GLM:General Language Model Pretraining with Autoregressive Blank Infilling
在最近的一个项目中使用到了ChatGLM3-6B开源模型进行微调,在这里简要介绍一下 GLM 模型和 ChatGLM 用到的技术。
关于公司,智谱AI是由清华大学计算机系技术成果转化而来的公司,致力于打造新一代认知智能通用模型。公司合作研发了双语千亿级超大规模预训练模型GLM-130B,并构建了高精度通用知识图谱,形成数据与知识双轮驱动的认知引擎,基于此模型打造了ChatGLM(chatglm.cn)
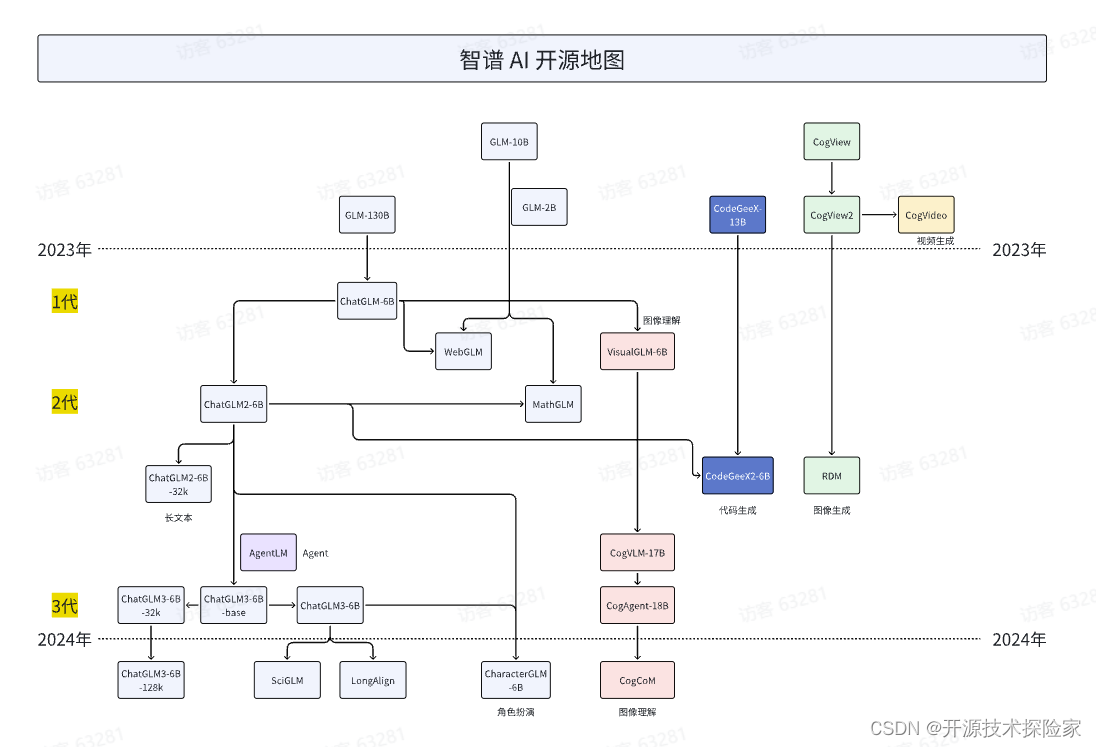
GLM背景
Transformer派生的主流预训练框架主要有三种:
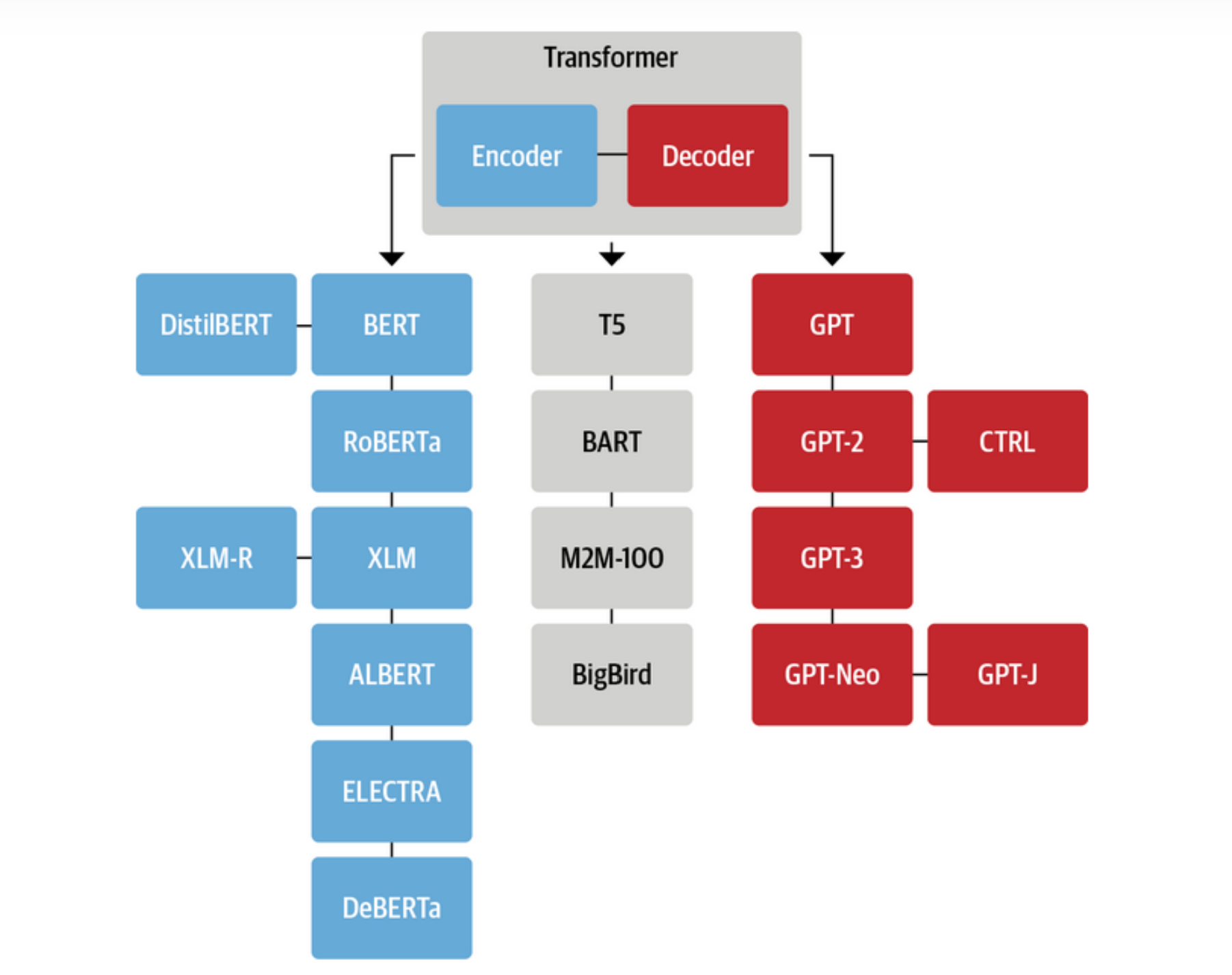
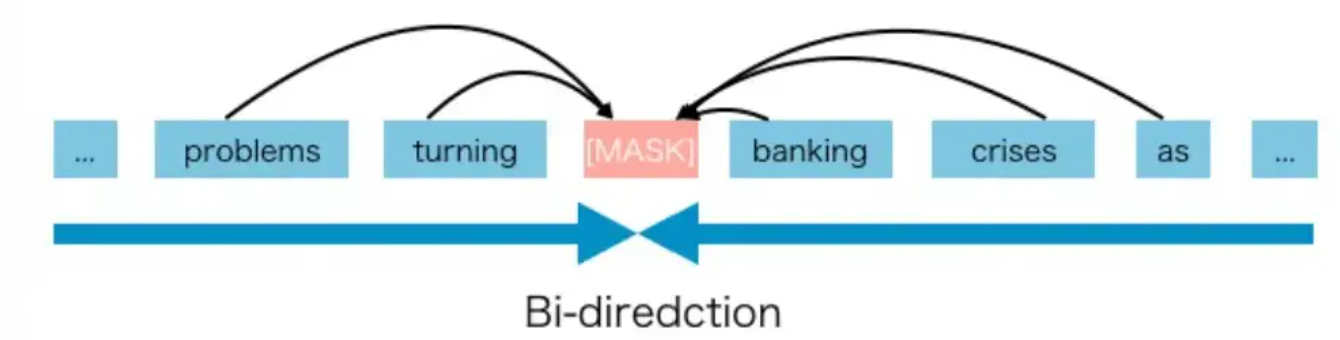
auto encoding自编码模型(AE模型):代表作BERT。它不会进行精确的估计,但却具有从被mask的输入中,重建原始数据的能力,即fill in the blanks(填空),并且是双向的。正因为这个无监督的填空预训练,所以叫自编码,编码就是常规理解,对输入做映射。编码器会产出适用于NLU任务的上下文表示,但无法直接用于文本生成。
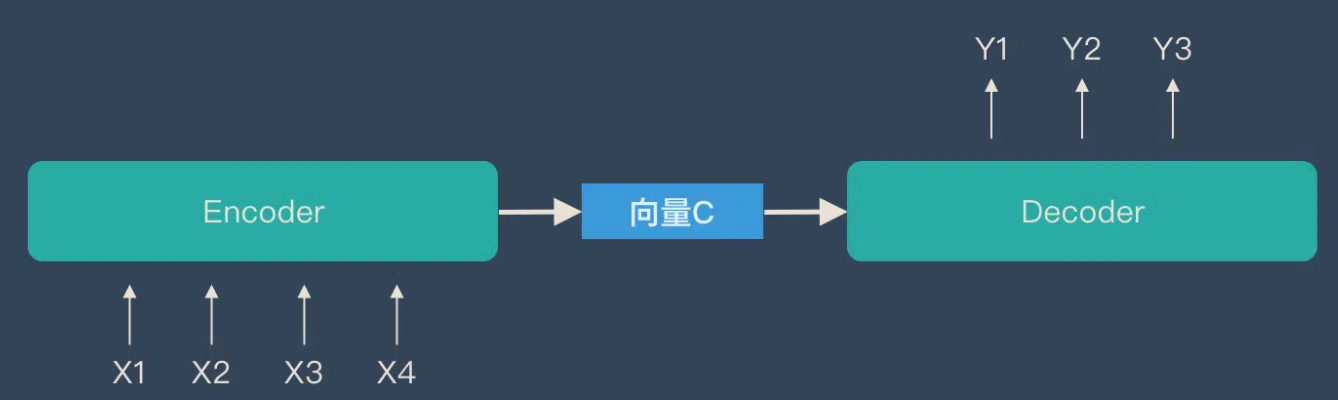
encoder-decoder(Seq2seq模型):同时使用编码器和解码器。它将每个task视作序列到序列的转换/生成(比如,文本到文本,文本到图像或者图像到文本的多模态任务)。对于文本分类任务来说,编码器将文本作为输入,解码器生成文本标签。代表作T5。采用双向注意力机制。Encoder-decoder模型通常用于需要内容理解和生成的任务,比如文本摘要、机器翻译等。
auto regressive自回归模型(AR模型):代表作GPT。本质上是一个从左往右学习的模型的语言模型。自回归使用自身以前的信息来预测当下时间的信息,即用自己预测自己,称之为自回归。通常用于生成式任务,在长文本生成方面取得了巨大的成功,比如自然语言生成(NLG)领域的任务:摘要、翻译或抽象问答。当扩展到十亿级别参数时,表现出了少样本学习能力。缺点是单向注意力机制,在NLU任务中,无法完全捕捉上下文的依赖关系。
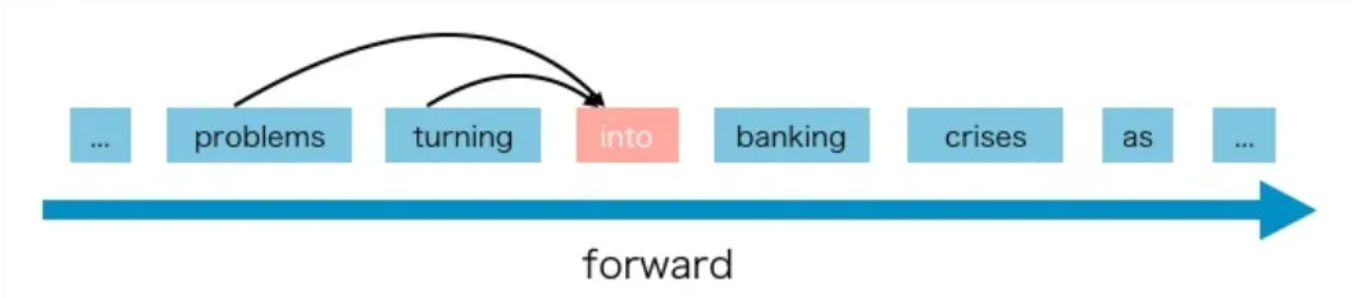
三种预训练框架各有利弊,没有一种框架在以下三种领域的表现最佳:自然语言理解(NLU)、无条件生成以及条件生成。T5曾经尝试使用MTL的方式统一上述框架,然而自编码和自回归目标天然存在差异,简单的融合自然无法继承各个框架的优点。 在这个天下三分的僵持局面下,GLM诞生了。
GLM模型基于auto regressive blank infilling(自回归空白填充)方法,结合了上述三种预训练模型的思想:
- 自编码思想:在输入文本中,随机删除连续的tokens。
- 自回归思想:顺序重建连续tokens。在使用自回归方式预测缺失tokens时,模型既可以访问corrupted文本,又可以访问之前已经被预测的spans。
- span shuffling + 二维位置编码技术。
- 通过改变缺失spans的数量和长度,自回归空格填充目标可以为条件生成以及无条件生成任务预训练语言模型。
自回归空白填充
我们可以把自回归空白填充理解为BERT的掩码语言模型,但是GLM掩码的不是一个单词或是一个实体,而是一个句子片段。这个句子片段的具体内容通过自回归的方式来预测。如下图所示。其中绿色的部分是被掩码的内容,它通过自回归的方式来预测被掩码的文本片段。
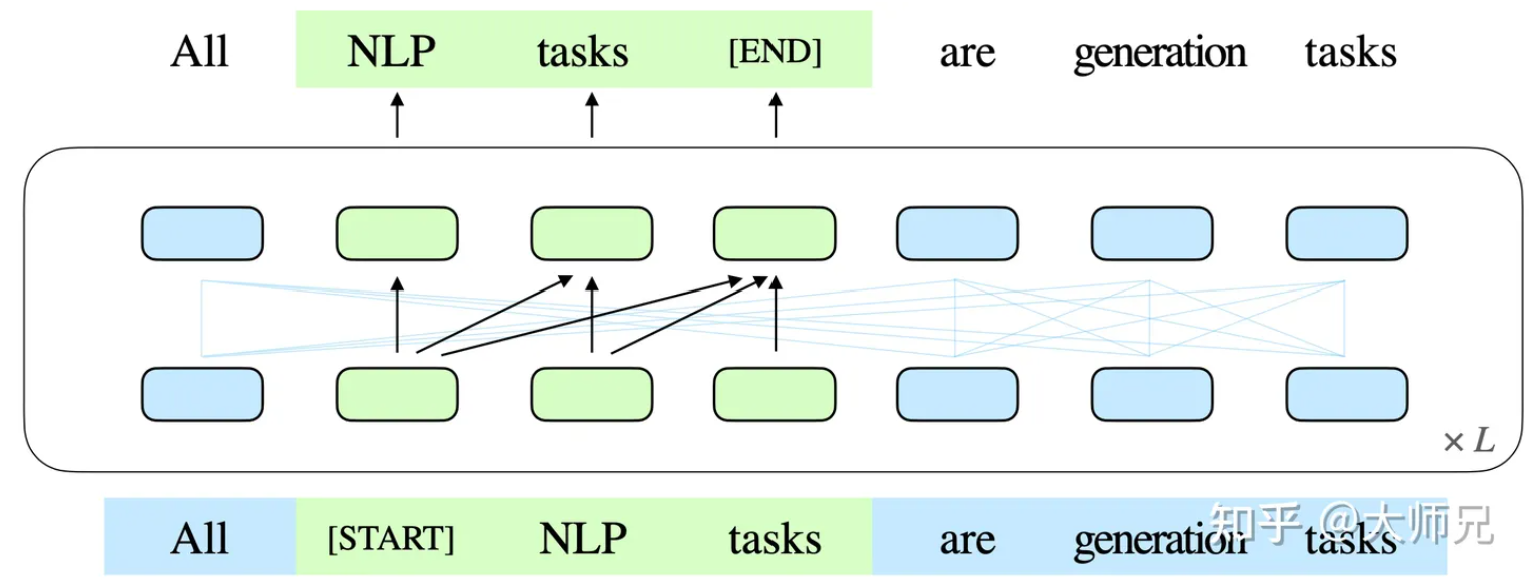
简单来说,这么做有几个好处:进行生成任务时,GLM可以看到上文的信息;GLM预测的Span的长度是不固定的;GLM是高效的。
在具体实现上,给定一个输入文本,从中采样多个长度不定的文本片段,每个文本片段由一组连续的单词组成。不同于BERT等模型每个[MASK]表示一个token,GLM的每个[MASK]表示的是每个文本片段,经过掩码的文本表示为 \(x_{\text{corrupt}}\) 。
为了充分捕捉不同片段之间的相互依赖关系,GLM使用了XLNet中提出的排列语言模型(Permutation Language Model,PLM)。PLM是将自回归语言模型和自编码语言模型融合的一个技巧,例如对于一个 1→2→3→4 的序列来说,假设我们要预测的序列是 3 ,我们需要同时看到 1,2,4 ,这样才能解决自回归语言模型的不能同时看到上下文的问题。所以PLM本质上是一个先进行打乱,再从左向右依次预测的自回归语言模型。
假设 \(Z_m\) 是 m 个文本片段的所有可能的排列组合,我们得到GLM的预训练目标函数:
\[\max _\theta \mathbb{E}_{z \sim Z_m}\left[\sum_{i=1}^m \log p_\theta\left(\boldsymbol{s}_{z_i} \mid \boldsymbol{x}_{\text {corrupt }}, \boldsymbol{s}_{z _{< i}}\right)\right]\]即在所有可能的排列组合中采样,已知之前的内容和当前片段掩码后的文本,要填空生成当前片段。优化参数 \(\theta\),使概率最大(符合真实的正确的分布)。换句话说,就是在最大化对数似然期望。
其中\(\boldsymbol{s}_{z _{< i}} = [\boldsymbol s_{z_1}, \cdots, \boldsymbol s_{z_{i-1}}]\)表示的是所有掩码片段 s 中第 i 个片段之前的内容。在GLM中,我们从左到右一次预测一个掩码片段的内容,因此片段 s 中第 j 个token \(s_j\) 的计算方式表示如下:
\[\begin{aligned} & p_\theta\left(\boldsymbol{s}_i \mid \boldsymbol{x}_{\mathrm{corrupt}}, \boldsymbol{s}_{z_{<i}}\right) \\ = & \prod_{j=1}^{l_i} p\left(s_{i, j} \mid \boldsymbol{x}_{\text {corrupt }}, \boldsymbol{s}_{z_{<i}}, \boldsymbol{s}_{i,<j}\right)\end{aligned}\]在实现自回归空白填充时,输入 x 被分成两部分,如下图(b),其中Part A是被破坏的文本 \(x_{\text{corrupt}}\) ,Part B是被掩码的文本片段。如下图(d)的自注意力掩码所示,Part A可以看到它本身的所有内容,但它看不到Part B中的任何内容。Part B可以看到Part A的所有内容,以及当前时间片之前的内容,但它不能看到当前时间片之后的内容。为了能够对文本片段进行自回归的生成,GLM在文本片段的首尾分别添加了[START]和[END]标志,分别用于输入和输出。在进行采样时,跨度的长度服从 \(\lambda=3\) 的泊松分布,我们持续采样文本片段,直到10%的文本标志被掩码掉。
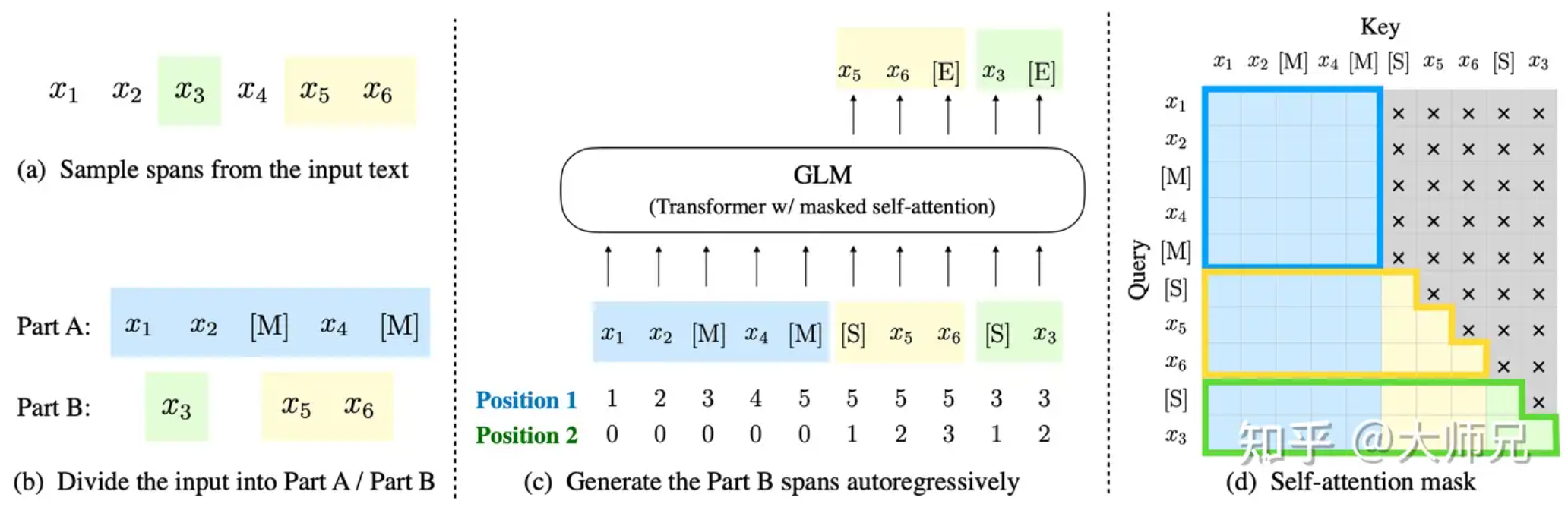
- 对于一个文本序列 x=[x1,⋯,x6] ,我们对其进行mask,假设mask掉的token是 [x3] 和 [x5,x6] ;
- 将 [x3] 和 [x5,x6] 替换为[M]标志,并且打乱Part B的顺序;
- 将Part A和打乱后的Part B拼接到一起,自回归的生成Part A和Part B,其中Part B中的每个文本片段加上起始标志[S]和终止标志[E],并且使用二维位置编码表示文本的位置关系;
- 使用自注意力掩码控制预测当前时间片时能看到的上下文。
二维位置编码
如上图(c)所示,GLM将Part A和Part B拼接到了一起。对于Part B中的一个token,他有两个位置信息,一个是它在原始文本中的位置,另外一个是它在文本片段中的位置。为了表示这个信息,GLM提出了二维位置编码。这个二维位置编码有片段间位置编码(intra-position encoding)和片段内位置编码(inner-position encoding)组成。
其中片段间位置编码表示的是替换该文本片段的[M]在Part A中的位置信息,与它在片段内的位置无关。因此 x3 的片段间位置编码的值是3,而 x5 和 x6 的片段间位置编码的值都是5。片段内位置编码指的是当前预测的标志在这个片段内的位置关系。因此[S], x5 和 x6 的片段内位置编码依次是1,2,3。而对于Part A中的token,它们的片段内位置编码的值都是0。
GLM这么做的原因是让模型在预测每个文本片段时,都可以不限制预测文本的长度,直到遇到[END]标志符或者到达最大预测长度才会停止。而在预测的过程中,之前的每个预测token都会有位置编码。
模型结构
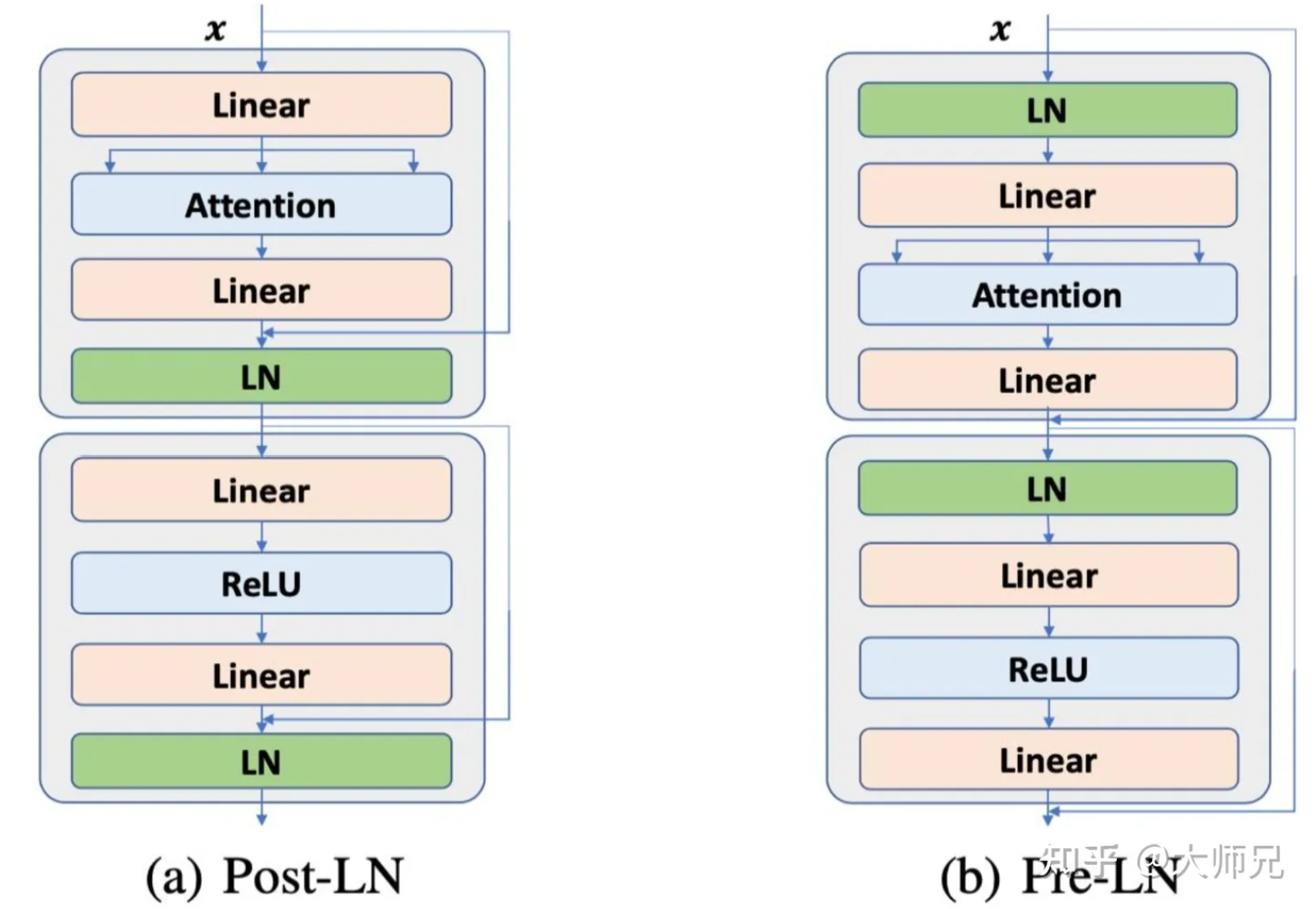
GLM使用了decoder-only的架构,首先将Part A输入模型并编码成特征向量,然后再依次预测Part B中每个片段的每个token。对比其他模型,GLM也对模型结构进行了调整,包括:
- 重新排列了LN和残差连接的顺序,具体来讲就是将Post-LN改成Pre-LN。
- 使用一个线性层来预测输出词;
- 将ReLU激活函数替换为GeLU激活函数。
训练和微调
GLM通过自回归空白填充的方式实现了三种预训练任务的统一,那么对于不同的训练语料,GLM通过不同的掩码方式,便可以实现用同一种方式实现多种不同任务的训练。参与GLM预训练的任务可以分为两类,非别是文档级别的任务和句子级别的任务。
- 文档级别:只采样一个文本片段,这个文本片段的长度是原始长度的50%到100%的均匀分布,这个任务旨在学习模型的长文本生成能力;
- 句子级别:这里掩码的文本片段必须是一个完整的句子,这里掩码的比例也是15%,这个任务旨在学习模型Seq-to-seq的能力。
而对于NLU任务来说,作者认为GLM中存在大量的空白填充任务,自然会让模型学到NLU的能力。
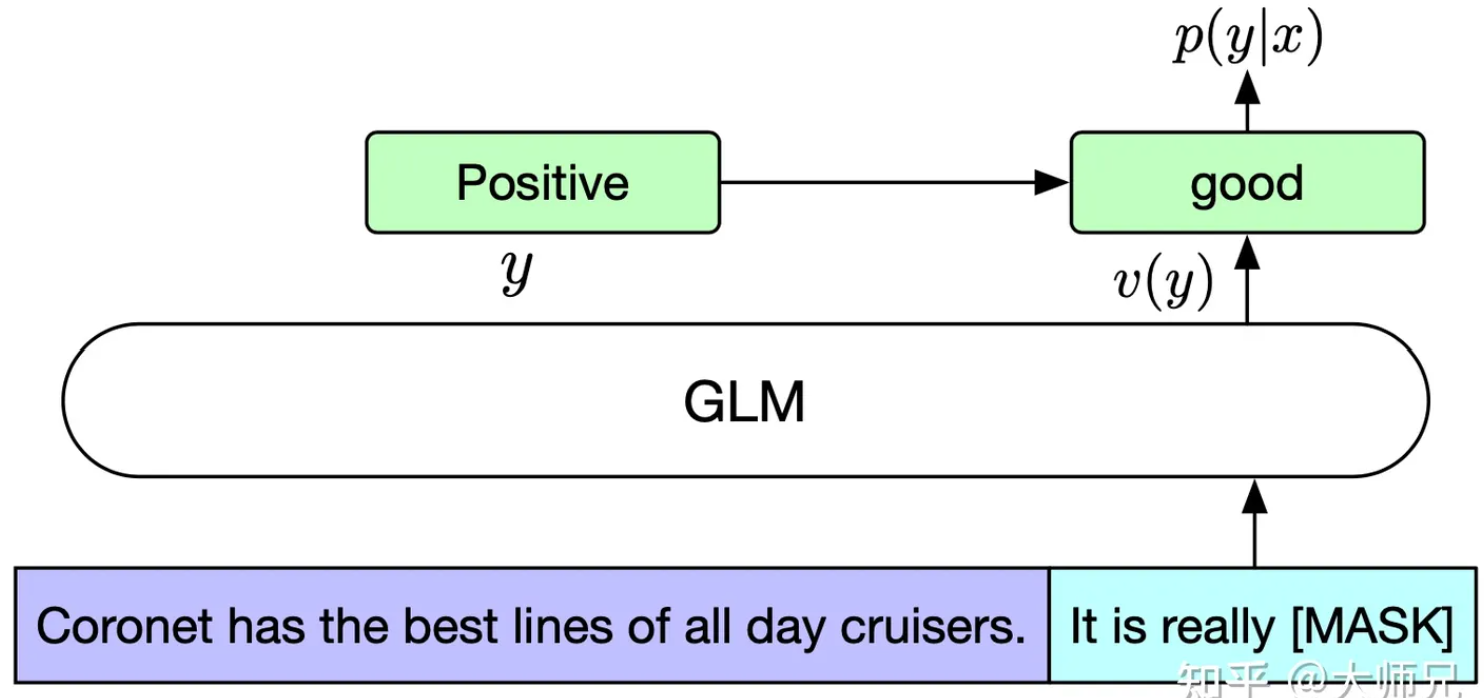
因为GLM并没有像BERT那样添加一个表示整句特征的[CLS]标志,他这里是将NLU的分类任务转化为填空生成任务。具体来讲,对于一个文本分类样本\((\boldsymbol x, y)\),我们将输入文本\(\boldsymbol x\)转化为单个token的预测任务。例如下图所示的情感分类任务,我们将标签y映射为填空题的答案,其中标签positive和negative对应的单词分别是good和bad。这里使用交叉熵来构造损失函数
ChatGLM-2
- 更长的上下文:基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。对于更长的上下文,发布了 ChatGLM2-6B-32K 模型。LongBench 的测评结果表明,在等量级的开源模型中,ChatGLM2-6B-32K 有着较为明显的竞争优势。
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
与ChatGLM的变化:
- 使用了RoPE替换二维位置编码。这也是GLM中提出的亮点设计之一。但是目前大部分主流的LLMs都在使用RoPE,所以大势所趋。当前版本仍然采用了最初的RoPE设计,事实上现在的RoPE经过了xPOS→线性内插→NTK-Aware Scaled RoPE→…若干次进化。
- Multi-Query Attention:这是一种共享机制的Attention,相比Multi-Head Attention,其Query部分没有区别,Key和Value可以只用一个Head。计算时,对Key和Value进行expand或者repeat操作,使它们填充到与Query一样的维度,后续计算就与Multi-Head Attention没区别。
- Attention Mask: V1的attention mask分了2部分,Part A和Part B,Part A部分是双向Attention(代码中的prefix_attention_mask),Part B部分是Causal Attention(原代码文件中的get_masks函数)。在V2版本,全部换成了Causal Attention,不再区分是Part A还是Part B,完全变成了decoder-only的架构。
- 多目标任务:Chat版本主要还是用的gMask生成式任务,但是在V1版本的代码还能看到mask、gMask等字样,V2已经摒弃了这些特殊token,原因与Attention Mask一致,均因为变成了decoder-only的架构,不再需要区分Part A和Part B。
ChatGLM-3
省流:ChatGLM2与ChatGLM3模型架构是完全一致的,ChatGLM与后继者结构不同。可见ChatGLM3相对于ChatGLM2没有模型架构上的改进。
相对于ChatGLM,ChatGLM2、ChatGLM3模型上的变化:
- 词表的大小从ChatGLM的150528缩小为65024 (一个直观的体验是ChatGLM2、3加载比ChatGLM快不少)
- 位置编码从每个GLMBlock一份提升为全局一份
- SelfAttention之后的前馈网络有不同。ChatGLM用GELU(Gaussian Error Linear Unit)做激活;ChatGLM用Swish-1做激活。而且ChatGLM2、3应该是修正了之前的一个bug,因为GLU(Gated Linear Unit)本质上一半的入参是用来做门控制的,不需要输出到下层,所以ChatGLM2、3看起来前后维度不一致(27392->13696)反而是正确的。
模型结构比较
ChatGLM的模型结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(word_embeddings): Embedding(150528, 4096)
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(attention): SelfAttention(
(rotary_emb): RotaryEmbedding()
(query_key_value): Linear(in_features=4096, out_features=12288, bias=True)
(dense): Linear(in_features=4096, out_features=4096, bias=True)
)
(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(mlp): GLU(
(dense_h_to_4h): Linear(in_features=4096, out_features=16384, bias=True)
(dense_4h_to_h): Linear(in_features=16384, out_features=4096, bias=True)
)
)
)
(final_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=4096, out_features=150528, bias=False)
)
ChatGLM2的模型结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_attention): CoreAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
)
)
ChatGLM3的模型结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_attention): CoreAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
)
)