Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
读论文时间!
参考:
简述
Sentence-BERT比较适用于处理sentence级别的任务,如:获取一个句子的向量表示、计算文本语义相似度等。主要是基于BERT微调得到。
BERT和RoBERTa在文本语义相似度(Semantic Textual Similarity)等句子对的回归任务上,已经达到了SOTA的结果。但是,它们都需要把两个句子同时送入网络,这样会导致巨大的计算开销:从10000个句子中找出最相似的句子对,大概需要5000万($C_2^{10000}$=49,995,000)个推理计算,在V100GPU上耗时约65个小时。这种结构使得BERT不适合语义相似度搜索,同样也不适合无监督任务,例如聚类。
解决聚类和语义搜索的一种常见方法是将每个句子映射到一个向量空间,使得语义相似的句子很接近。通常获得句子向量的方法有两种:
- 用句子开头的[CLS]经过BERT的向量作为句子的语义信息(这种更常用)
- 用句子中的每个token经过BERT的向量,加和后取平均,作为句子的语义信息
BERT模型在输入序列的开头添加了一个特殊的标记[CLS],用于表示整个句子(或文本)的语义信息。
然而,UKP的研究员实验发现,在文本相似度(STS)任务上,使用上述两种方法得到的效果却并不好,即使是Glove向量也明显优于朴素的BERT句子embeddings。
Sentence-BERT(SBERT)的作者对预训练的BERT进行修改:使用Siamese and Triplet Network(孪生网络和三胞胎网络)生成具有语义的句子Embedding向量。
语义相近的句子,其Embedding向量距离就比较近,从而可以使用余弦相似度、曼哈顿距离、欧氏距离等找出语义相似的句子。SBERT在保证准确性的同时,可将上述提到BERT/RoBERTa的65小时降低到5秒(计算余弦相似度大概0.01秒)。这样SBERT可以完成某些新的特定任务,比如聚类、基于语义的信息检索等。
模型
基本得到模型结构很简单,如下,后面主要是讲如何训练模型。
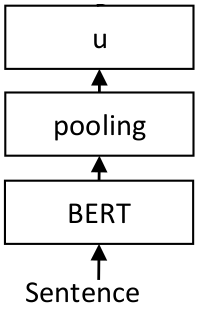
为了能够fine-tune BERT/RoBERTa,文章采用了孪生网络和三胞胎网络来更新参数,以达到生成的句子向量更具语义信息。该网络结构取决于具体的训练数据,文中实验了下面几种机构和目标函数。
简单来说,孪生网络就是共享参数的两个神经网络。三胞胎网络是共享参数的三个神经网络。
Classification Objective Function
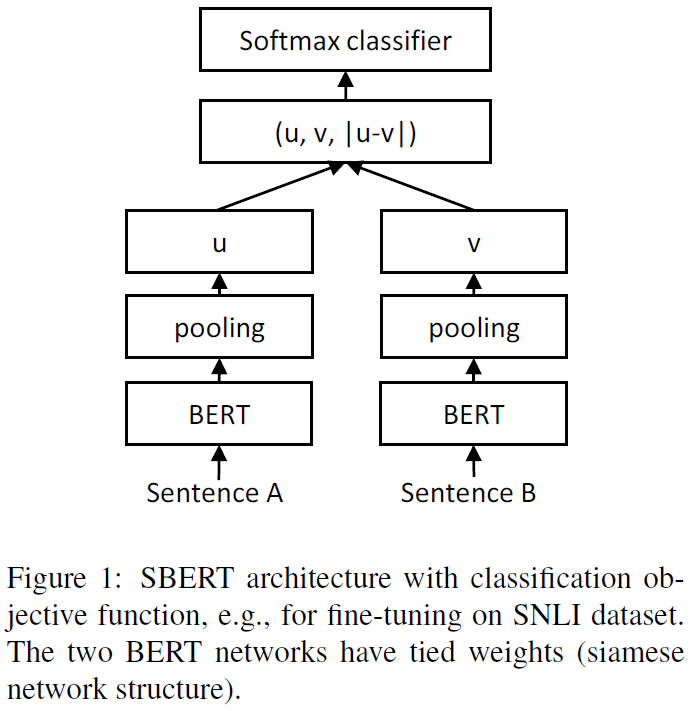
针对分类问题,作者将向量u,v,|u−v|三个向量拼接在一起,然后乘以一个权重参数 $W_t \in \R^{3n\times k}$,其中n表示向量的维度,k表示label的数量。
损失函数为CrossEntropyLoss
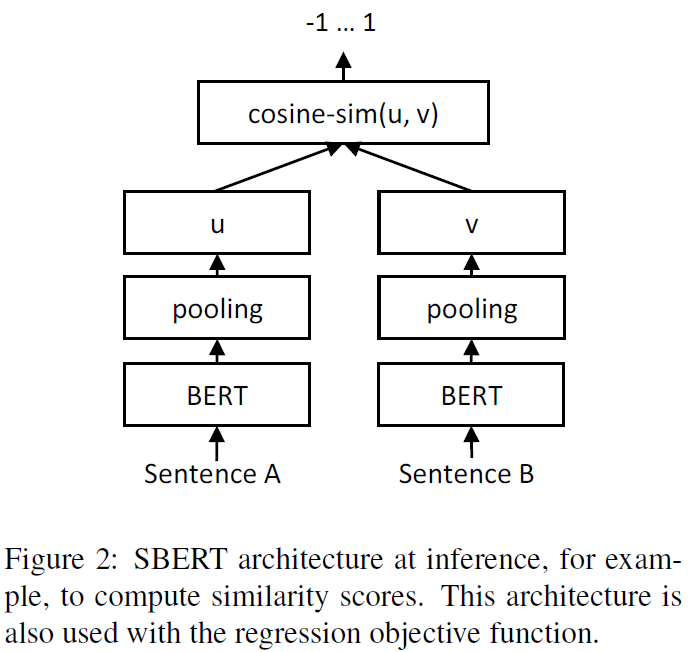
Regression Objective Function
两个句子embedding向量u,v的余弦相似度计算结构如下所示,损失函数为MAE(mean squared error)
Triplet Objective Function
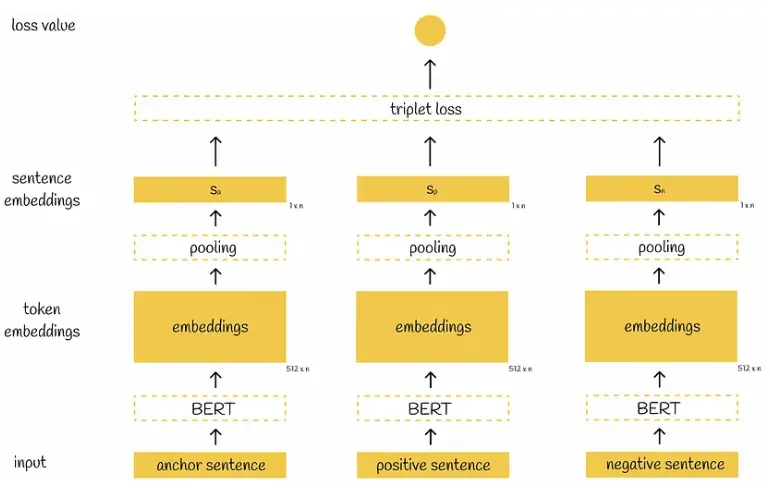
给定一个主句 a,一个正面句子 p 和一个负面句子 n,三元组损失调整网络,使得 a 和 p 之间的距离尽可能小,a 和 n 之间的距离尽可能大。数学上,我们期望最小化以下损失函数:
\[max(||s_a-s_p||-||s_a-s_n||+\epsilon,0)\]其中,$s_x$ 表示句子 x 的 embedding,||・|| 表示距离,边缘参数 $\epsilon$ 表示 sa 与 sp 的距离至少应比 sa 与 sn 的距离近 $\epsilon$ 。在实验中,使用欧式距离作为距离度量,$\epsilon$ 设置为 1
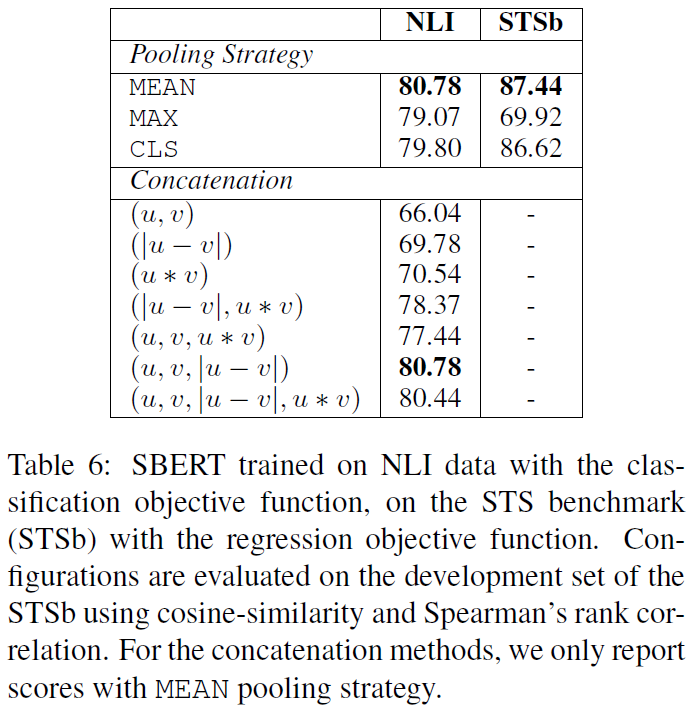
Pooling策略
SBERT在BERT/RoBERTa的输出结果上增加了一个Pooling操作,从而生成一个固定维度的句子Embedding。实验中采取了三种Pooling策略做对比:
- CLS:直接用CLS位置的输出向量作为整个句子向量
- MEAN:计算所有Token输出向量的平均值作为整个句子向量
- MAX:取出所有Token输出向量各个维度的最大值作为整个句子向量
MEAN的效果是最好的,所以后面实验默认采用的也是MEAN策略。
训练
作者训练时结合了 SNLI(Stanford Natural Language Inference)和 Multi-Genre NLI 两种数据集。SNLI 有 570,000 个人工标注的句子对,标签分别为矛盾,蕴含(eintailment),中立三种;MultiNLI 是 SNLI 的升级版,格式和标签都一样,有 430,000 个句子对,主要是一系列口语和书面语文本。
蕴含关系描述的是两个文本之间的推理关系,其中一个文本作为前提(Premise),另一个文本作为假设(Hypothesis),如果根据前提能够推理得出假设,那么就说前提蕴含假设。参考样例如下:
| Sentence A (Premise) | Sentence B (Hypothesis) | Label |
|---|---|---|
| A soccer game with multiple males playing. | Some men are playing a sport. | entailment |
| An older and younger man smiling. | Two men are smiling and laughing at the cats playing on the floor. | neutral |
| A man inspects the uniform of a figure in some East Asian country. | The man is sleeping. | contradiction |
实验时,作者使用类别为 3 的 Softmax 分类目标函数对 SBERT 进行 fine-tune,batch_size=16,Adam 优化器,learning_rate=2e-5
为了对 SBERT 的不同方面进行消融研究,以便更好地了解它们的相对重要性,我们在 SNLI 和 Multi-NLI 数据集上构建了分类模型,在 STS benchmark 数据集上构建了回归模型。在 pooling 策略上,对比了 MEAN、MAX、CLS 三种策略;在分类目标函数中,对比了不同的向量组合方式。结果如下
Python框架
Sentence Transformers是一个Python框架,用于句子、文本和图像Embedding。该框架计算超过100种语言的句子或文本嵌入,并可以比较这些嵌入(例如用余弦相似度比较,找到具有相似含义的句子),这对于语义文本相似、语义搜索或释义挖掘非常有用。同时,该框架基于Pytorch和Transformer,并提供了大量预训练的模型集合用于各种任务,也很容易基于此微调自己的模型。
直接使用预训练模型
1
2
3
4
5
6
7
8
9
10
11
12
from sentence_transformers import SentenceTransformer as SBert
model = SBert('roberta-large-nli-stsb-mean-tokens') # 模型大小1.31G
# 对句子进行编码
sentences1 = ['The cat sits outside']
sentences2 = ['The dog plays in the garden']
embeddings1 = model.encode(sentences1)
embeddings2 = model.encode(sentences2)
# 计算余弦相似度
from sentence_transformers.util import cos_sim
cosine_scores = cos_sim(embeddings1, embeddings2)
在自己的数据集上微调预训练模型
附上一个在语义文本相似度(中-韩句子对数据集)任务上微调的案例:Sentence-Transformer的使用及fine-tune教程
1)训练集构造:案例中的正样本就是中-韩配对的句子对(相似度label假设为1.0),负样本即随机打乱顺序的句子对(相似度label假设为0.0)。在fine-tune时,数据必须保存到list中(作者自定义的InputExample()对象)。InputExample()对象需要传两个参数texts和label,其中,texts也是个 list 类型,里面保存了一个句子对,label必须为 float 类型,表示这个句子对的相似程度。如:
1
2
3
4
train_examples = [
InputExample(texts=['My first sentence', 'My second sentence'], label=0.8),
InputExample(texts=['Another pair', 'Unrelated sentence'], label=0.3)
]
(2)验证集构造:不需要包装成InputExample()对象
1
2
3
4
5
6
7
from sentence_transformers import evaluation
sentences1 = ['터너를 이긴 푸들.'] # 全部为韩语的list
sentences2 = ['战胜特纳的泰迪。'] # 全部为中文的list
scores = [0.3] # 中韩一一对应的相似度
evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1, sentences2, scores)
(3)微调:如要在一个预训练模型的基础上进行微调,则先载入该预训练模型,再用 model.fit() 在自己的数据集上训练
1
2
3
4
5
6
7
8
9
10
11
12
13
from sentence_transformers import SentenceTransformer, SentencesDataset, InputExample, evaluation, losses
from torch.utils.data import DataLoader
# Define the model. Either from scratch of by loading a pre-trained model
model = SentenceTransformer('distiluse-base-multilingual-cased')
# Define your train dataset, the dataloader and the train loss
train_dataset = SentencesDataset(train_data, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=32)
train_loss = losses.CosineSimilarityLoss(model)
# Tune the model
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100, evaluator=evaluator, evaluation_steps=100, output_path='./Ko2CnModel')
- train_dataloader就是用Pytorch的 DataLoader() 函数将训练集分为一个一个batch
- train_loss用的是余弦相似度作为损失
- warmup_steps是因为微调需要warm up来适应新数据(个人感觉warm up在这里是用来调节学习率的,因为这里是从checkpoint开始训练,若一开始学习率就很大,容易跳出当前最优值所在区间)
- evaluation_steps即每隔多少步的训练才进行一次验证
- 自动将在验证集上表现最好的模型保存到output_path
(4)加载并使用微调好的模型:传入fine-tune好的模型目录即可
1
2
3
4
5
6
7
8
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('./Ko2CnModel')
# Sentences are encoded by calling model.encode()
emb1 = model.encode("터너를 이긴 푸들.")
emb2 = model.encode("战胜特纳的泰迪。")
cos_sim = util.pytorch_cos_sim(emb1, emb2)
更多fine-tune的内容可以参考官方文档:Training Overview