LLaMA-Factory 实战记录
本文旨在完整记录一次利用开源框架LLaMA-Factory对Qwen2.5-VL-7B-Instruct模型进行微调(SFT、RL)的全过程。内容涵盖环境配置、任务定义、数据准备、训练策略、过程监控、推理验证、结果分析与部署。
环境准备
使用了如下软硬件及模型资源:
- 硬件环境: 本次实践基于8张NVIDIA A800(80GB显存)GPU服务器。
- 微调框架: LLaMA-Factory,一个集成了多种微调方法的用户友好型开源框架。具体安装方式请遵循其官方GitHub仓库指南:https://github.com/hiyouga/LLaMA-Factory
- 基础模型: Qwen2.5-VL-7B-Instruct,由阿里巴巴通义千问团队开源的70亿参数视觉语言模型。模型权重(约16GB)可通过ModelScope进行下载:https://modelscope.cn/models/Qwen/Qwen2.5-VL-7B-Instruct
- 推理与部署:vLLM,一个用于 LLM 推理的高效开源框架。它通过优化内存管理和批处理技术,显著提高了LLM 推理的性能和吞吐量。vLLM 允许用户在不改变模型结构的情况下,实现比传统方法快数倍的推理速度,并降低推理延迟:https://docs.vllm.ai/en/latest/
任务定义
本次微调的核心任务是一个复杂的、基于规则的视觉二分类问题。模型需要根据输入的图片和一系列详尽的文本要求,判断图片中的场景陈列是否合规。如下这个例子非真实数据:
输入:
1
2
3
4
5
6
7
8
9
<图片>判断以上图片是否满足要求:
1. 只存在正方体、圆柱、立体圆环、五星徽章、台灯状立体,不能出现其他物体
2. 正方体与圆柱位于前方,横向排列,面积大于1m*1m
3. 五星徽章需放在立体圆环里面
4. 左上角水印,展示每个物体数量,需要和图片中物体对应
5. 左下角水印,展示台灯状立体在图片中的位置,需要和图片中物体对应
6. 右上角水印,为正方体与圆柱的数量加和,需要和图片中物体对应
7. 右下角水印,为五星徽章和立体圆环的数量乘积,需要和图片中物体对应
输出:
1
满足要求/不满足要求
此任务不仅考验模型的视觉识别能力,更对其遵循复杂指令、进行逻辑推理和空间关系判断的能力提出了较高要求。
数据准备
为了适配模型的训练,我们将图文数据对整理为ShareGPT格式,并存为my_dataset.json文件。该格式以多轮对话的形式组织数据,结构清晰。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
[
{
"messages": [
{
"role": "system",
"content": "你是一个视觉分类任务专家。请根据以下要求判断图片是否满足要求。"
},
{
"role": "user",
"content": "<image>判断以上图片是否满足要求:\n1. 只存在正方体、圆柱、立体圆环、五星徽章、台灯状立体,不能出现其他物体\n2. 正方体与圆柱位于前方,横向排列,面积大于1m*1m\n3. 五星徽章需放在立体圆环里面\n4. 左上角水印,展示每个物体数量,需要和图片中物体对应\n5. 左下角水印,展示台灯状立体在图片中的位置,需要和图片中物体对应\n6. 右上角水印,为正方体与圆柱的数量加和,需要和图片中物体对应\n7. 右下角水印,为五星徽章和立体圆环的数量乘积,需要和图片中物体对应\n请只输出如下格式:\"满足要求\", 或 \"不满足要求\"。不需要额外解释。请严格按照格式输出,否则判为无效答案。"
},
{
"role": "assistant",
"content": "满足要求"
}
],
"images": [
"/data/img_01.jpg"
]
},
]
messages: 包含系统(system)、用户(user)、助手(assistant)三方角色的对话历史。images: 包含与对话相关的图片路径列表。特殊占位符<image>在user内容中指代图片。
同时,需要在data/dataset_info.json中注册此数据集,以便框架能够正确解析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
"my_dataset": {
"file_name": "my_dataset.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
}
训练配置
配置如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
### model
model_name_or_path: /data/modelscope/Qwen2___5-VL-7B-Instruct
image_max_pixels: 262144
video_max_pixels: 16384
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: my_dataset
template: qwen2_vl
cutoff_len: 131072
max_samples: 3000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: /output/my_task
logging_steps: 10
save_steps: 100
plot_loss: true
overwrite_output_dir: false
save_only_model: false
report_to: tensorboard # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 30
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 50
核心目标:在一个强大且预训练好的视觉语言模型(Qwen2.5-VL-7B-Instruct)的基础上,使用 LoRA 的高效微调技术,来训练它适应我们的任务。整个过程属于监督微调 (SFT) 阶段。LoRA技术冻结模型主体,只训练新增的、极少量的“适配器”参数,从而大大提升训练效率。
重要配置解释:
stage: sft: 指定训练阶段为监督微调 (Supervised Fine-Tuning),即模型从“输入-输出”样本对中学习。lora_rank: 8: LoRA方法的关键超参数,定义了“适配器”的规模。8是一个在效果和资源消耗上都很平衡的常用值。对于复杂任务,可以考虑增大lora_rank,从16 开始,再尝试 32、64…… 当然要观察验证集损失防止过拟合,例如考虑将学习率减半lora_target: all: Llama Factory 的一个便捷设置,它会自动找出模型中所有适合应用LoRA的层(如注意力层)并进行适配。template: qwen2_vl: 指定了将数据格式化成 Qwen2-VL 模型能理解的特定提示(Prompt)格式。per_device_train_batch_size: 1: 每个GPU设备一次处理1个样本。gradient_accumulation_steps: 8: 梯度累积8步之后再更新一次模型参数。这会形成1 * 8 = 8的有效批大小 (Effective Batch Size),可以在不增加显存消耗的情况下,达到使用更大批次训练的稳定效果。lr_scheduler_type: cosine: 学习率调度策略。cosine指学习率会按照余弦曲线平滑下降,有助于模型在训练后期更好地收敛。
其他配置解释
trust_remote_code: true: 一个安全设置,对于像Qwen这样包含自定义代码的模型,必须设为true才能正确加载其独特的模型结构。preprocessing_num_workers/dataloader_num_workers: 分别是数据预处理和加载时使用的并行进程数,用于加速数据准备。warmup_ratio: 0.1: 预热比例。在总训练步数的的前10%里,学习率会从0线性增长到设定的1.0e-4,这有助于训练初期的稳定。bf16: true: 使用 BF16 混合精度进行训练,可以在支持的硬件上大幅提升训练速度并节省显存。eval_steps: 50: 每训练50步,就在验证集上进行一次评估。这可以帮助你密切监控模型是否出现过拟合。记录损失数据
SFT 训练
在LLaMA-Factory项目根目录下,通过以下命令启动训练。为保证长时间任务的稳定,推荐配合screen或tmux使用:
1
llamafactory-cli train train_config.yaml
通过观察日志,我们看到训练过程的关键信息。日志的起始部分揭示了本次训练任务的计算环境与核心并行策略
1
2
3
INFO 07-10 22:38:45 [__init__.py:239] Automatically detected platform cuda.
[INFO|2025-07-10 22:38:47] llamafactory.cli:143 >> Initializing 8 distributed tasks at: 127.0.0.1:44329
[INFO|2025-07-10 22:38:54] llamafactory.hparams.parser:383 >> Process rank: 0, world size: 8, device: cuda:0, distributed training: True, compute dtype: torch.bfloat16
- 分布式数据并行 (Distributed Data Parallel - DDP): 日志中的
world size: 8和distributed training: True明确指出,本次训练采用了8个GPU进行分布式数据并行。在此策略下,模型被完整复制到每个GPU上,而训练数据集被切分并分配给各个进程。各进程独立完成前向和后向传播后,通过All-Reduce操作同步梯度,从而实现训练加速。 - 混合精度训练 (Mixed-Precision Training):
compute dtype: torch.bfloat16表明训练采用了BF16(BFloat16)混合精度。该技术使用16位浮点数进行大部分计算,显著降低了显存占用并提升了在现代GPU(如NVIDIA Ampere及更新架构)上的计算吞吐量,同时保持了接近FP32的训练稳定性。
日志接着展示了对视觉语言模型(VLM)特有的数据处理流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[INFO|tokenization_utils_base.py:2058] 2025-07-10 22:38:54,229 >> loading file vocab.json ......
[INFO|image_processing_base.py:379] 2025-07-10 22:38:54,519 >> loading configuration file /data/modelscope/Qwen2___5-VL-7B-Instruct/preprocessor_config.json
[INFO|image_processing_base.py:434] 2025-07-10 22:38:54,521 >> Image processor Qwen2VLImageProcessor {...}
[INFO|processing_utils.py:876] 2025-07-10 22:38:55,269 >> Processor Qwen2_5_VLProcessor:....
- tokenizer: Qwen2TokenizerFast(name_or_path='/data/modelscope/Qwen2___5-VL-7B-Instruct', vocab_size=151643, model_max_length=131072, is_fast=True, padding_side='right', truncation_side='right'.....
[INFO|2025-07-10 22:38:55] llamafactory.data.loader:143 >> Loading dataset my_dataset.json...
Generating train split: 2950 examples [00:00, 43902.74 examples/s]
Converting format of dataset (num_proc=16): 100%|██████████| 2950/2950 [00:00<00:00, 15694.34 examples/s]
training example:
<|im_start|>system
你是一个视觉分类任务专家。请根据以下要求判断图片是否满足要求。<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>判断以上图片是否满足要求:
1. 只存在正方体、圆柱、立体圆环、五星徽章、台灯状立体,不能出现其他物体
2. 正方体与圆柱位于前方,横向排列,面积大于1m*1m
3. 五星徽章需放在立体圆环里面
4. 左上角水印,展示每个物体数量,需要和图片中物体对应
5. 左下角水印,展示台灯状立体在图片中的位置,需要和图片中物
6. 右上角水印,为正方体与圆柱的数量加和,需要和图片中物体对应
7. 右下角水印,为五星徽章和立体圆环的数量乘积,需要和图片中物体对应
请只输出如下格式:"满足要求", 或 "不满足要求"。不需要额外解释。请严格按照格式输出,否则判为无效答案。<|im_end|>
<|im_start|>assistant
满足要求<|im_end|>
[INFO|modeling_utils.py:1151] 2025-07-10 22:39:28,462 >> loading weights file /data/modelscope/Qwen2___5-VL-7B-Instruct/model.safetensors.index.json
Loading checkpoint shards: 100%|██████████| 5/5 [00:04<00:00, 1.16it/s]
- 视觉语言模型 (VLM) 数据流: 日志中同时加载了
tokenizer(文本分词器)和Image processor(图像处理器),证实了这是一个多模态任务。training example清晰地展示了图文混合输入的格式,其中文本部分被结构化为多轮对话,而图像则通过<|vision_start|><|image_pad|><|vision_end|>等特殊Token(Special Tokens)嵌入到文本序列中,实现了图文信息的统一表示。 - 模型分片加载:
Loading checkpoint shards: 100%|...| 5/5表明基础模型(8.3B参数)的权重被存储为5个分片文件(shards),这是存储和加载大规模模型的标准做法。
本日志的核心亮点在于展示了LoRA技术的应用,这是PEFT中最具代表性的方法之一。
1
2
3
4
5
6
[INFO|2025-07-10 22:39:32] llamafactory.model.adapter:143 >> Upcasting trainable params to float32.
[INFO|2025-07-10 22:39:32] llamafactory.model.adapter:143 >> Fine-tuning method: LoRA
[INFO|2025-07-10 22:39:32] llamafactory.model.model_utils.misc:143 >> Found linear modules: q_proj,k_proj,gate_proj,down_proj,v_proj,o_proj,up_proj
[INFO|2025-07-10 22:39:32] llamafactory.model.model_utils.visual:143 >> Set vision model not trainable: ['visual.patch_embed', 'visual.blocks'].
[INFO|2025-07-10 22:39:32] llamafactory.model.model_utils.visual:143 >> Set multi model projector not trainable: visual.merger.
[INFO|2025-07-10 22:39:33] llamafactory.model.loader:143 >> trainable params: 20,185,088 || all params: 8,312,351,744 || trainable%: 0.2428
- 低秩适配 (Low-Rank Adaptation - LoRA): 该方法的核心思想是冻结预训练模型的绝大部分参数,仅在模型的特定层(此处为Transformer中的
q_proj,k_proj,v_proj等线性层)旁注入小规模、可训练的低秩矩阵。 - 训练效率: 日志给出了决定性的数据:在总计超过83亿的参数中,仅有约2000万个参数被更新,可训练参数占比仅为0.24%。这极大地降低了微调所需的计算资源和时间。
- 模块冻结策略: 日志还显示,视觉编码器(
visual.blocks等)被设置为不可训练。这是一种常见的VLM微调策略,旨在保留强大的、经预训练获得的视觉特征提取能力,仅对语言模块和图文融合模块进行适配。
训练执行阶段的日志揭示了为克服显存限制而采用的优化技术。
1
2
3
4
5
6
7
8
9
[INFO|trainer.py:2409] 2025-07-10 22:39:34,131 >> ***** Running training *****
[INFO|trainer.py:2410] 2025-07-10 22:39:34,131 >> Num examples = 2,655
[INFO|trainer.py:2411] 2025-07-10 22:39:34,131 >> Num Epochs = 30
[INFO|trainer.py:2412] 2025-07-10 22:39:34,132 >> Instantaneous batch size per device = 1
[INFO|trainer.py:2415] 2025-07-10 22:39:34,132 >> Total train batch size (w. parallel, distributed & accumulation) = 64
[INFO|trainer.py:2416] 2025-07-10 22:39:34,132 >> Gradient Accumulation steps = 8
[INFO|trainer.py:2417] 2025-07-10 22:39:34,132 >> Total optimization steps = 1,230
[INFO|trainer.py:2418] 2025-07-10 22:39:34,135 >> Number of trainable parameters = 20,185,088
100%|██████████| 1230/1230 [2:08:35<00:00, 6.27s/it]
- 梯度累积 (Gradient Accumulation): 尽管单张GPU的批大小(
Instantaneous batch size per device)仅为1,但通过设置梯度累积步数为8,实现了8 (GPUs) * 1 (batch/GPU) * 8 (accumulation steps) = 64的有效批大小(Effective Batch Size)。该技术在多个mini-batch上计算并累加梯度,最后统一执行一次参数更新,从而在不增加显存消耗的前提下,模拟大批量训练的稳定化效果。
训练结束时,日志输出了关键的性能指标。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
***** train metrics *****
epoch = 29.2892
total_flos = 3173165210GF
train_loss = 0.0185
train_runtime = 2:08:35.51
train_samples_per_second = 10.323
train_steps_per_second = 0.159
***** eval metrics *****
epoch = 29.2892
eval_loss = 0.0914
eval_runtime = 0:00:18.17
eval_samples_per_second = 16.228
eval_steps_per_second = 2.035
- 模型收敛性: 训练集最终损失(
train_loss)为0.0185,这是一个极低的值,表明模型在训练数据上已充分收敛。 - 泛化能力: 验证集损失(
eval_loss)为0.0914。较高于train_loss,不过尚处于正常现象
训练后,默认在saves文件夹下,会保存训练的checkpoint,以及训练结果等文件。注意我们保存的只是 adapter 权重,并不包括大模型原本的权重(对于一个7B VLM,典型体积为14GB,对应的LoRA适配器通常为几十到几百MB),后续推理时需要同时加载原本大模型和我们训练的 adapter。
在tensorboard中,我们可以随时追踪训练参数,如下

右边三张展示了训练过程中的核心指标:
train/loss(训练损失): 该曲线表现出理想的收敛行为。损失值从一个较高的初始点(>0.1)开始,在前200步内迅速下降,随后持续平缓减小,最终在约400步后收敛至接近于零的水平。这表明模型具有足够强的拟合能力,能够完美地学习并记忆训练数据集。train/grad_norm(训练梯度范数): 梯度范数曲线与训练损失的变化高度相关。在训练初期,损失函数曲面陡峭,梯度范数出现数次剧烈峰值。随着训练损失收敛至平坦区域,梯度范数也迅速衰减并稳定在接近零的水平。这进一步证实了模型在训练集上已达到收敛,优化器不再需要进行大幅度的参数更新。train/learning_rate(学习率): 图中展示了标准的带预热(Warmup)的余弦退火(Cosine Annealing)学习率调度策略。学习率在初始阶段线性增长至峰值(1.0e-4),随后平滑衰减。该调度策略本身是当前主流且有效的,旨在帮助模型在训练初期稳定,在后期精细收敛。
评估模型泛化能力的关键在于验证集上的表现:
eval/loss(验证损失): 验证损失在训练开始后,随训练损失一同下降,并在约200-300步时达到其最小值(约0.06)。这一点是模型泛化能力的“最佳时刻”(Sweet Spot)。然而,在此之后,验证损失不再下降,反而开始持续、显著地上升,最终在训练结束时达到了比初始值更高的水平(>0.09)。出现了过拟合(Overfitting)现象。在验证准确率和其他指标的时候,可以考虑验证最后的checkpoint以及验证300step的checkpoint
推理和验证
我们可以使用 vllm 把我们训练的 adapter 和大模型权重加载在一块进行推理。主要分为两种方式
- 在 LLaMA-Factory 中提供的 web-ui 中手动问答
- 利用脚本自动批次获取大量结果
在有明确要求的业务场景数据集中,为了评估严谨,我们用脚本来获取结果。命令是:
1
2
3
4
5
6
7
8
CUDA_VISIBLE_DEVICES=4,5,6,7 python -u /data/LLaMA-Factory/scripts/vllm_infer.py \
--model_name_or_path /data/modelscope/Qwen2___5-VL-7B-Instruct \
--adapter_name_or_path /output/my_task \
--template qwen2_vl \
--dataset my_test \
--pipeline_parallel_size 1 \
--vllm_config '{"tensor_parallel_size": 4}' \
--save_name pred.json
命令比较简单,使用 LLaMA-Factory 提供的示例脚本 vllm_infer.py,利用4个GPU(tensor_parallel_size: 4)对测试集my_test进行推理。输出的文件 pred.json 中,每一行都是 json 格式的完整回答过程。
通过观察日志,我们可以看到推理过程中的关键信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
INFO 07-09 12:57:00 [__init__.py:239] Automatically detected platform cuda.
[INFO|tokenization_utils_base.py:2058] 2025-07-09 12:57:01,654 >> loading file vocab.json......
[INFO|tokenization_utils_base.py:2323] 2025-07-09 12:57:01,951 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|image_processing_base.py:379] 2025-07-09 12:57:01,952 >> loading configuration file /data/modelscope/Qwen2___5-VL-7B-Instruct/preprocessor_config.json
[INFO|image_processing_base.py:434] 2025-07-09 12:57:01,954 >> Image processor Qwen2VLImageProcessor {...
[INFO|processing_utils.py:876] 2025-07-09 12:57:02,670 >> Processor Qwen2_5_VLProcessor:...
tokenizer: Qwen2TokenizerFast(name_or_path='/root/linminmin/modelscope/Qwen2___5-VL-7B-Instruct', vocab_size=151643, model_max_length=131072...
[INFO|2025-07-09 12:57:02] llamafactory.data.loader:143 >> Loading dataset my_test...
training example:
<|im_start|>system
你是一个视觉分类任务专家。请根据以下要求判断图片是否满足要求。<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>判断以上图片是否满足要求:
1. 只存在正方体、圆柱、立体圆环、五星徽章、台灯状立体,不能出现其他物体
2. 正方体与圆柱位于前方,横向排列,面积大于1m*1m
3. 五星徽章需放在立体圆环里面
4. 左上角水印,展示每个物体数量,需要和图片中物体对应
5. 左下角水印,展示台灯状立体在图片中的位置,需要和图片中物
6. 右上角水印,为正方体与圆柱的数量加和,需要和图片中物体对应
7. 右下角水印,为五星徽章和立体圆环的数量乘积,需要和图片中物体对应
请只输出如下格式:"满足要求", 或 "不满足要求"。不需要额外解释。请严格按照格式输出,否则判为无效答案。<|im_end|>
<|im_start|>assistant
labels:
符合要求<|im_end|>
- 环境与组件加载:日志确认了CUDA环境,并成功加载了Qwen2.5-VL模型所需的
Tokenizer(文本分词器)和Image Processor(图像处理器)用于多模态任务。 - 数据格式验证:日志中的
training example展示了一个经过模板化处理的样本,其输入结构复杂,包含了多轮对话上下文以及<|vision_start|><|image_pad|><|vision_end|>等用于表征图像信息的特殊Token。与训练不同的是没有给出 assistant 的具体内容
下一个阶段展示了vLLM的启动过程
1
2
3
4
5
6
7
INFO 07-09 12:57:15 [config.py:1519] Defaulting to use mp for distributed inference
INFO 07-09 12:57:15 [llm_engine.py:241] Initializing a V0 LLM engine (v0.8.2) with config:...
[1;36m(VllmWorkerProcess pid=103728)[0;0m INFO 07-09 12:57:20 [multiproc_worker_utils.py:225] Worker ready; awaiting tasks
[1;36m(VllmWorkerProcess pid=103728)[0;0m INFO 07-09 12:57:21 [cuda.py:291] Using Flash Attention backend.
[1;36m(VllmWorkerProcess pid=103728)[0;0m INFO 07-09 12:57:22 [pynccl.py:69] vLLM is using nccl==2.21.5
INFO 07-09 12:57:22 [custom_all_reduce_utils.py:244] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3.json
INFO 07-09 12:57:22 [shm_broadcast.py:259] vLLM message queue communication handle: Handle(local_reader_ranks=[1, 2, 3], ...
mp指的是Python的多进程(multiprocessing)模块,用于进行单机多卡(Single-Node, Multi-GPU)的分布式推理Using Flash Attention backend表明引擎已启用Flash Attention,一种I/O感知的注意力算法,可显著降低显存占用并加速计算。同时,vLLM is using nccl表明底层的多GPU通信依赖于高性能的NVIDIA NCCL库。GPU P2P指的是GPU间的点对点通信(Peer-to-Peer Communication)。这是一种允许一个GPU直接读写同一台服务器上另一个GPU显存的技术。核心作用是极大地提升GPU之间数据交换的速度和效率。在张量并行(Tensor Parallelism)等需要频繁进行跨GPU数据同步的场景中(例如,All-Reduce操作),P2P通信至关重要。它避免了传统通信方式中数据需要先从GPU显存(VRAM)拷贝到CPU内存(RAM),再从CPU内存拷贝到目标GPU显存的低效路径。主要是通过NVIDIA的NVLink这种高速互联总线,或在较低速情况下通过PCIe总线。vLLM在首次启动时会检测系统中GPU之间的P2P拓扑关系(哪些GPU对之间可以进行P2P通信),并将这个结果缓存下来。后续启动时直接读取缓存,可以跳过耗时的检测过程,加快初始化速度。vLLM message queue communication基于消息队列在主进程和多个工人进程之间传递指令和数据
1
2
3
4
5
6
7
8
9
[1;36m(VllmWorkerProcess pid=103728)[0;0m INFO 07-09 12:57:22 [parallel_state.py:954] rank 1 in world size 4 is assigned as DP rank 0, PP rank 0, TP rank 1
INFO 07-09 12:57:22 [model_runner.py:1110] Starting to load model /data/modelscope/Qwen2___5-VL-7B-Instruct...
[1;36m(VllmWorkerProcess pid=103728)[0;0m INFO 07-09 12:57:22 [config.py:3243] cudagraph sizes specified by model runner...
Loading safetensors checkpoint shards: 100% Completed | 5/5 [00:00<00:00, 5.40it/s]
WARNING 07-09 12:57:23 [models.py:478] Regarding multimodal models, vLLM currently only supports adding LoRA to language model, visual.patch_embed.proj will be ignored.
[1;36m(VllmWorkerProcess pid=103728)[0;0m INFO 07-09 12:57:23 [punica_selector.py:18] Using PunicaWrapperGPU.
INFO 07-09 12:57:24 [model_runner.py:1146] Model loading took 4.0323 GB and 1.217729 seconds
world size(全局大小): 指参与本次分布式任务的总进程数,在深度学习中通常等同于总GPU数量。此日志中world size 4表明任务正在使用4个GPU。DP(Data Parallelism, 数据并行): 在每个GPU上保留一份完整的模型副本,并将输入数据的批次(Batch)切分给不同的GPU。这是最常见的并行方式,旨在提升训练和推理的吞吐量。DP rank 0表示所有4个GPU同属于一个数据并行组。PP(Pipeline Parallelism, 流水线并行): 将模型的不同层(Layers)分布在不同的GPU上,形成一个计算流水线。适用于模型巨大、单卡无法容纳其所有层的情况。PP rank 0表示没有启用流水线并行。TP(Tensor Parallelism, 张量并行): 将模型内部的巨大权重矩阵(如Transformer中的自注意力或MLP层)沿特定维度切分到不同的GPU上。各GPU协同完成一次矩阵运算。这是处理超大模型的关键技术。TP rank 1表示当前这个工人进程(rank 1)在张量并行维度上的索引是1。- 该日志明确指出,本次推理采用了纯张量并行策略,将一个模型分布在4个GPU上执行(
TP=4, DP=1, PP=1)后续可以看到,模型权重分配之后,每个GPU只需加载4GB左右 CUDA Graph是NVIDIA提供的一项性能优化技术,旨在减少重复计算任务中的CPU开销。原理: 在典型的GPU计算中,CPU需要不断地向GPU提交一个个独立的计算任务(Kernel Launch)。当任务流固定但需要大量重复执行时,这种CPU到GPU的提交开销会成为瓶颈。CUDA Graph允许我们将一整串的GPU操作捕获(Capture)成一个静态的计算图。之后,CPU只需发送一个“执行此图”的命令,GPU便能以极低的CPU开销连续执行整个操作序列。日志表示表示vLLM正在为一系列预设的输入序列长度(sizes)创建并缓存CUDA Graph。当后续遇到与这些长度匹配的推理请求时,vLLM可以直接调用对应的、预编译好的计算图,从而大幅提升执行效率,这对于提升LLM服务的吞吐量至关重要。- vLLM提示其当前的LoRA实现无法作用于视觉模块的某些特定层(
visual.patch_embed.proj)。 Punica是vLLM中用于高效服务多个LoRA适配器的专用计算内核。它能将使用不同LoRA适配器的请求智能地组合在一个批次中,并在GPU上高效地执行,避免了朴素实现中因权重切换带来的巨大开销。
1
2
3
4
5
INFO 07-09 12:57:45 [worker.py:267] Memory profiling takes 20.40 seconds
INFO 07-09 12:57:45 [worker.py:267] the current vLLM instance can use total_gpu_memory (79.33GiB) x gpu_memory_utilization (0.90) = 71.39GiB
INFO 07-09 12:57:45 [worker.py:267] model weights take 4.03GiB; non_torch_memory takes 1.39GiB; PyTorch activation peak memory takes 0.32GiB; the rest of the memory reserved for KV Cache is 65.65GiB.
INFO 07-09 12:57:45 [executor_base.py:111] # cuda blocks: 307335, # CPU blocks: 18724
INFO 07-09 12:57:45 [executor_base.py:116] Maximum concurrency for 3072 tokens per request: 1600.70x
KV Cache是 Key-Value Cache 的缩写,即“键值缓存”。核心作用是避免重复计算,从而极大地加速文本生成过程。- 在Transformer的自注意力机制中,为了生成下一个Token,模型需要计算当前Token与所有前面已生成Token之间的关系。这个计算依赖于每个Token的Key(K)和Value(V)向量。如果没有KV缓存,每生成一个新Token,都需要重新计算前面所有Token的K和V向量,这将带来巨大的计算浪费。
- KV缓存机制会将已经计算过的Token的K和V向量存储(缓存)在GPU显存中。在生成下一个新Token时,模型只需计算这个新Token的K、V向量,并将其追加到缓存中,然后利用全部缓存的K、V向量进行注意力计算即可。这使得每一步生成的计算复杂度从
O(n^2)降低到了O(n)。 - KV缓存的大小与
批处理大小 × 序列长度 × 模型隐藏层维度 × 层数成正比。对于长序列、大批量的推理任务,KV缓存所占用的显存甚至会超过模型权重本身。 cuda blocks和CPU blocks是vLLM独创的内存管理系统——PagedAttention——中的基本内存分配单元。PagedAttention借鉴了操作系统中虚拟内存和分页的思想,将GPU显存划分为许多个固定大小的、非连续的物理块(blocks)。cuda blocks: 307335: 指vLLM在预留的65.65GiB的GPU显存中,成功划分出了307,335个物理内存块。这些块将用于存储正在被GPU积极计算的请求的KV缓存。当一个请求到来时,vLLM会按需为其分配若干个不一定连续的block来存储其KV缓存数据。CPU blocks: 18724: 指vLLM在CPU主存(RAM)中预留的、用于交换(Swapping)的内存块池。当GPU显存占满时,vLLM可以将一些被挂起或优先级较低的请求的KV缓存从GPU块中“换出”到CPU块中。当该请求需要再次被处理时,再将其“换入”回GPU块。这个机制使得vLLM能够支持远超物理显存容量的并发请求数,极大地提升了系统的总吞吐量。- 在当前配置下,如果所有进入系统的请求其输入加输出的总长度恰好都是3072个Token,那么系统所拥有的KV缓存(65.65GiB)理论上最多可以同时支持约1600个这样的并发请求。即
总可用Token容量 / 单个请求所需Token容量 - 总可用Token容量: 等于
总CUDA块数 × 每个块能容纳的Token数。vLLM中每个block的大小是固定的(例如,可以容纳16个Token)。总容量 ≈ 307,335 blocks × 16 tokens/block ≈ 4,917,360 tokens - 单个请求所需Token容量: 日志中给出的场景是
3072 tokens per request。 - 计算并发数:
4,917,360 / 3072 ≈ 1600.70
1
2
3
4
5
6
7
Capturing CUDA graph shapes: 100%|██████████| 35/35 [00:25<00:00, 1.35it/s]
INFO 07-09 12:58:14 [custom_all_reduce.py:229] Registering 1995 cuda graph addresses
INFO 07-09 12:58:20 [model_runner.py:1570] Graph capturing finished in 32 secs, took 2.74 GiB
INFO 07-09 12:58:20 [llm_engine.py:447] init engine (profile, create kv cache, warmup model) took 55.88 seconds
Processed prompts: 100%|██████████| 380/380 [01:44<00:00, 3.63it/s, est. speed input: 6859.72 toks/s, output: 10.88 toks/s]
INFO 07-09 13:01:17 [multiproc_worker_utils.py:137] Terminating local vLLM worker processes
- 在CUDA Graph捕获中,“shape”可以理解为一种特定形态的推理请求批次,主要由批次内的请求数量和各个请求的序列长度等因素决定。日志中的
35/35表明vLLM正在为35种预设的、有代表性的“shape”进行计算图录制。其核心作用是最大程度地减少CPU到GPU的调度开销,从而提升推理速度和吞吐量。 - 在常规的GPU计算中,CPU需要逐一向GPU发出成千上万个独立的计算指令(Kernel Launch)。对于LLM推理这样计算模式相对固定的任务,这种重复的指令分发会成为性能瓶颈。 CUDA Graph技术允许将这一整串的GPU操作序列(从数据拷贝到矩阵运算再到通信)一次性地“录制”下来,形成一个静态的、完整的计算图。在实际推理时,当遇到与已录制“shape”相匹配的请求批次,CPU只需发送一个“执行XX号计算图”的单一指令,GPU即可在内部高效地完成整个复杂流程,极大地降低了CPU的负担和调度延迟。
- 多卡通信地址注册是CUDA Graph在多GPU张量并行(Tensor Parallelism)环境下正常工作的一个必要的底层步骤。它正在为GPU间的通信操作(如
All-Reduce)所涉及的内存地址进行“注册”。确保在静态的计算图中,多GPU之间的通信能够正确、高效地发生。 - 由于CUDA Graph是一个被“录制”好的静态流程,图中所有操作涉及的内存地址都必须是预先确定的。在张量并行中,一个计算步骤(如MLP层)的完成需要多个GPU交换各自的计算结果。这个
Registering ... addresses的过程,就是告诉CUDA运行时系统和通信库(NCCL):“当执行这些预录制好的计算图时,请在GPU-A的地址X和GPU-B的地址Y之间进行数据交换”。 日志中的1995代表了在所有35个被捕获的计算图中,需要为跨GPU通信而锁定的内存地址总数。这是确保vLLM的custom_all_reduce(自定义高效通信算子)能够在CUDA Graph模式下无误运行的关键。
后续可通过编写简单的Python脚本,解析输出文件并计算准确率(Precision)、召回率(Recall)等业务指标,从而对模型性能进行量化评估。
关于图像
在推理时,如果加入了图像,日志中可能会产生如下 warning
1
2
3
WARNING 07-09 12:57:25 [model_runner.py:1296] Computed max_num_seqs (min(256, 5120 // 278528)) to be less than 1. Setting it to the minimum value of 1.
[1;36m(VllmWorkerProcess pid=103737)[0;0m Token indices sequence length is longer than the specified maximum sequence length for this model (278528 > 131072). Running this sequence through the model will result in indexing errors
[1;36m(VllmWorkerProcess pid=103728)[0;0m WARNING 07-09 12:57:42 [profiling.py:222] The sequence length used for profiling (max_num_batched_tokens / max_num_seqs = 5120) is too short to hold the multi-modal embeddings in the worst case (278528 tokens in total, out of which {'image': 245760, 'video': 32768} are reserved for multi-modal embeddings). This may cause certain multi-modal inputs to fail during inference, even when the input text is short. To avoid this, you should increase `max_model_len`, reduce `max_num_seqs`, and/or reduce `mm_counts`.
- 来自数据集的某个样本,在经过预处理后,其最终的输入序列长度达到了 278,528个Token,而Qwen2.5-VL模型架构支持的最大序列长度(
max_position_embeddings)仅为 131,072个Token。 max_num_seqs指vLLM引擎估算其在当前硬件和配置下,能够同时处理(并发)的最大请求数量。这里解释一下 (min(256, 5120 // 278528))。5120: 这个值对应日志中的max_num_batched_tokens,代表vLLM在一个批次(batch)中能处理的最大Token总数。这是控制KV Cache显存占用的核心参数。- 表达式
5120 // 278528计算的是,在最大Token批次限制下,能容纳多少个“最坏情况”的请求。由于单个请求所需(278,528)远大于批次总容量(5,120),整数除法的结果为0。 256: 这是一个硬性上限,通常是vLLM配置中的默认最大并发数(engine_args.max_num_seqs),用以防止系统因处理过多并发请求而资源耗尽。min(256, 0)的结果是0。因为并发数不能小于1,vLLM发出警告并强制将其设为最小值1。这本身就是一个危险信号,表明单个请求的尺寸预估存在严重问题。{'image': 245760, 'video': 32768}解释了为什么输入序列可能会变得如此之长——因为视觉部分有潜力占据巨量的Token。The sequence length used for profiling是vLLM为进行性能优化(如捕获CUDA Graph)而选用的一个代表性的序列长度。它的计算方式是max_num_batched_tokens / max_num_seqs,即5120 / 1 = 5120。vLLM会假设后续请求的长度大致都在这个范围内,并据此优化计算图。警告表明用于性能优化的序列长度(5,120)与数据集中实际存在的“最坏情况”的序列长度(278,528)相差悬殊。因此,基于短序列的性能优化对于处理那个超长序列是无效的。
对于 qwen2.5 vl,通过技术报告可以得知,是将图像裁剪为 28x28 的小块并通过 vit 来变成一个 token,这样就可以自己计算图像所占的 token 数目了。
但是实际上不用担心,如果序列长度真的超过了模型所能处理的极限,会直接触发 Error 而停止,而不是 warning,此外,vllm 设置的最大上下文长度 max_model_len 是一个比较小的默认值(比如3072),而不是模型支持的真实的最大上下文长度,可以考虑传递额外参数给 vllm:
1
--vllm_config '{"tensor_parallel_size": 4, "limit_mm_per_prompt": {"image": 16}, "max_model_len": 8192}'
关于思维链
对于支持思维链的模型,可以在训练 yaml 配置中启用
1
enable_thinking: true
之后,我们在看到训练日志中为我们生成的样例会有些许不同,添加了<think>标签:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
training example:
<|im_start|>system
你是一个视觉分类任务专家。请根据以下要求判断图片是否满足要求。<|im_end|>
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>判断以上图片是否满足要求:
1. 只存在正方体、圆柱、立体圆环、五星徽章、台灯状立体,不能出现其他物体
2. 正方体与圆柱位于前方,横向排列,面积大于1m*1m
3. 五星徽章需放在立体圆环里面
4. 左上角水印,展示每个物体数量,需要和图片中物体对应
5. 左下角水印,展示台灯状立体在图片中的位置,需要和图片中物
6. 右上角水印,为正方体与圆柱的数量加和,需要和图片中物体对应
7. 右下角水印,为五星徽章和立体圆环的数量乘积,需要和图片中物体对应
请只输出如下格式:"满足要求", 或 "不满足要求"。不需要额外解释。请严格按照格式输出,否则判为无效答案。<|im_end|>
<|im_start|>assistant
labels:
<think>
</think>
符合要求<|im_end|>
当 enable_thinking: true 被激活,而数据样本中 assistant 的回答(即label)没有包含 <think>...</think> 标签时,Llama-factory 的数据处理器会自动注入一个空的思维链模板。
在训练过程中,模型学习的目标是预测这段包含空思维链的完整文本。损失函数会计算模型预测与这个完整label之间的差异。模型因此会学到两件事:
- 在生成最终答案前,必须先生成
<think>和</think>这对标签结构。 - 在标签结构之后,必须生成你在数据中提供的最终答案(如“符合要求”)。
由于思维链内部是空的,模型不会因为没有生成具体的思考内容而受到惩罚。它只是在学习一个输出格式:思考结构 + 最终答案。
推理时,模型首先按照微调学到的格式输出了 <think> 标签,触发了基础模型固有的推理能力来“自由发挥”、填充思考内容;然后,在思考结束后,它会根据LoRA微调学到的知识,给出一个更倾向于训练数据中标签的最终答案。
踩坑与修bug
对于带思维链的模型,我遇到的问题包括模型思考太长,vllm 推理的时候截断了。解决方法为推理参数加上 --max_new_tokens 2048。
训练时不用考虑思考太长的问题,因为不是自回归的过程。
第二个问题是模型思维链不断出现循环直至达到输出token上限。总结的原因包括:
- 信息不足:模型被要求做出一个绝对的、二元的判断(“符合要求”或“不符合要求”),但模型从图片中获取的信息可能不足以让它100%确定地完成某项检查。例如,模型反复纠结于“图片上是否只有给定物品”。这表明模型的视觉能力可以识别出一些物品,但它无法肯定地判断“图片中是否绝对没有其他任何物品”。由于无法做出斩钉截铁的判断,而指令又要求它必须这样做,模型陷入了一个困境:它知道需要检查这个条件,但又检查不出来,于是只能在“假设它满足”、“但是万一不满足呢”、“我再检查一遍”这个圈子里打转。
- 对于一个经过监督微调(SFT)的模型。在微调过程中,如果训练数据里充满了“检查A -> 检查B -> 检查C -> 总结”这样的标准流程,模型会很好地学会这个“思考格式”。但如果数据没有充分教会模型如何在信息不充分时打破僵局并得出一个“尽力而为”的结论,模型就可能只会呆板地重复它学过的思考步骤,一旦卡住就无法跳出。
- 低随机性 (Low Temperature):如果温度设置得很低,模型会倾向于选择概率最高的词元,这会加剧循环。一旦进入一个高概率的循环路径,就很难再跳出去。
- 缺少重复惩罚 (Lack of Repetition Penalty):这是专门用来解决重复问题的参数。如果没有设置或设置得太低,模型在重复生成相同或相似短语时不会受到任何“惩罚”,从而更容易陷入循环。
解决方法由简单到复杂如下,我使用方法一时直接见效了。
- 在命令中加入
--repetition_penalty参数,给一个大于1.0的值,比如1.1。这会降低模型重复生成相同词元的概率。即在原始logits上乘或除repetition_penalty,再进行采样来控制概率。 - 尝试加入
--temperature参数。稍高的温度会增加生成的多样性和随机性,有可能帮助模型“跳出”循环。可以从0.7(默认值可能更高)开始尝试,可以适当提高到0.8或0.9。但注意,过高的温度可能导致思考逻辑变得混乱。 - 优化提示工程:不要强迫模型做出它能力范围之外的绝对判断。修改 Prompt,让它基于现有证据得出结论。在思维链指令的最后,加一句“命令”,迫使它结束思考:“在分析完所有条件后,你必须停止思考并立即给出最终结论,不要重复检查。”
- 给模型提供1-2个完整的、高质量的“思考->结论”的“少样本”示例。在例子中,可以包含一个处理不确定性情况的范例。这能极大地规范模型的行为。
效果对比
对于同样的数据,有思维链与没有思维链的模型对比,表现如何?直接的结论是,在这个任务上,无思维链的模型起到了 baseline 的作用,从整体准确率看,思维链模型更好。但是在业务注重的指标上,思维链模型不一定更好,需要调整更多参数和prompt进行尝试
例如,在抓捕罪犯中,我们情愿多抓一点嫌疑人,也不愿漏掉一个,在这个场景中,业务注重的指标为阳性召回率。整体准确率高不一定代表阳性召回率高,特别是在不均衡的数据集中。
以下分析可能是错误的,仅供参考
这个业务数据集是不平衡的,负样本远比正样本少。在没有思维链约束的情况下,无思维链模型在LoRA微调时,其行为更像一个传统的分类器。面对不平衡数据,模型为了在训练集上最小化损失函数,找到了一个“捷径”:倾向于预测多数类(正样本)。LoRA有效地更新了与最终决策相关的权重,使模型学会了这种数据分布偏见。
而对于思维链模型,在微调后仍然会依照思考结果进行判断,而不是按照样本分布,因此效果不显著。这表明思维链模型本身在处理这类任务时,其内在逻辑或者说prompt引导就有问题。LoRA微调没能修复这个核心的逻辑问题,因此模型虽然经过了微调,但仍然“忠于”自己原有的、有缺陷的思考方式,最终导致微调效果不佳。或许需要从优化思维链的Prompt指令、构造更高质量的训练样本来“纠正”其思考过程
优化思路
在构建数据集中,本次实验没有给出<think>内部的具体内容。因为构造高质量、逻辑严密的思维链数据,成本极高。只提供最终答案的标注成本则低得多。另一方面,模型的最终目的只是为了得到一个准确的分类结果(如“符合”/“不符合”),这种方法将训练信号直接作用于最终答案,优化路径最短。
但是注意,由于 LLaMA-Factory 对于思考模型默认会加入空的思维链 <think>\n\n</think>\n\n 并在微调时计算损失,因此训出来的模型同样会缺乏思维链,ms-swift 框架可以在训练期间,指定 --loss_scale ignore_empty_think,以忽略对 <think>\n\n</think>\n\n 的损失计算,从而避免推理能力的丧失。但类似的参数暂未在 LLaMA-Factory 中找到。
事实上,对于高风险、要求高可靠性、或过程可解释性至关重要的任务,这是一种不推荐的行为。因为无法保证模型思考过程的质量,这会带来不可预知的风险。一个更优的“混合策略”可以是: 为一小部分(例如10%-20%)最典型或最困难的样本,手动编写高质量的思维链。对于其余大量的简单样本,则使用空的思维链。这样既能以较低的成本给模型的“思考方式”提供一些关键的引导和范例,又能利用大量数据来优化最终的决策准确率,达到成本和性能的平衡。
当然,也可以借助一个更强大的“教师模型”来做“推理过程蒸馏”(Reasoning Process Distillation),这需要一个流程来保证数据质量:
- 自动化规则过滤:例如,检查生成的思维链是否提及了所有关键检查点,长度是否在合理范围内等。
- 人工抽样审查(Human-in-the-Loop):定期抽取一部分生成的数据进行人工检查,确保“教师模型”没有出现系统性的错误。
- 迭代优化:先生成一小批数据,训练7B模型,评估效果。根据评估结果,回头去优化对“教师模型”的Prompt,然后再进行下一轮更大规模的数据生成。
部署
vllm 方式
vLLM 可以部署为实现 OpenAI API 协议的服务器。这使得 vLLM 可以作为使用 OpenAI API 的应用程序的即插即用替代品。以下命令默认在 https://:8000 启动服务器。
1
vllm serve /data/modelscope/Qwen2___5-VL-7B-Instruct
该服务器可以与 OpenAI API 相同的格式进行查询。例如,列出模型:
1
curl hhttp://localhost:8000/v1/models
1
2
3
4
5
6
7
{
"object": "list",
"data": [{
"id": "/data/modelscope/Qwen2___5-VL-7B-Instruct",
}]
}
// 删去了其他信息
然后我们可以使用 Chat Completions API
1
2
3
4
5
6
7
8
9
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/modelscope/Qwen2___5-VL-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'
或者使用 openai Python 包:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="/data/modelscope/Qwen2___5-VL-7B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)
对于部署带 LoRA 的模型,使用以下命令
1
2
3
vllm serve /data/modelscope/Qwen2___5-VL-7B-Instruct \
--enable-lora \
--lora-modules my-lora=/output/my_task/
当我们使用列出模型的 api ,可以看到已经部署上了 my-lora 模型
1
2
3
4
5
6
7
8
{
"object": "list",
"data": [
{"id": "/data/modelscope/Qwen2___5-VL-7B-Instruct",}
{"id": "my-lora",}
]
}
// 删去了其他信息
之后只需要在请求中把 model 换成 my-lora 就可以调用我们进行训练的模型
对于多模态的输入,请求修改为如下,更多参考包括:代码参考、文档参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image = encode_image(image_url_tiger)
chat_response = client.chat.completions.create(
model="microsoft/Phi-3.5-vision-instruct",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "What are the animals in these images?"},
{"type": "image_url", "image_url": {"url": image_url_duck}},
{"type": "image_url", "image_url": {"url": image_url_lion}},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}},
],
}],
)
LLaMA-Factory 方式
命令:
1
API_PORT=8000 llamafactory-cli api data/inference/qwen2_5vl.yaml infer_backend=vllm vllm_enforce_eager=true
随后,可以使用上方相同的命令来请求微调好的大模型
对齐 vllm_infer
事实上,使用如上简单的部署命令,往往会造成离线批量推理与线上请求API结果不一致的情况,问题出在我们使用的 vllm_infer.py 离线推理脚本拥有很多 LLaMA-Factory 后添加的参数,这些参数往往与 vllm 部署和请求的默认参数不同,当我们想要让线上推理与离线推理保持尽可能一致的效果的时候,需要考虑如下几个方面
vllm_infer.py 脚本的默认配置,转化为 vllm serve 命令后,需要添加如下参数
1
2
3
4
5
6
7
8
9
10
vllm serve /data/modelscope/Qwen2___5-VL-7B-Instruct \
--max-model-len 4096 \
--trust-remote-code \
--dtype auto \
--enable-lora \
--lora-modules my-lora=/output/my_task/ \
--tensor-parallel-size 1 \
--pipeline-parallel-size 1 \
--disable-log-stats \
--limit-mm-per-prompt '{"image": 8}'
tensor-parallel-size 可以设置大于1的数,以调用多个 GPU
对于带多张图片的复杂 prompt 请求,如下请求方式往往是错误的
1
2
3
4
5
6
7
8
9
10
11
12
messages=[
{"role": "system", "content": "你是一个视觉分类任务专家。请根据以下要求判断图片是否满足要求。"},
{
"role": "user",
"content": [
{"type": "text", "text": "判断以上图片是否满足要求:\n1. 只存在正方体、圆柱。。。。"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image[0]}"}},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image[1]}"}},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image[2]}"}},
],
},
],
这样会导致所有图像token集中在prompt末尾,而不是训练和离线批量推理的图文交错数据
正确方式是,对于数据集文件给定的带 <image> 占位符的 prompt 和图像列表,在处理为提供给模型的 message 时,需要在 <image> 占位符截断,处理为图文交错数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
messages=[
{"role": "system", "content": "你是一个视觉分类任务专家。请根据以下要求判断图片是否满足要求。"},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image[0]}"}},
{"type": "text", "text": "判断以上图片是否满足要求:\n1. 只存在正方体、圆柱。。。。"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image[1]}"}},
{"type": "text", "text": "还需要出现以下物品"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image[2]}"}},
{"type": "text", "text": "根据上述要求,判断。。。。。"},
],
},
],
最后,在将 message 交由模型处理时,需要带上vllm_infer.py 脚本的默认参数,更多参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
chat_response = client.chat.completions.create(
model="my-lora",
messages = [
{"role": "system", "content": "你是一个视觉分类任务专家。请根据以下要求判断图片是否满足要求。"},
{"role": "user", "content": interleaved_content},
],
extra_body={
'repetition_penalty': 1.0,
'temperature': 0.95,
'top_p': 0.7,
'top_k': 50,
'max_tokens': 1024,
"skip_special_tokens": True,
"stop_token_ids": [151645], # 从原始 vllm_infer.py 脚本获取
}
)
通过明确推理参数,我们的API请求效果将接近于原始的线下批量推理效果
强化学习
如果需要继续提升效果,一种可行的方案是在 SFT 的基础上继续进行强化学习,对于强化学习,LLaMA-Factory 支持 PPO、DPO、KTO 方案
介绍与数据集
KTO (Kahneman-Tversky Optimization)是一种非常新且高效的RLHF算法。它的巨大优势在于,它不需要成对的(好/坏)偏好数据。它只需要知道单次的模型输出是“好(desirable)”还是“坏(undesirable)”。数据例子为:
1
2
{"instruction": "请根据以下所有要求...", "input": "path/to/image1.jpg", "output": "符合要求", "label": true}
{"instruction": "请根据以下所有要求...", "input": "path/to/image2.jpg", "output": "符合要求", "label": false}
DPO (Direct Preference Optimization)是近年来替代PPO的主流方法。它绕过了独立的奖励模型,直接使用成对的偏好数据(一个“被选择”的回答 chosen 和一个“被拒绝”的回答 rejected)来优化模型。数据例子为:
1
2
{"instruction": "请根据以下所有要求...", "input": "path/to/image1.jpg", "chosen": "符合要求", "rejected": "不符合要求"}
{"instruction": "请根据以下所有要求...", "input": "path/to/image2.jpg", "chosen": "不符合要求", "rejected": "符合要求"}
PPO (Proximal Policy Optimization)是经典RLHF流程,第一阶段训练奖励模型(RM)需要和DPO一样成对的偏好数据(chosen / rejected)。这个模型的输入是(instruction, input, output),输出是一个标量分数。第二阶段PPO训练只需要原始的Prompt数据(instruction, input)模型会生成回答,奖励模型会给回答打分,然后根据分数更新模型参数。
具体而言,对于多模态的数据集,在这个任务上我们 DPO 数据集整理如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{"conversations": [
{
"from": "system",
"value": "你是一个视觉分类任务专家......."
},
{
"from": "human",
"value": "<image>判断以上图片是否满足要求......"
}
],
"chosen": {
"from": "gpt",
"value": "满足要求"
},
"rejected": {
"from": "gpt",
"value": "不满足要求"
},
"images": [
"/data/img_01.jpg"
]}
训练配置
使用的 yaml 配置文件中,与上面 SFT 阶段不同的配置包括
1
2
3
4
5
6
7
8
9
10
11
### model
adapter_name_or_path: /output/my_task
### method
stage: dpo
pref_beta: 0.1
pref_loss: sigmoid # choices: [sigmoid (dpo), orpo, simpo]
### train
learning_rate: 5.0e-6
num_train_epochs: 3.0
- 由于我们将SFT 微调后的模型作为 DPO 的起点,所以需要先加载前一阶段训练好的
adapter_name_or_path pref_loss为偏好损失函数(Preference Loss Function),sigmoid (dpo) 这是原始 DPO 论文中提出的标准损失函数。orpo, simpo 是近期提出的新算法,旨在改进 DPO。 ORPO 在 DPO 的基础上增加了一个常规的语言模型损失(next-token prediction),可以有效防止模型在进行偏好学习时“忘记”如何生成流畅、正确的语言。对于目标输出非常简短(只有几个词)的任务,ORPO 是一个非常值得尝试的选项,因为它可以帮助模型在专注于“判断”的同时,不损坏其通用的语言能力。pref_beta为正则化强度,高 Beta 值 (如 0.5, 1.0):意味着对偏离 SFT 模型的行为有很强的惩罚。训练会更稳定,但模型可能学得比较“胆小”,提升有限。 低 Beta 值 (如 0.01, 0.05):意味着模型有更大的自由度去探索和学习新的偏好,可能带来更大的性能提升,但也有可能“用力过猛”导致模型输出不稳定或能力退化。- 关于学习率,过高的学习率会轻易破坏掉 SFT 阶段学到的宝贵知识,导致“灾难性遗忘”。因此,一个更小的学习率(通常在 1e-6 到 8e-6 的范围内)是必要的。
先 SFT 再 DPO
关于先 SFT 再 DPO,考虑在于模型需要在 SFT 学习新知识,此外,也需要让模型按照我们期望的指定格式稳健输出后,再强化学习才是有效的,举个例子
- 标准答案:不满足要求
- SFT 训练后的回答:满足要求
- 未SFT训练的回答:我认为这个场景满足要求,如果你需要更多帮助,请告诉我!
如果在未SFT训练的模型上使用强化学习,相当于告诉模型:“对于‘我认为这个场景…请告诉我!’这一长串 token,请大幅降低它们的概率。” 但这是不清晰的指令,模型从这个梯度中学到的是什么?
- “不要说长句子,要说短句子。”
- “不要用‘我’、‘认为’、‘如果’、‘请’这些礼貌词汇。”
- “停止对话风格,切换到命令式、陈述性风格。”
更糟糕的是,对于数据集中的其他样本,原始模型可能生成其他五花八门的 rejected 回答,比如:
- “这张图片显示了一个货架,上面有多种商品…”
- “根据您的复杂规则,我需要更多时间进行分析…”
- “无法判断。”
DPO 会接收到各种各样混乱的“坏”例子。这种学习的效率比较差,如果我们已经让模型按照我们期望的指定格式稳健输出,这样学习的奖励更清晰,效率更高
读图与分析
训练相关图像如下:

train/grad_norm为梯度范数,即模型更新的幅度,在经历跨度较大的更新后收敛train/learning_rate学习率很好地体现了训练配置中的 warpup 阶段和cosine类型的 lr_scheduler- 训练损失前期平稳下降,后期有波动,最后收敛

train/logits/chosen指代被选择答案的 Logits。Logits 是模型在输出最终概率前的原始得分。logits/chosen 代表模型为“正确答案”(chosen response)给出的平均原始分数。DPO 的目标之一就是提升这个分数。训练初期,指标稳步上升,说明 DPO 正在起作用,模型在学习如何识别和偏爱正确的答案;但是后期开始波动并呈下降趋势,它表明模型在训练的后半段,反而对正确答案变得“不那么自信”了,是过拟合的一种表现train/logits/rejected为错误答案的 Logits,我们期望这个指标持续下降或保持在低位,但是从趋势看它与train/logits/chosen一致!这是一个不愿意看到的结果,我们的二分类回答没有很好地区分开来,这需要寻找细节原因(例如问题是否太难了)或者调整参数(学习率和loss计算方法)train/logps/chosen指代被选择答案的对数概率,对数概率是负数,越接近 0 代表概率越高。DPO 的目标是提升模型对正确答案的偏好,因此这个值理应上升(向 0 靠近)。经历了初始下降、剧烈波动并上升、以及收敛于零的三个阶段,展现了它一开始对正确答案的判断都出现了暂时的信心丧失,而后续又在训练集上过拟合了——它记住了所有训练样本train/logps/rejected指代被拒绝答案的对数概率,这个值理应下降(向负无穷靠近)可以看到它的趋势是正确且健康的,非常平滑、稳定、持续的下降
这样看,这次实验中 DPO 损失的降低一开始来源于 logps/rejected 的优化,尽管连带地损害了自己对正确答案的生成能力,导致对正确答案的信心也丧失了,总体上看 Loss 是降低的。后续经历了过拟合过程记住了所有样本

train/rewards/accuracies衡量在一个批次中,有多少样本的“正确答案” (chosen) 的对数概率高于“错误答案” (rejected) 的对数概率。它直接反映了模型区分好坏答案的能力。100% 的准确率意味着模型始终认为正确答案比错误答案更好。可以看到先是波动,然后过拟合train/rewards/chosen代表DPO 框架内部计算出的对“正确答案” (chosen) 的奖励分数。其计算公式约等于 \(\beta \times \log( P_\text{policy}(chosen) / P_\text{reference}(chosen) )\)。衡量相比于训练开始前的 SFT 模型,当前模型对正确答案的偏好提升了多少。理想情况下,这个值应该是正数,并且稳定或持续上升。可以看到先是波动,然后过拟合train/rewards/margins,Margin (边际) 是 DPO 优化的核心目标。它等于rewards/chosen和rewards/rejected之间的差值 (Margin = rewards/chosen - rewards/rejected)。DPO 的全部目的,就是要让这个 Margin 越大越好。整个训练过程中,它非常平滑、稳定、持续地增长,单看这个图,趋势是完全健康的。train/rewards/rejected代表对“错误答案” (rejected) 的奖励分数。理想情况下,这个值应该是负数,并且持续下降,表示模型越来越“讨厌”错误的答案。整个训练过程中,呈现出平滑、稳定、持续的下降,趋势本身是完全健康的
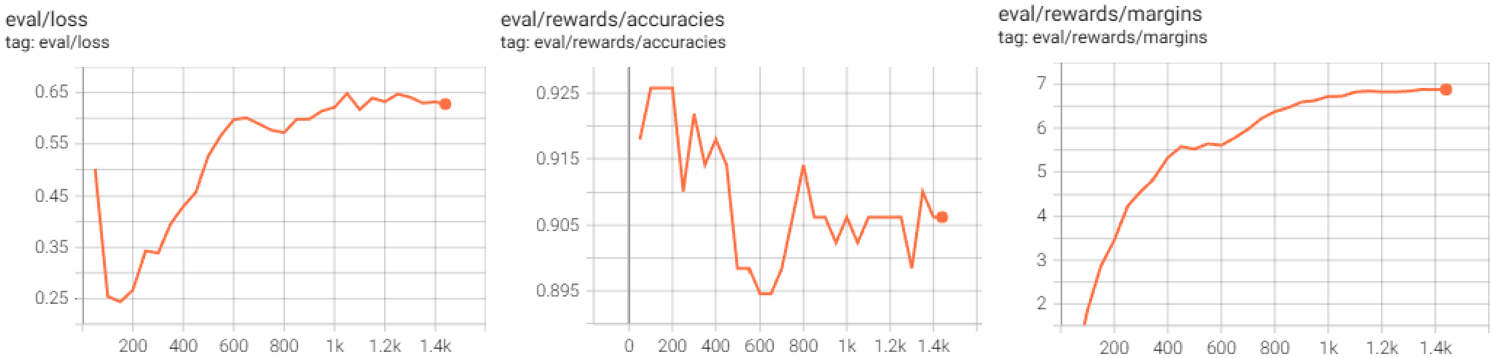
从验证集的趋势看,也能看出是先降低了错误答案的选择概率,随后过拟合
在训练完成之后,使用与 SFT 训练的模型相同的评估方式对测试集进行评估,在业务关心的指标上,DPO 确实提升了大约 5 个点左右
GRPO
如果想自定义奖励函数,可以尝试 GRPO 方案,例如基于 VLM-R1 框架进行视觉模型的 GRPO 训练,可以自定义奖励函数以及数据集,其论文的 finding 包括
- 在一些任务上,未训练的 3B 大模型性能不如专门的 grounding-dino 模型
- 直接使用 GRPO 训练比 SFT 的泛化性更好
VLM-R1 框架的示例任务为 Referring Expression Comprehension (REC),即给定图像和文字描述,需要大模型在图像中标出方框(输出坐标值),奖励分为两个部分,最终奖励为两个奖励的加和
- 格式奖励,如果满足
<think>......</think> <answer> ....(方框坐标).... </answer>的格式,reward 为 1,不满足为 0 - IoU 奖励,reward 范围 [0,1]
从复现的 reward 曲线来看比较稳定,作者取 500 step 的 checkpoint 就能达到较好效果,即使 loss 没有收敛

对于自定义数据集,在 VLM-R1 框架中我们使用的数据集格式为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
"id": 1,
"image": [
"/data/img_01.jpg"
],
"conversations": [
{
"from": "system",
"value": "你是一个视觉分类任务专家......."
},
{
"from": "human",
"value": "<image>判断以上图片是否满足要求......"
},
{
"from": "gpt",
"value": "满足要求"
},
],
}
需要注意的是,对于 VLM-R1 框架,训练和评估时会自动在 prompt 后加上:First output the thinking process in <think> </think> tags and then output the final answer in <answer> </answer> tags." 这个后添加的内容可以在 qwen_module.py的 get_question_template 函数中针对任务进行修改
对于自定义奖励函数,仿照示例任务,分为格式奖励和准确度奖励
- 格式奖励:如果满足
<think>.....</think> <answer> 满足要求 或者 不满足要求 </answer>的格式,reward 为1,不满足为0 - 准确度奖励:与 groundtruth 一致,reward 为1,不满足为0
对于一个正负样本均衡的数据集,如果模型只回答正确或者错误,期望的准确度奖励为 0.5,但是对一个高度不均衡的数据集,例如正样本比负样本为 9:1,如果模型只回答正确,期望准确度奖励也能达到 0.9,如果需要尽可能减少 FP 的数量,可以考虑将 FP 的 reweard 设置为一个大负数
关于奖励函数的具体实现,需要修改 qwen_module.py 文件,仿照 REC 示例任务新增两个reward函数,然后在同文件的 select_reward_func 函数中注册,在训练时,可以通过 log 文件判断 reward 函数是否处理正确