VIGAN:Missing View Imputation with Generative Adversarial Networks
读论文时间!
多模态模型:VIGAN,官方代码
前置知识:AE、DAE、GAN、CycleGAN
一、简介
在如今许多领域中,数据由于来源的多样性。往往会造成某些数据缺失的问题,本文是利用自编码和生成对抗网络对缺失数据进行补全,主要处理的是多视角和多模态的缺失数据的问题,称为:解决缺失视角问题的生成对抗网络的填充方法。
二、所用的的一些方法
用到的有:
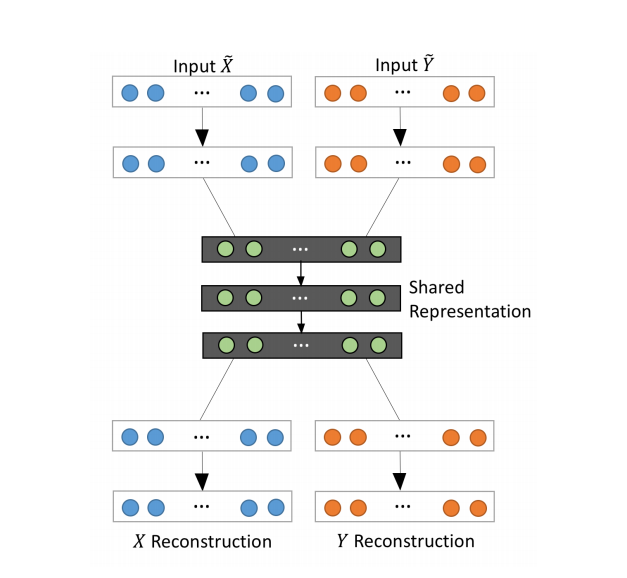
- 利用自编码器和去噪自编码器(DAE)去噪和补全数据。
- GANs用于领域映射可以使用不配对数据学习两个模态之间的关系。
DAE
一类接受损坏数据作为输入,并训练来预测原始未被损坏数据作为输入的自编码器。
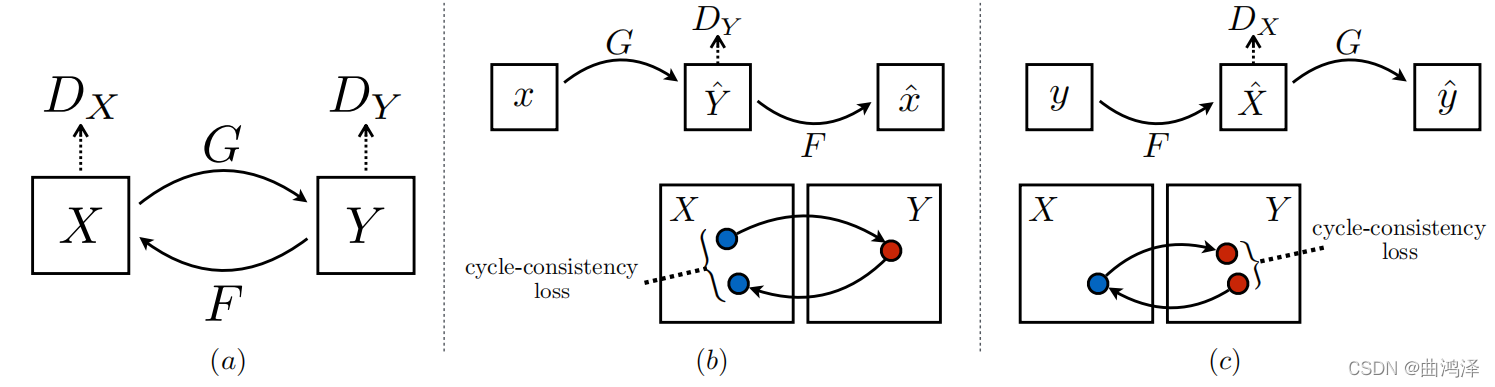
cycleGAN
简单来说就是将不同域之间的图像进行转换,而本身的形状保持不变如下图:

首先cyclegan的网络有两个鉴别器和两个生成器,这与之前学到的gan会有所不同。两个生成器的作用是:
- G_A2B:将真实马的图片变成相同状态的斑马图片(假的)或者将生成的假的马的图片变成斑马。
- G_B2A:将真实的斑马图片变成相同形状的马的图片(假的)或者将生成的斑马图片变成马。
- D_A:鉴别真实的马或者鉴别生成的马。
- D_B: 鉴别真实的斑马或者鉴别生成的斑马。
三、数据及符号简介
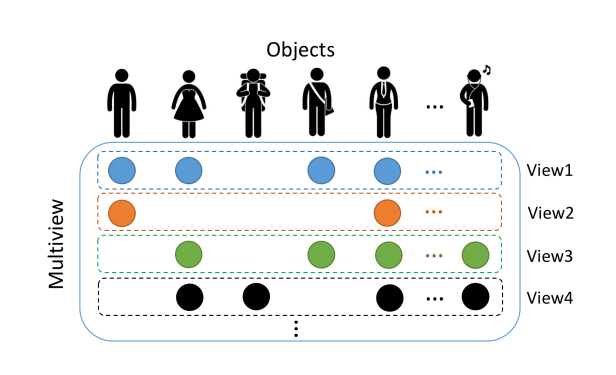
如上图所示,每种数据包含了不同视角,有view1,view2…….。其中每个视角中或多或少会有部分模块的缺失。
可以将数据分为多个视角,例如两种,一种为X,另一种为Y。(例如,对于抖音上的一段视频有两种视角:视频部分和文字部分)。
以上便是用到的缺失数据的全部内容。
四、模型分析
对数据的处理可以分为多个阶段:
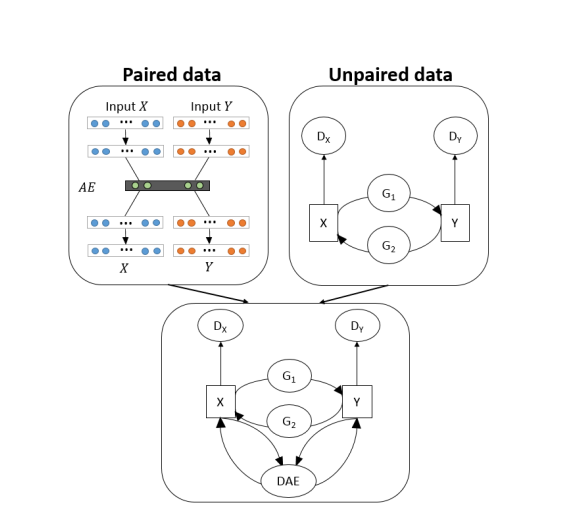
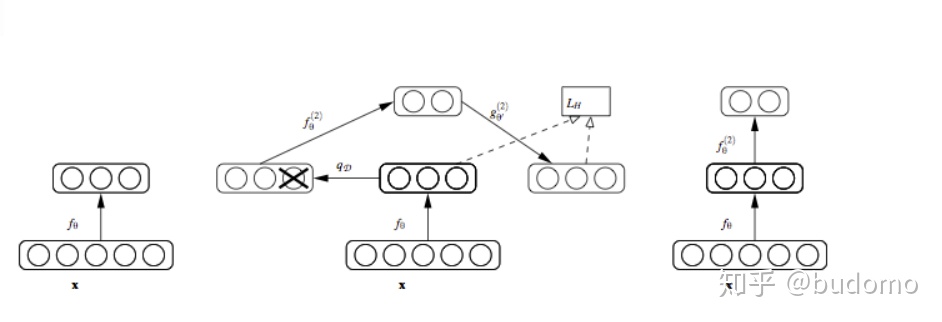
第一阶段
使用多模态自编码器在配对数据上进行训练,嵌入和重构输入视角。X和Y是数据的两种不同的视角。分别对这两个视角进行自编码再重构,以补全每个视角的缺失部分。
input X~和Y~是x和y的加噪版本,可以是(x,G1(x))或者(G2(y),y)。
使用DAE从配对数据中学习视角间对应关系,去噪自动编码器用于学习每个视角的共享和私有潜空间,以更好地重构缺失的视角,从而实现对GAN输出的去噪。
第二阶段
使用不配对数据训练一个循环一致的GAN,允许推断出跨领域的关系。由于x和y属于不同视角,实质上关系不大,因此需要训练一个具有跨领域转换能力的生成器。使用CycleGAN从非配对数据中学习跨域关系。
第三阶段
重新优化预训练的多模态自编码器和预训练的循环一致的GAN,以整合从不配对数据中学到的跨领域关系和从配对数据中学到的视角对应关系。
直观地说,循环一致的GAN模型学习将数据在两个视角之间进行转换,而转换后的数据可以看作是缺失值的初始估计,或者是实际数据的带噪版本。
第四阶段
使用自编码器通过去噪GAN的输出来细化估计值。