图像生成:GAN、AE、VAE、DALL-E2、Stable Diffusion
GAN
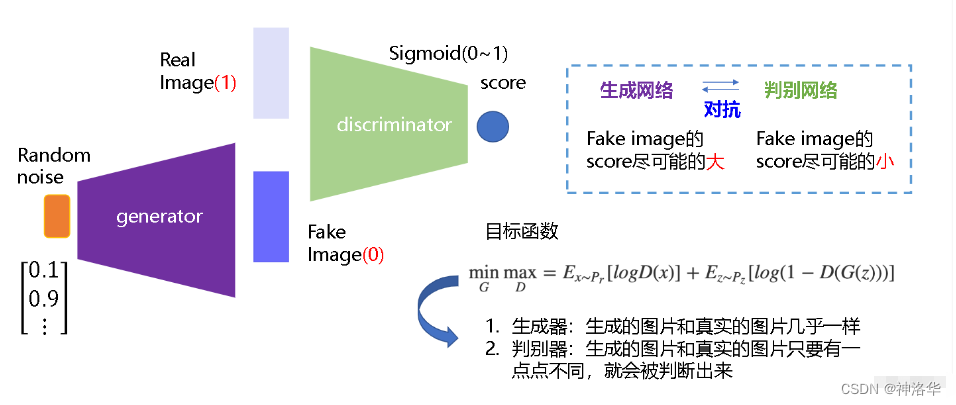
GANs(Generative Adversarial Networks,生成对抗网络)是从对抗训练中估计一个生成模型,其由两个基础神经网络组成,即生成器神经网络G(Generator Neural Network) 和判别器神经网络D(Discriminator Neural Network)。
生成器G从给定噪声中(一般是指均匀分布或者正态分布)采样来合成数据,判别器D用于判别样本是真实样本还是G生成的样本。G的目标就是尽量生成真实的图片去欺骗判别网络D,使D犯错;而D的目标就是尽量把G生成的图片和真实的图片分别开来。二者互相博弈,共同进化,最终的结果是D(G(z)) = 0.5,此时G生成的数据逼近真实数据(图片、序列、视频等)。
GANs也有很多局限性,比如:
- 训练不够稳定。因为要同时训练两个网络,就涉及到平衡问题。经常训练不好,模型就坍塌了,所以这个缺点非常致命。
- GANs生成的多样性不够好。GANs其主要的优化目标,就是让图片尽可能的真实。其生成的多样性,主要就来自于初始给定的随机噪声,所以创造性(原创性)不够好。
- GANs是隐式生成,不够优美。GANs不是概率模型,其生成都是通过一个网络去完成,所以GANs的生成都是隐式的。不知道模型都训练了什么,也不知道其遵循什么分布,在数学上就不如后续的VAE或扩散模型优美。
AutoEncoder
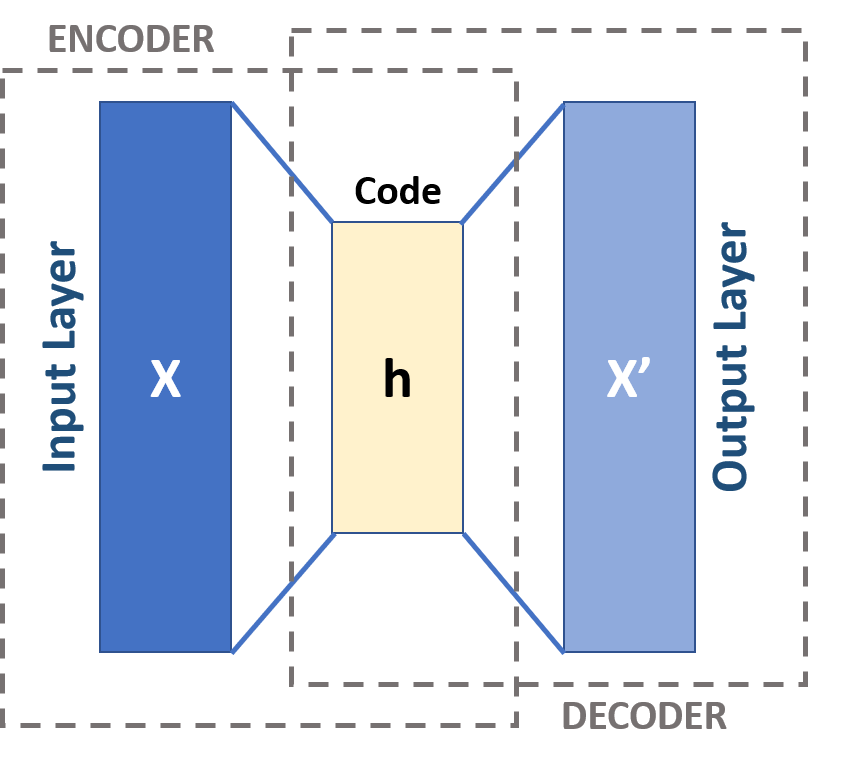
AE自编码器是一种瓶颈架构( bottleneck),它使用编码器将高维输入x转换为潜在的低维Code h ,然后使用解码器将潜在Code h 进行重构,得到最终的输出x′ 。目标函数就是希望x′ 能尽量的重建x。因为是自己重建自己,所以叫Autoencoder。
DAE/MAE
紧跟着AE之后,出来了DAE(Denoising Autoencoder),就是先把原图x进行一定程度的打乱,变成 $x_c$(corrupted x)。然后将 $x_c$ 传给编码器,后续都是一样的,目标函数还是希望x ′ 能尽量的重建原始的x 。
这个改进非常有用,会让训练出来的模型非常的稳健,也不容易过拟合,尤其是对于视觉领域来说。因为图像的像素信息,冗余性非常高。即使把图片进行一定的扰乱(污染),模型还是能抓取其主要特征,重构原图。
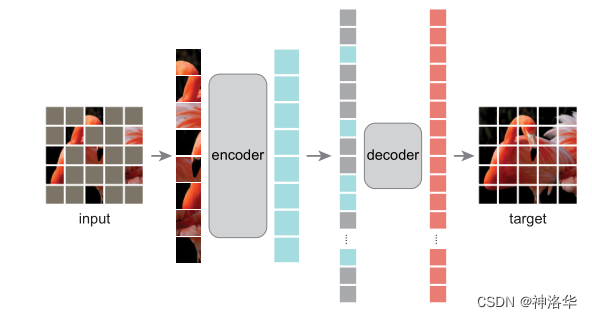
这一点也类似MAE(Masked Autoencoder,掩码自编码器)的意思。作者在训练时,将图像75%的像素区域都masked掉(下图序列中灰色就是被masked的区域,不会传入decoder)。即使这样,模型也能将最终的图像重构出来,可见图像的冗余性确实是很高。作者在MAE论文中反复强调,高掩码率是非常重要的,所以说DAE或者MAE这种操作还是非常有效的。
变分自编码器VAE
上面的AE/DAE/MAE都是为了学习中间的特征h,然后拿这些特征去做后续的分类、检测、分割这些任务,而并不是用来做生成的。因为中间学到的h不是一个概率分布,只是一个专门用于重构的特征,所以没法对其进行采样。
VAE(Variational Auto-Encoder)就是借助了这种encoder-decoder的结构去做生成,和AE最主要的区别就是不再去学习中间的bottleneck特征了,而是去学习一种分布。
作者假设中间的分布是一个高斯分布(用均值 $\mu$ 和方差 $\sigma$ 来描述)。具体来说,就是将输入x 进行编码得到特征之后,再接一些FC层,去预测中间分布的 $\mu$ 和 $\sigma$。
$\mu$ 和 $\sigma$ 训练好之后,就可以扔掉encoder了。推理时直接从训练好的分布去采样一些 z 出来,然后进行解码,这样VAE就可以用来做生成了。
\[z=\mu +\sigma \cdot \varepsilon\]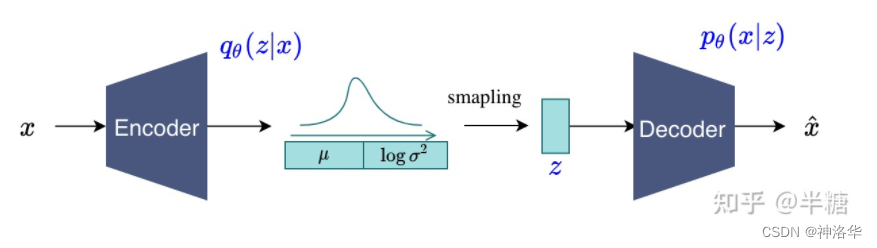
从贝叶斯概率的角度看,前面的从x预测z的过程就是后验概率 \(q_{\theta }(z|x)\) ,学出来的分布就是先验分布。后面给定z预测x就是likelihood(似然),模型的训练过程就是maximize likelihood。
更多参考:变分自编码器(一):原来是这么一回事
VAE是从概率分布中去采样,所以其生成的多样性比GANs好得多。所以这也是为什么后续有一系列基于VAE的工作,比如VQ-VAE/VQ-VAE-2,以及基于VQ-VAE的DALL·E。
VQ-VAE
VQ即Vector Quantised,它编码出的向量是离散的,也就是把VAE做量化,所以VQ-VAE最后得到的编码向量的每个元素都是一个整数。
现实生活中,很多信息(声音、图片)都是连续的,你的大部分任务都是一个回归任务。但是等你真正将其表示出来,等你真正解决这些任务的时候,我们都将其离散化了。图像变成了像素,语音也抽样过了,大部分工作的很好的也都是分类模型(回归任务→分类任务)。
如果还是之前VAE的模式,就不好把模型做大,分布也不好学。取而代之的不是去直接预测分布 z,而是用一个codebook代替。codebook可以理解为聚类的中心,大小一般是K*D(K=8192,Dim=512/768),也就是有8192个长为D的向量(聚类中心)。
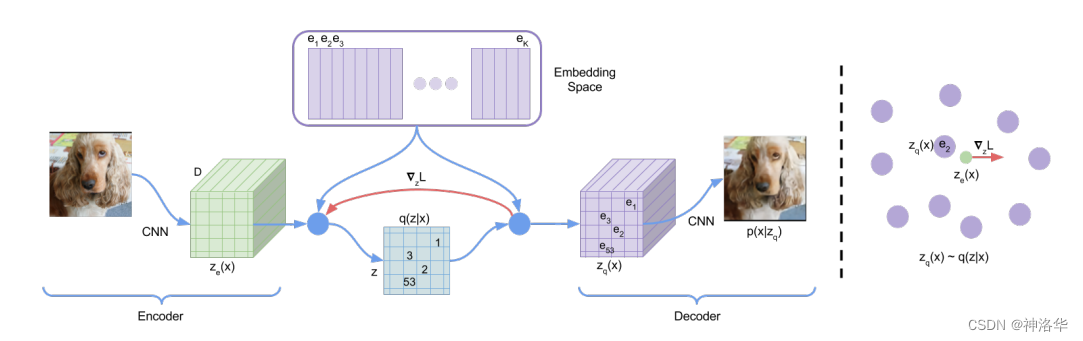
x 输入编码器得到高宽分别为 (h,w) 的特征图 f,然后计算特征图里的向量和codebook里的向量(聚类中心)的相似性。接着把和特征图最接近的聚类中心向量的编号(1-8192)存到矩阵 z 里面。
训练完成之后,不再需要编码特征 f ,而是取出矩阵 z 中的编号对应的codebook里面的向量,生成一个新的特征图 $f_q$(量化特征quantized feature)。最后和之前一样,使用 $f_q$ 解码重构原图。此时这个量化特征就非常可控了,因为它们永远都是从codebook里面来的,而非随机生成,这样优化起来相对容易。
- 图左:VQ-VAE的模型结构
- 图右:embedding space可视化。编码器输出 $z(x)$ 会mapped到最相近(nearest)的点 $e_2$
- 红色线的梯度 $\triangledown _{z}L$ 迫使encoder在下一次forward时改变其输出(参数更新)。
- 由于编码器的输出和解码器的输入共享D维空间,梯度包含了编码器如何改变参数以降低损失的有效信息。
VQ-VAE学习的是一个固定的codebook,所以它又没办法像VAE这样随机采样去做生成。所以说VQ-VAE不像是一个VAE,而更像是一个AE。它学到的codebook特征是拿去做high-level任务的(分类、检测)。
如果想让VA-VAE做生成,就需要单独训练一个prior网络,在论文里,作者就是训练了一个pixel-CNN(利用训练好的codebook去做生成)。
VQ-VAE2
是对VQ-VAE的简单改进,是一个层级式的结构。VQ-VAE2不仅做局部的建模,而且还做全局的建模(加入attention),所以模型的表达能力更强了。同时根据codebook学了一个prior,所以生成的效果非常好。总体来说VQ-VAE2是一个两阶段的过程:
- 训练编解码器,使其能够很好的复现图像
- 训练PixelCNN自回归模型,使其能够拟合编码表分布,从而通过随机采样,生成图片
DALL·E
VQ-VAE的生成模式是pixel-CNN +codebook,其中pixel-CNN就是一个自回归模型。OpenAI 一看,这不是到了施展自己看家本领GPT的时候了吗,所以果断将pixel-CNN换成GPT。再加上最近多模态相关工作的火热进展,可以考虑使用文本引导图像生成,所以就有了DALL·E。
根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词,这种类型的LM被称为自回归语言模型。如,GPT,ELMO
DALL·E和VQ-VAE-2一样,也是一个两阶段模型:
Stage1:Learning the Visual Codebook
输入:一对图像-文本对(训练时)。
编码特征:文本经过BPE编码得到256维的特征 $f_t$ ;图像(256×256)经过VQ-VAE得到图片特征 $f_q$ (就是上面训练好的VQ-VAE,将其codebook直接拿来用。 $f_q$ 维度下降到32 ×32)
Stage2:Learning the Prior
重构原图:将 $f_q$ 拉直为1024维的tokens,然后连上256维的文本特征 $f_t$,这样就得到了1280维的token序列。遮盖掉一些部分送入GPT(masked decoder)重构。
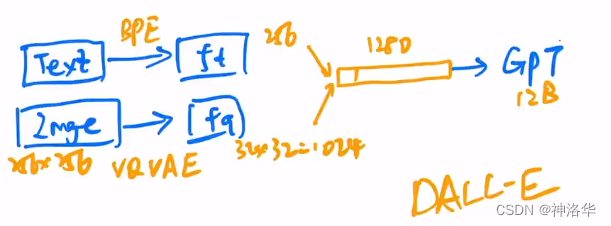
推理
推理时,输入文本经过编码得到文本特征,再将文本通过GPT利用自回归的方式生成图片。生成的多张图片会通过CLIP模型和输入的文本进行相似度计算,然后调出最相似(描述最贴切)的图像。 另外还有很多训练细节,DALL·E中有近一半的篇幅是在说明如何训练好这120亿参数的模型,以及如何收集足以支撑训练如此大规模模型的数据集(大力出奇迹)。
扩散模型
简单来说,扩散模型包含两个过程:前向扩散过程(forword)和反向生成过程(reverse):
- 前向扩散过程:给定一张图片 $x_0$ ,然后逐步往里面添加一个很小的正态分布噪声。累计t步之后,我们得到了 $x_t$,如果扩散步数T足够大,那么最终得到的就完全丢失了原始数据而变成了一个随机噪声(各同向性的正态分布)。
- 反向生成过程:从随机噪音开始逐步去噪音直至生成一张图像(去噪)

局限性:训练推理慢
扩散模型最大的一个局限性就是训练和推理特别的慢。对于GANs来说,推理时forword一次就能生成结果了,但是扩散模型要forword多次,非常的慢。特别是最原始的扩散模型, t=1000等于选了一个随机噪声之后,要forword一千次,一点点的把图像恢复出来,才能得到最终的生成结果,所以扩散模型做推理是最慢的。
DDPM
原始的扩散模型很难训练,DDPM对原始的扩散模型做了一定的改进,使器优化过程更加的简单。DDPM第一次使得扩散模型能够生成很好的图片,算是扩散模型的开山之作。
作者认为,每次直接从 $x_{t}$ 预测 $x_{t-1}$ ,这种图像到图像的转化不太好优化。所以作者考虑直接去预测这一步所添加的噪声 $\varepsilon$,这样就简化了问题。
这种操作就有点类似ResNet的残差结构。每次新增一些层,模型不是直接从x去预测y(这样比较困难),而是让新增的层去预测(y-x)。这样新增层不用全部重新学习,而是学习原来已经学习到的x和真实值y之间的残差就行(residual)
具体来说采用了U-Net模型结构。原先U-Net是用编码器将图片一点点的压缩,再用一个解码器将其一步步的恢复回来,所以其输入输出大小始终是一样的,非常适合做扩散模型的backbone。在DDPM中预测的是噪声。
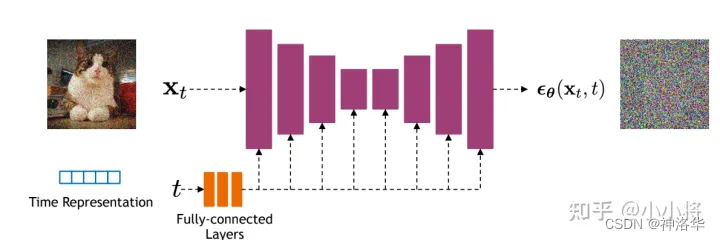
U-Net模型输入,除了当前时刻的 $x_{t}$ ,还有一个输入time embedding(类似transformer里的正弦位置编码),主要用于告诉 U-Net模型,现在到了反向过程的第几步。time embedding的一个重要功能就是引导U-Net生成。
U-Net的每一层都是共享参数的,那怎样让其根据不同的输入生成不同的输出呢?因为我们希望从随机噪声开始先生成大致轮廓(全局特征),再一步步添加细节生成逼真的图片(局部特征)。
这个时候,有一个time embedding可以提醒模型现在走到哪一步了,我的生成是需要糙一点还是细致一点。所以添加time embedding对生成和采样都很有帮助,可以使模型效果明显提升。
improved DDPM
DDPM使得扩散模型可以在真实数据集上work得很好之后,一下子吸引了很多人的兴趣。因为DDPM在数学上特别的简洁美观,无论正向还是逆向,都是高斯分布,可以做很多推理证明;而且还有很多不错的性质。
improved DDPM相比DDPM做了几点改动:
- DDPM的逆向过程中,高斯分布的方差项直接使用一个常数而不用学习。improved DDPM作者就觉得如果方差效果应该会更好,改了之后果然取样和生成效果都好了很多。
- DDPM添加噪声时采用的线性的variance schedule改为余弦schedule,效果更好(类似学习率从线性改为余弦)。
- 简单尝试了把模型做得更大更复杂之后生成效果更好。
Diffusion Models Beat GANs
比之前的improved DDPM又做了一些改进:
- 使用更复杂的模型:加大加宽网络、使用更多的自注意力头attention head,加大自注意力scale(single-scale attention改为multi-scale attention)。
- 使用classifier guidance的方法,引导模型进行采样和生成。这样不仅使生成的图片更逼真,而且加速了反向采样过程。论文中,只需要25次采样,就可以从噪声生成图片。
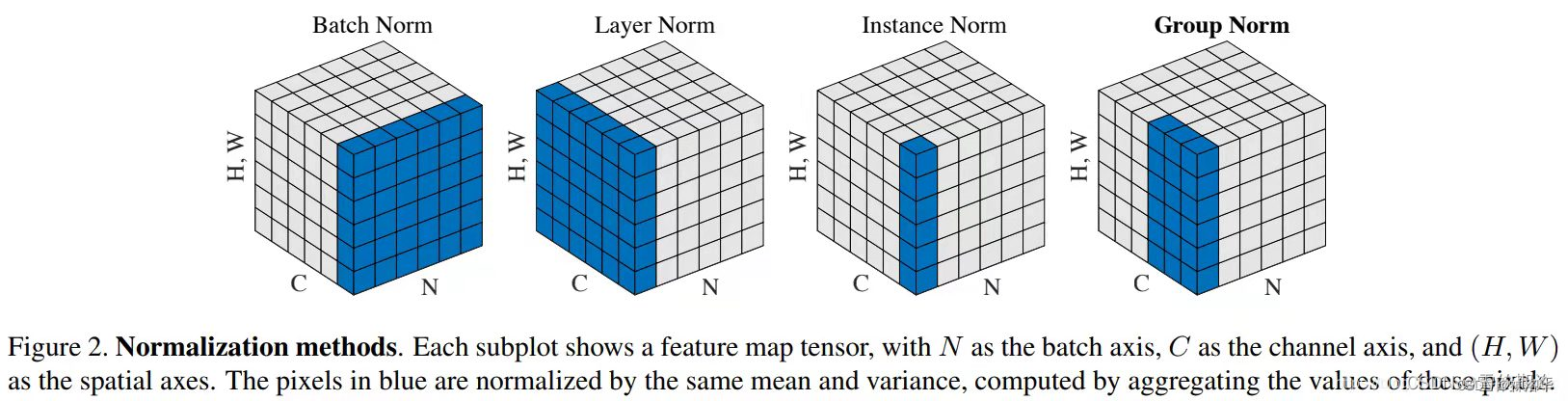
- 提出了新的归一化方式——Adaptive Group Normalization,在文章就是根据步数进行自适应的归一化。这个方法是对group归一化的一个改进:
classifier guidance
在Diffusion Models Beat GANs这篇论文之前,扩散模型生成的图片也很逼真,但是在算IS score、FID score时,比不过GANs。这样的话,大家会觉得你论文里生成的那些图是不是作者精心挑选的呢,所以结果不够有信服力,这样就不好过稿不好中论文了。
IS(Inception Score)和FID(Frechet Inception Distance score)是当前流行的图像生成模型判别指标。简单说就是
IS从生成图片的真实性和多样性评价生成模型,分数越高越好;FID用于衡量真实图像和生成图像的“距离”,分数越小越好。
刷分还是很重要的,同时扩散模型采样和生成图片非常的慢,所以作者考虑如果有一种额外的指导可以帮助模型进行采样和生成就好了。于是作者借鉴了之前的一种常见技巧classifier guided diffusion,即在反向过程训练U-Net的同时,也训练一个简单的图片分类器。这个分类器是在图片加了很多噪声的ImageNet上训练的,因为扩散模型的输入始终是加了很多噪声的,跟真实的ImageNet图片是很不一样的,所以是从头训练的。
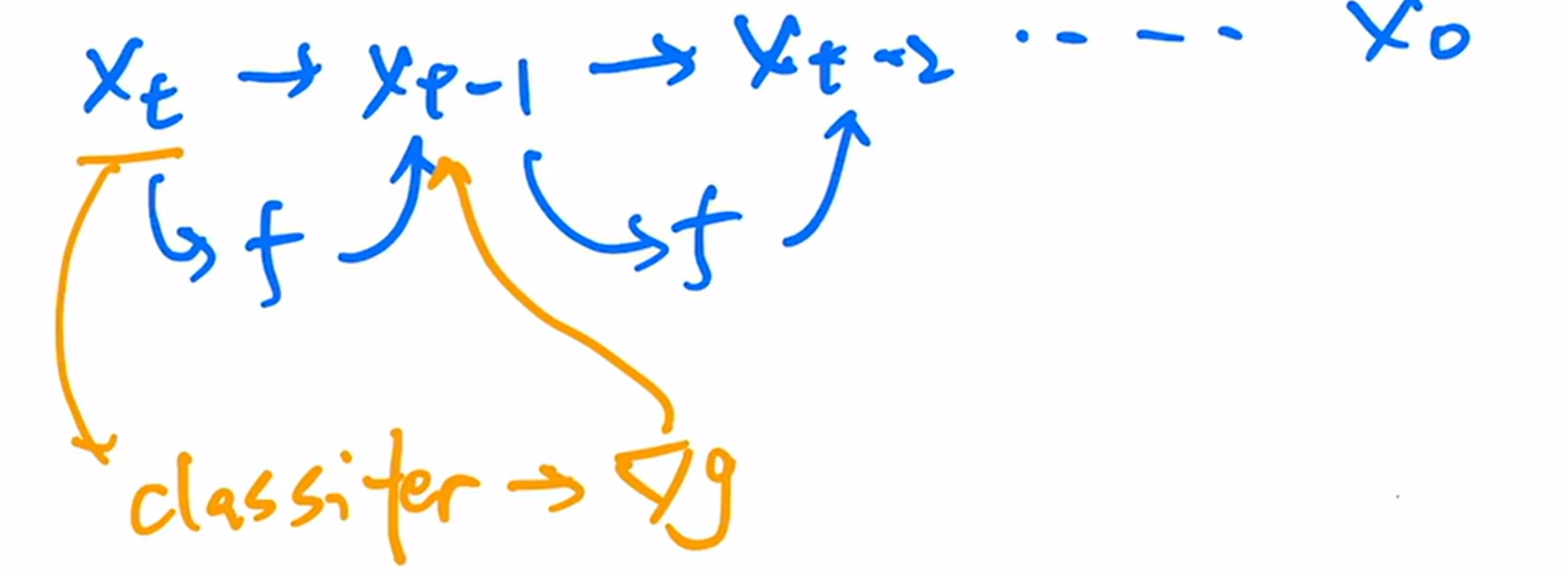
当采样 $x_t$ 之后,扔给分类器,就可以看到图片分类是否正确,这时候就可以算一个交叉熵目标函数,对应的就得到了一个梯度。之后使用分类器对 $x_t$ 的梯度信息$\nabla_{x_t}\text{log}p_{\theta}(x_t)$ 指导扩散模型的采样和生成。
这个梯度暗含了当前图片是否包含物体,以及这个物体是否真实的信息。通过这种梯度的引导,就可以帮助
U-Net将图片生成的更加真实,要包含各种细节纹理,而不是意思到了就行,要和真实物体匹配上。
使用了 classifier guidance之后,生成的效果逼真了很多,在各种inception score上分数大幅提高。也就是在这篇论文里,扩散模型的分数第一次超过了BigGANs。不过作者也说了,这样做其实是牺牲了一些多样性(对于无条件的扩散模型,分类器梯度的指导提升了模型按类输出的性能),去换取了生成图片的逼真性(写实性)。但这样取舍还是值得的,因为其多样性和逼真度还是比GANs好,一下子奠定了扩散模型在图像生成领域的地位。
除了最简单最原始的classifier guidance之外,还有很多其它的引导方式。
- CLIP guidance:将简单的分类器换成CLIP之后,文本和图像就联系起来了。此时不光可以利用这个梯度引导模型采用和生成,而且可以利用文本指导其采样和生成。(原来文生图是在这里起作用)
- image侧引导:除了利用图像重建进行像素级别的引导,还可以做图像特征和风格层面的引导,只需要一个gram matrix就行。
- text侧:可以用训练好的NLP大模型做引导
以上所有引导方式,都是下面目标函数里的 y,即模型的输入不光是 $x_{t}$ 和time embedding ,还有condition(公式中的y)。加了condition之后,可以让模型的生成又快又好。
\[p(\mathbf{x}_{t-1} \vert \mathbf{x}_t)=\left \| z-f_{\theta }(x_{t},t,y) \right \|\]classifier free guidance
由于所有的classifier guidance方法中都需要额外引入一个网络来指导,推理的时候比较复杂(扩散模型需要反复迭代,每次迭代都需要额外算一个分数),所以引出了后续工作classifier free guidance(有条件生成监督无条件生成)。
classifier free guidance的方式,只是改变了模型输入的内容,除了 conditional输入外(随机高斯噪声输入加引导信息)还有 unconditional 的 采样输入。两种输入都会被送到同一个 diffusion model 从而让其能够具有无条件和有条件生成的能力。
得到有条件输出$f_{\theta }(x_{t},t,y)$ 和无条件输出 $f_{\theta }(x_{t},t,\phi )$ 后,就可以用前者监督后者,来引导扩散模型进行训练了。最后反向扩散做生成时,我们用无条件的生成,也能达到类似有条件生成的效果。这样一来就摆脱了分类器的限制,所以叫classifier free guidance。
举个例子,比如在训练时使用图像-文本对,这时可以使用文本做指导信号,也就是训练时使用文本作为 y生成图像。然后把 y去掉,替换为一个空集 $\phi$(空的序列),生成另外的输出。
扩散模型本来训练就很贵了,classifier free guidance这种方式在训练时需要生成两个输出,所以训练更贵了。但是这个方法确实效果好,所以在GLIDE 、DALL·E2和Imagen里都用了,而且都提到这是一个很重要的技巧。用了这么多技巧之后,GLIDE终于是一个很好的文生图模型了,只用了35亿参数,生成效果和分数就比DALL·E(120亿参数)还好。
OpenAI一看GLIDE这个方向靠谱,就马上跟进,不再考虑DALL·E的VQ-VAE路线了。将GLIDE改为层级式生成(56→256→1024)并加入prior网络等等,最终得到了DALL·E2。
DALL·E2
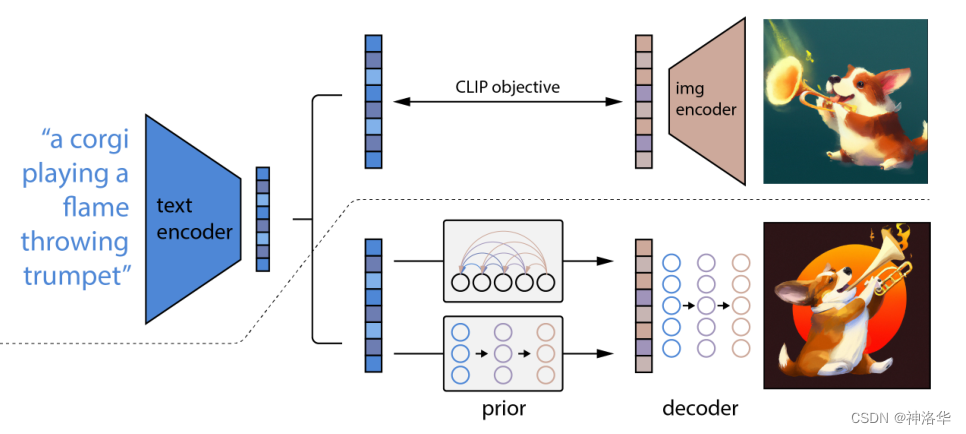
论文题目——Hierarchical Text-Conditional Image Generation with CLIP Latents,意为根据CLIP特征,来做层级式的、依托于文本特征(条件)的图像生成。
- 这里层级式(Hierarchical)的意思是,DALL·E2先生成小分辨率的图片(
64*64),再生成256*256的图片,最后生成1024*1024的高清大图,所以是一个层级式的结构。 - 另外DALL·E2中还用到了CLIP模型训练的文本图片对特征,以及使用扩散模型来解码生成图片,
DALL·E2其实就是CLIP模型加上GLIDE模型的融合。
CLIP训练过程
前置知识:CLIP
看一下模型图,上部分就是一个CLIP,下部分才是DALL·E2
CLIP的输入是一对对配对好的的图片-文本对(比如输入是一张狗的图片,对应文本也表示这是一只狗)。这些文本和图片分别通过Text Encoder和Image Encoder输出对应的特征。然后在这些输出的文字特征和图片特征上进行对比学习。
CLIP使用的数据集是OpenAI从互联网收集的4个亿的文本-图像对,所以模型的两个编码器训练的非常好,而且文本和图像特征紧紧的联系在一起,这也是CLIP可以直接实现zero-shot的图像分类的原因。
DALL·E2训练过程
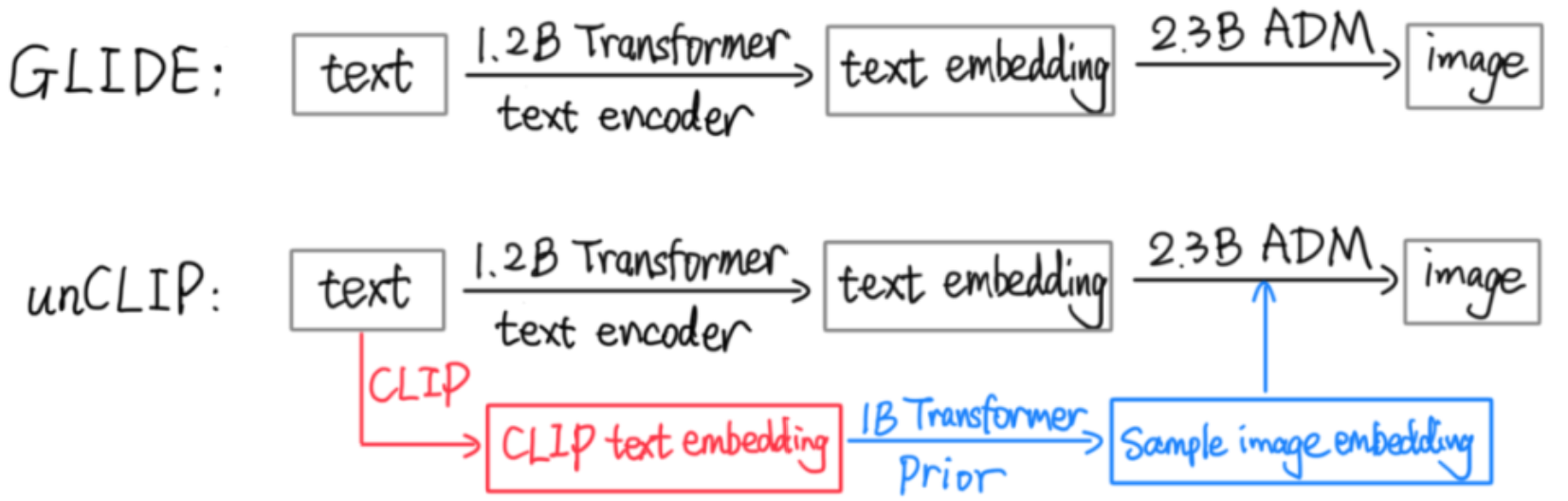
上面的CLIP训练好之后,就将其冻住了,不再参与任何训练和微调。DALL·E2训练时,输入也是文本-图像对。两阶段训练:
prior:根据文本特征生成图像特征
文本和图片分别通过锁住的CLIP text encoder和CLIP image encoder得到编码后的文本特征和图片特征。(这里文本和文本特征是一一对应的,因为这部分是始终锁住的,图片部分也一样)
prior模型的输入就是上面CLIP编码的文本特征,其ground truth就是CLIP编码的图片特征,利用文本特征预测图片特征,就完成了 prior的训练。
推理时,文本还是通过CLIP text encoder得到文本特征,然后根据训练好的prior得到类似CLIP生成的图片特征(此时没有图片,所以没有CLIP image encoder这部分过程)。此时图片特征应该训练的非常好,不仅可以用来生成图像,而且和文本联系的非常紧(包含丰富的语义信息)。
decoder:常规的扩散模型解码器
解码生成图像。这里的decoder就是升级版的GLIDE,所以说DALL·E2=CLIP+GLIDE。
其实最暴力的方法,就是直接根据文本特征生成图像,只要中间训练一个融合特征的大模型就行。但是如果有显式的生成图片特征的过程(也就是
文本→文本特征→图片特征→图片),再由图像特征生成图像,模型效果就会好很多,所以采用了两阶段生成方式。
Stable Diffusion
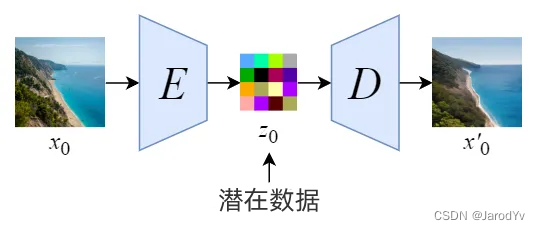
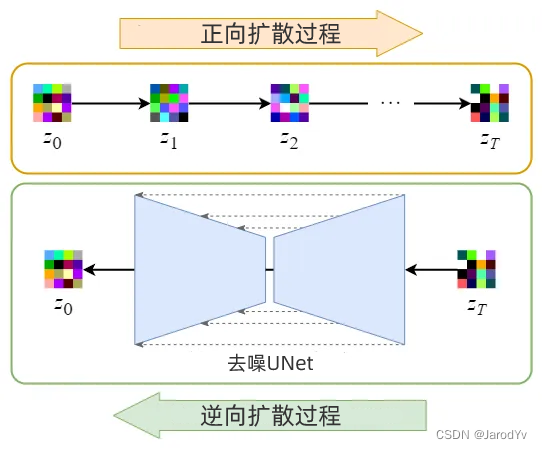
Stable Diffusion 一开始的名称是“潜在扩散模型”(Latent Diffusion Model)。顾名思义,Stable Diffusion 发生在潜在空间中,由于潜在数据的大小比原始图像小得多,因此去噪过程会快得多。
我们首先训练一个自动编码器来学习如何将图像数据压缩成低维表示。
- 通过使用经过训练的编码器 E,我们可以将全尺寸图像编码为低维潜在数据(压缩数据)。
- 通过使用经过训练的解码器 D,我们可以将潜在数据解码回图像。
将图像编码为潜在数据后,将在潜在空间中进行正向和反向扩散过程。
- 正向扩散过程 → 向潜在数据添加噪声。
- 逆向扩散过程 → 从潜在数据中去除噪声。
Stable Diffusion 真正强大之处在于它可以根据文本提示生成图像。这是通过接受调节输入修改内部扩散模型来实现的。
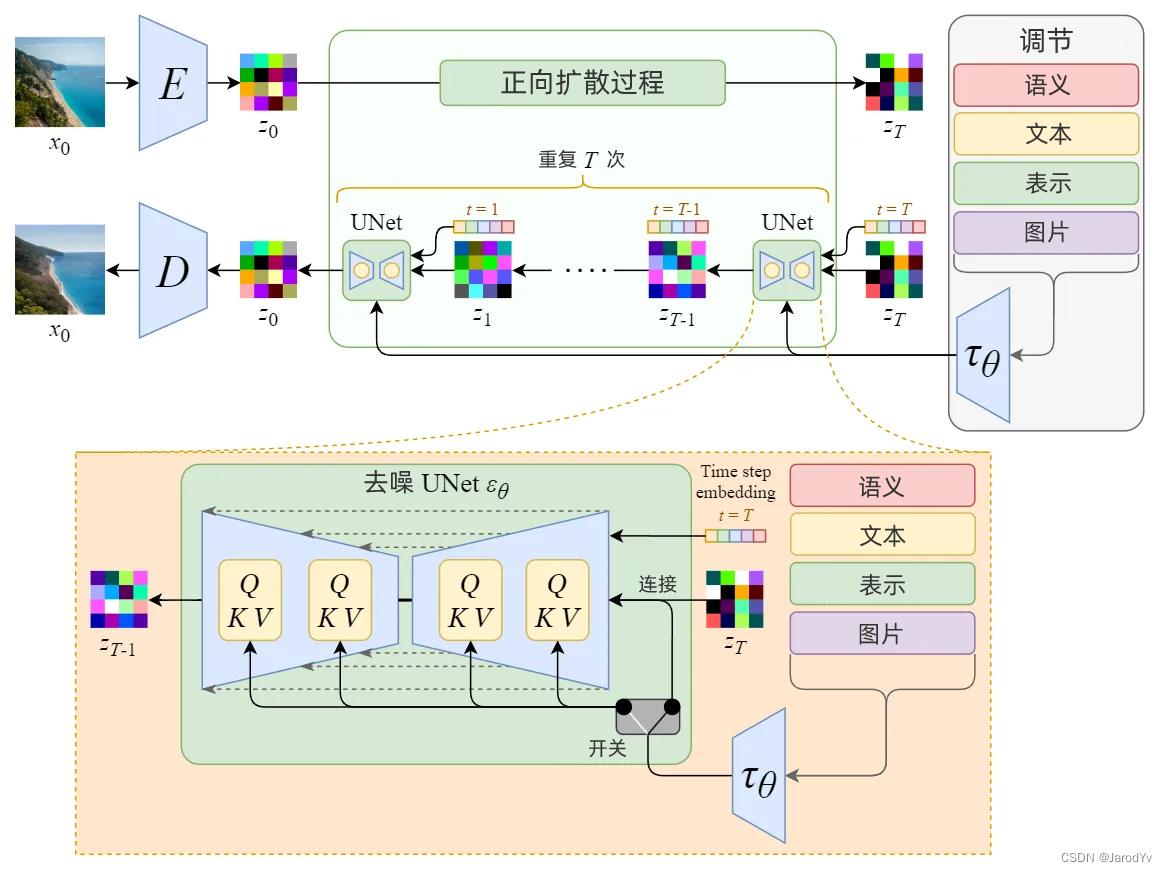
通过使用交叉注意机制增强其去噪 U-Net,将内部扩散模型转变为条件图像生成器。
上图中的开关用于在不同类型的调节输入之间进行控制:
- 对于文本输入,首先使用语言模型 $\tau_\theta$ (例如 BERT、CLIP)将文本转换为嵌入(向量),然后通过(多头)注意力 Attention(Q, K, V)映射到 U-Net 层。
- 对于其他空间对齐的输入(例如语义映射、图像、修复),可以使用连接来完成调节。