语义特征 q 通过一层线性层后,与视觉特征Vall进行拼接,得到融合特征y。最后特征维度映射为答案分类数目。
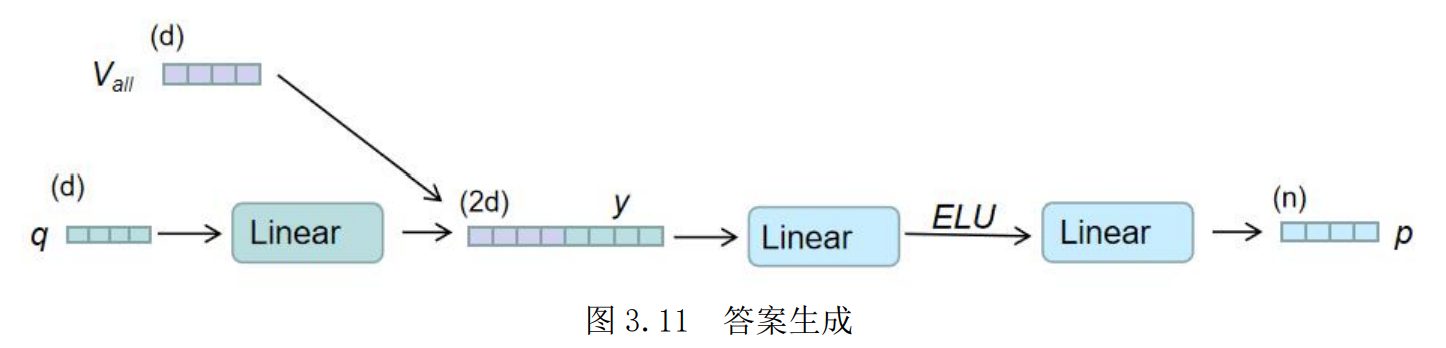
最后做一个总结:
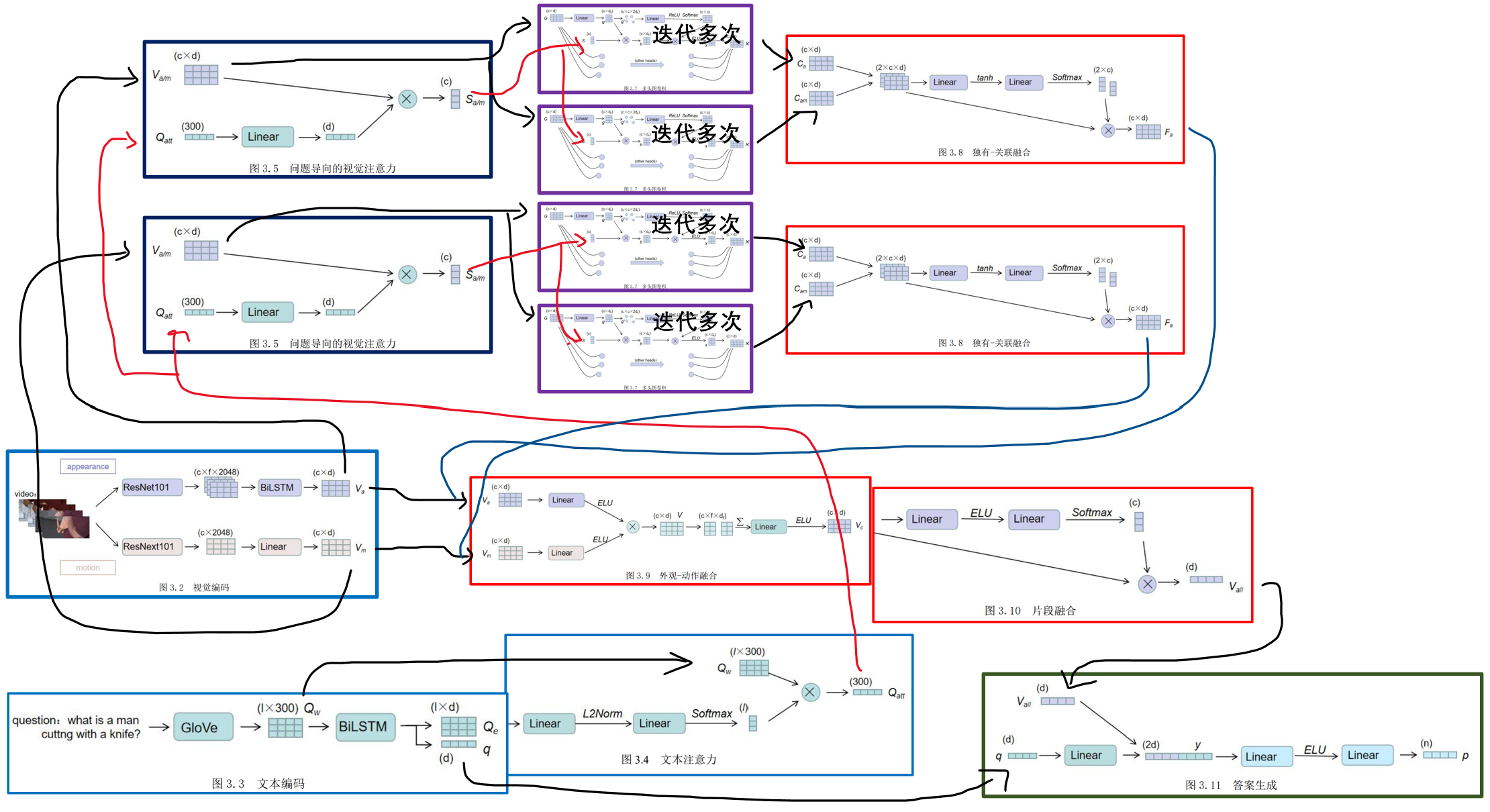
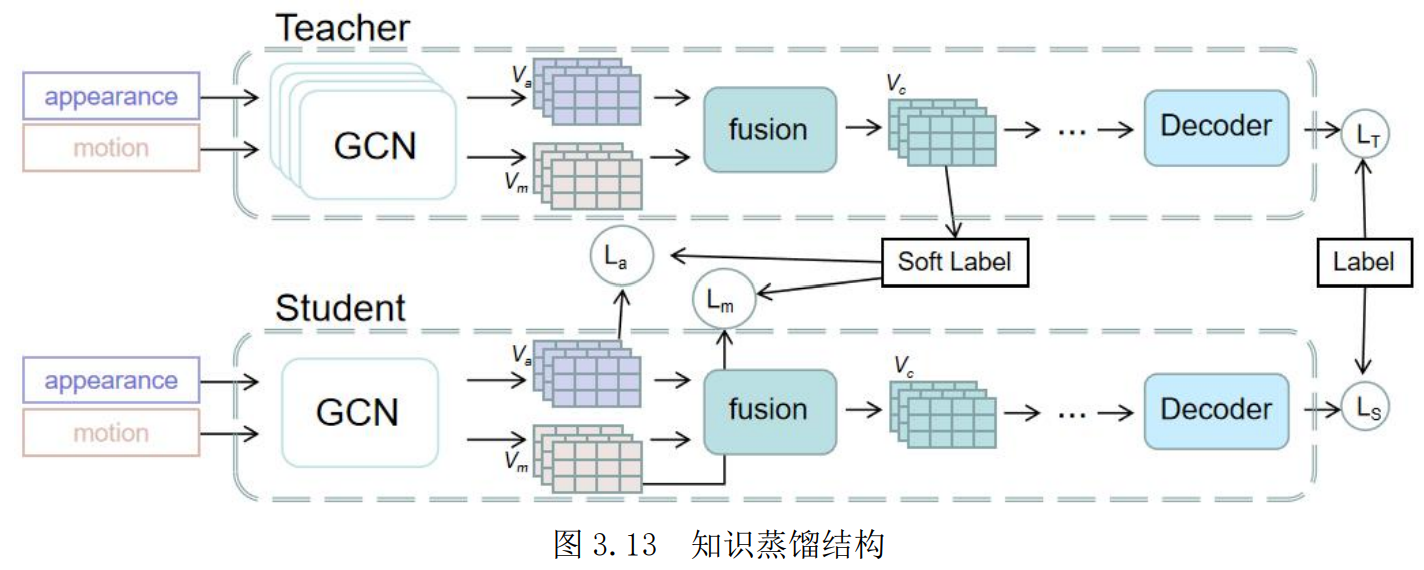
多模态知识蒸馏架构
在教师模型中,模型使用了多层的图卷积对视觉特征进行了迭代计算,这是因为模型只有在迭代进行多次的图卷积计算后,才可以更好地实现视频关系的多步推理,提取关系特征。而在学生模型的构造上,只使用了单层的图卷积来处理视觉特征,以轻量化模型的体量,压缩模型。
首先本方法完整训练一个教师模型,并通过实验进行参数调节,得到了训练得较好的教师模型。接着在学生模型训练时,将教师模型中外观视觉特征与动作视觉特征融合后的融合视觉特征,分别用于学生模型的外观和动作的视觉特征的学习。