Learning Transferable Visual Models From Natural Language Supervision
读论文时间!
多模态模型:CLIP
参考:
- 论文网址:https://arxiv.org/abs/2103.00020
- 源码网址:https://github.com/OpenAI/CLIP
- 【论文&模型讲解】CLIP
- CLIP 模型解读
- 深度学习系列37:CLIP模型
介绍
SOTA计算机视觉系统被训练来预测一组固定的预定对象类别(例如 ImageNet 那样做 1000 个类)。CLIP 最大的贡献就是打破了之前固定种类标签的范式,直接搜集图片和文本的配对就行,然后去预测相似性。在收集数据、训练、推理时都更方便了,可以 zero-shot去做各种各样的分类任务,泛化能力也很强,甚至在一些领域比人类的 zero-shot 性能还好。
CLIP 在不使用 ImageNet 训练集的情况下,也就是不使用 ImageNet 中128万张图片中的任意一张进行训练的情况下,直接 zero-shot 推理,就能获得和之前有监督训练好的 ResNet50 取得同样的效果。
任务就是给定一些图片和一些句子,模型需要去判断哪一个句子(标题)与哪一个图像是配对的。使用的数据集是4亿个 图像-文本 对(数据集未开源,是效果好的关键之一),有了这么大的数据集之后就可以选择一种自监督的训练方式去预训练一个大模型出来了。
预训练之后,自然语言就被用来去引导视觉模型去做物体的分类(CLIP 用的是 prompt,下文有讲),分类也不局限于已经学过的视觉概念(即类别),也可以扩展到新的视觉概念,从而使预训练好的模型能够直接在下游任务上做 zero-shot 推理。
模型方面,作者在视觉方面尝试了8个模型,从 ResNet 到 ViT,其中最小的模型和最大的模型的计算量相差了大概100倍。作者发现迁移学习的效果跟模型的大小基本上成正相关。
zero-shot效果好,backbone 参数冻住训练最后一层的分类头去做分类任务效果也好。
模型
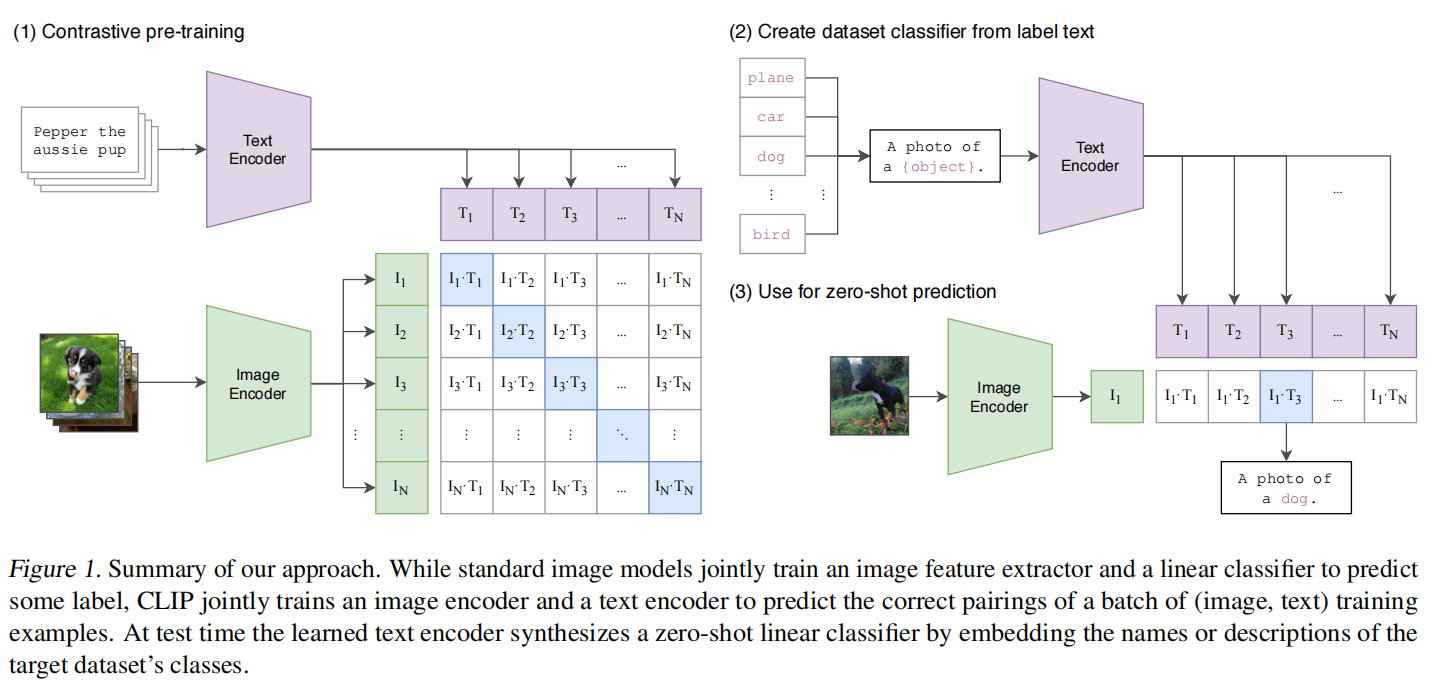
Contrastive pre-training
模型的输入是若干个 图像-文本 对儿(如图最上面的数据中图像是一个小狗,文本是 ”Pepper the aussie pup”)。
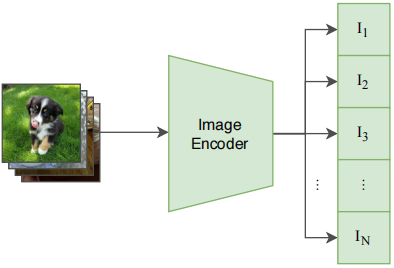
图像部分:图像通过一个 Image Encoder 得到一些特征,这个 encoder 既可以是 ResNet,也可以是 Vision Transformer。假设每个 training_batch 都有 N 个 图像-文本 对儿,那么就会得到 N 个图像的特征。
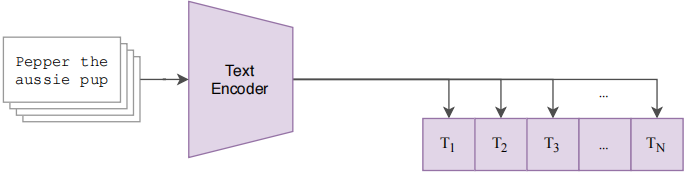
文本部分:文本通过一个 Text Encoder 得到一些文本的特征。同样假设每个 training batch 都有 N 个 图像-文本 对儿,那么就会得到N 个文本的特征。
CLIP 就是在以上这些特征上去做对比学习,对比学习非常灵活,只需要正样本和负样本的定义,其它都是正常套路。
这里配对的 图像-文本 对儿就是正样本(即下图中对角线蓝色部分)的图像和文本所描述的是同一个东西,那么矩阵中剩下的所有不是对角线上的元素(图中白色部分)就是负样本了。
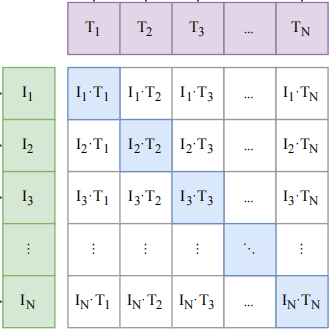
因此,有 N 个正样本, $N^2-N$ 个负样本。有了正、负样本后,模型就可以通过对比学习的方式去训练,不需要任何手工的标注。对于这种无监督的预训练方式,如对比学习,是需要大量数据的,OpenAI专门去收集了这么一个数据集,其中有4亿个 图像-文本 对儿,且数据清理的比较好,质量比较高,这也是CLIP如此强大的主要原因之一。
1
2
3
4
5
用图像编码器把图像编码成向量 a;
用文本编码器把文本编码成向量 b;
计算 a·b,
如果 a 和 b 来自一对儿配对的图和文字,则让 a·b 向 1 靠近;
如果 a 和 b 来自不配对儿的图和文字,则让 a·b 向 0 靠近;
Create dataset classifier from label text
CLIP 经过预训练后只能得到视觉上和文本上的特征,并没有在任何分类的任务上去做继续的训练或微调,所以它没有分类头,那么 CLIP 是如何做推理的呢?
作者提出 prompt template:以 ImageNet 为例,CLIP 先把 ImageNet 这1000个类变成一个句子,也就是将这些类别去替代 “A photo of a {object}” 中的 “{object}” ,以 “plane” 类为例,它就变成”A photo of a plane”,那么 ImageNet 里的1000个类别就都在这里生成了1000个句子,然后通过先前预训练好的 Text Encoder 就会得到1000个文本的特征。
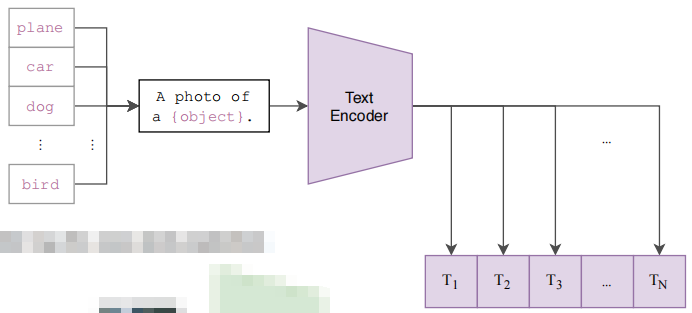
其实如果直接用单词(“plane”, “car”, “dog”, …, “brid”)直接去抽取文本特征也是可以的,但是因为在模型预训练时,与图像对应的都是句子,如果在推理的时候,把所有的文本都变成了单词,那这样就跟训练时看到的文本不太一样了,所以效果就会有所下降。此外,在推理时如何将单词变成句子也是有讲究的,作者也提出了 prompt engineering 和 prompt ensemble,而且不需要重新训练模型。
快速上手:
1
pip install openai-clip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import clip
import torch
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("plane.jpg")).unsqueeze(0).to(device)
text = clip.tokenize(["plane", "dog", "cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("label probs:", probs)
输出:
1
label probs: [[9.9986637e-01 1.2676469e-04 6.8195259e-06]]
Use for zero-shot prediction
在推理时,无论来了任何一张图片,只要把这张图片扔给 Image Encoder,得到图像特征。之后就拿这个图片特征去跟所有的文本特征去做 cosine similarity(余弦相似度)计算相似度,来看这张图片与哪个文本最相似,就把这个文本特征所对应的句子挑出来,从而完成这个分类任务。
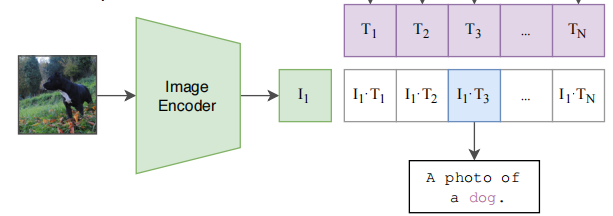
在实际应用中,这个类别的标签也是可以改的,不必非得是 ImageNet 中的1000个类,可以换成任何的单词;这个图片也不需要是 ImageNet 的图片,也可以是任何的图片,依旧可以通过算相似度来判断这图中含有哪些物体。即使这个类别标签是没有经过训练的,只要图片中有某个物体也是有很大概率判断出来的,这就是 zero-shot。但如果像之前的那些方法,严格按照1000个类去训练分类头,那么模型就只能判断出这1000个类,这1000个类之外的所有内容都将判断不出来。
CLIP 彻底摆脱了 categorical label 的限制,无论在训练时,还是在推理时,都不需要有这么一个提前定好的标签列表,任意给出一张图片,都可以通过给模型不同的文本句子,从而知道这张图片里有没有我想要的物体。CLIP 把视觉的语义和文字的语义联系到了一起,学到的特征语义性非常强,迁移的效果也非常好。
实验
数据集
现有工作主要使用了三个数据集,MS-COCO、Visual Genome 和 YFCC100M。
虽然 MS-COCO 和 Visual Genome 的标注,但是数据量太少了,每个都有大约10万张训练照片。 相比之下,其他计算机视觉系统是在多达35亿张 Instagram 图片上训练的。
拥有1亿张照片的 YFCC100M 是一个可能的替代方案,但标注质量比较差,每个图像配对的文本信息都是自动生成的,许多图片使用自动生成的文件名,如 20160716113957.jpg 作为 “标题” 或包含相机曝光设置的 “说明”(反正就是和图片的信息是不匹配的)。 如果对 YFCC100M 进行清洗,只保留带有自然语言标题或英文描述的图像,数据集缩小了6倍,大概只有1500万张照片, 这个规模就与与ImageNet的大小大致相同。
CLIP 使用的数据集是 OpenAI 新收集的一个数据集,称为 WIT(WebImageText)。
预训练
首先作者尝试了一个跟 VirTex 的工作非常相似的方法,即图像这边使用卷积神经网络,然后文本方面用 Transformer,都是从头开始训练的,任务就是给定一张图片,要去预测这张图片所对应的文本,即caption。
本文主要是与 Learning Visual N-Grams from Web Data (2017年)的工作比较相似,他们都做了 zero-shot 的迁移学习,但当时 Transformer 还未提出,也没有大规模的且质量较好的数据集,因此17年的这篇论文的效果并不是很好。
作者发现如果把训练任务变成对比的任务,也就是说只需要判断这个图片和这个文本是不是配对的,那么这个任务就简单了很多,约束一下就放宽了很多。仅仅把预测型的目标函数换成对比型的目标函数,训练效率一下就提高了4倍。
为什么使用对比学习?
如果给定一张图片,然后去预测它对应的文本的话,需要逐字逐句地去预测这个文本,那么这个任务就太难了,因为对于一张图片来说,可以有很多不同的描述,文本之间的差距将是非常巨大的。如果用这种预测型的任务去预训练模型的话,它就会有太多的可能性了,那么这个模型训练的就非常慢。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n,h,w,c] - minibatch of aligned images
# T[n,l] - minibatch of aligned texts
# W_i[d_i,d_e] - learned proj of image to embed
# W_t[d_t,d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f image_encoder(I) #[n,d_i]
T_f text_encoder(T) #[n,d_t]
# joint multimodal embedding [n,d_e]
I_e = l2_normalize(np.dot(I_f,W_i),axis=1)
T_e = l2_normalize(np.dot(T_f,W_t),axis=1)
# scaled pairwise cosine similarities [n,n]
logits = np.dot(I_e,T_e.T)*np.exp(t)
# symmetric loss function
labels np.arange(n)
loss_i=cross_entropy_loss(logits,labels,axis=0)
loss_t cross_entropy_loss(logits,labels,axis=1)
loss=(loss_i+loss_t)/2
上面是伪代码:
- 图像和文本的输入分别通过 Image Encoder 和 Text Encoder 得到图像和文本的特征,其中 Image Encoder 可以是 ResNet 或 Vision Transformer,Text Encoder 可以是 CBOW 或 Text Transformer。
- 得到特征后还有一个投射层,用来学习如何从单模态变成多模态,然后再做 L2 归一化,就得到了用来对比学习的特征。
- 接下来就计算 cosine similarity,算得的相似度也就是用来做分类的 logits
- 计算交叉熵损失,最后求平均就得到了loss。
在训练 CLIP 时,Image Encoder 和 Text Encoder 都不需要提前进行预训练的。最后做投射时,并没有用非线性的投射层(non-linear projection),而是使用线性的投射层(linear projection)。对于以往的对比学习(如SimCLR,MOCO)用非线性的投射层会比用线性的投射层带来将近10个点的性能提升,但作者说在多模态的预训练过程中线性与非线性差别不大,他们认为非线性的投射层应该只是用来适配纯图片的单模态学习。
因为 CLIP 模型太大了,数据集也太大了,训练起来太耗时,所以不太好做调参的工作,所以在算对比学习的目标函数时,将 temperature 设置为可学习的 log-parametized 乘法标量(以往的对比学习中 temperature 是个非常重要的超参数,稍微调整就会使最后的性能发生很大的改变),temperature 在模型训练时被优化了,而不需要当成一个超参数再去调参。
视觉模型选择
在视觉方面,作者一共训练了 8 个模型,5 个 ResNets 和 3 个 Vision Transformers:
- 对于 ResNets,作者训练一个Resnet50、一个ResNet101,然后再训练三个Resnet50:它们根据EfficientNet的方式,把模型里的 channel 宽度、模型深度和模型大小做了调整,得到了三个 ResNet 的变体,即RN50x4、RN50x16 和 RN50x64,计算量分别是 ResNet 的 4、16、64 倍。
- 对于 Vision Transformers,作者尝试了 ViT-B/32,ViT-B/16 和 ViT-L/14(其中 32、16、14都是 patch 的大小)。
对于所有的模型,都训练 32 epochs,且使用 Adam优化器。对于所有超参数,作者简单的做了一些 Grid Search,Random Search 和手动调整,为了调参快一些,都是基于其中最小的 ResNet50 去做的且只训练 1 epoch,对于更大的模型作者就没有进行调参了。
训练时作者使用的 batch size 为 32768,很显然模型训练是在很多机器上起做分布式训练。同时也用到了混精度训练,不仅能加速训练,而且能省内存。此外作者也做了很多其他省内存的工作。
对于最大的 ResNet 来说,即上文中的RN50x64, 在 592 个 V100 的GPU上训练了18天;而对于最大的 ViT 来说,在 256 个 V100 GPU 上训练只花了 12 天。证实了训练一个 ViT 是要比训练一个 ResNet 更高效的。因为 ViT-L/14 的效果最好,作者又拿与训练好的 ViT-L/14 再在数据集上 fine-tune 了 1 epoch,而且用了更大的图片(336×336),这种在更大尺寸上 fine-tune 从而获得性能提升的思路来自于 Fixing the train-test resolution discrepancy,最后这个模型就称为 ViT-L/14@336px。如无特殊指明,本文中所有 “CLIP” 结果都使用了我们发现效果最好的这个模型(ViT-L/14@336px)。
zero-shot 迁移
Visual N-grams 首次以上述方式研究了 zero-shot 向现有图像分类数据集的迁移。作者做了与之前最相似的工作 Visual N-grams 的对比,Visual N-grams 在 ImageNet 的效果只有 11.5% 的准确率,而 CLIP 能达到 76.2%。
CLIP 在完全没有用任何一张那128万张训练图片的情况下,直接 zero-shot 迁移就与原始的 ResNet50 上做 linear probe(linear probe:把预训练好的模型中的参数冻结,只从里面去提取特征,然后只训练最后一层即 FC 分类头层) 打成平手。
但一些难的数据集,如 DTD(对纹理进行分类),CLEVRCounts(对图片中物体计数),对于 CLIP 就很难,而且很抽象,先前训练时也没有这种相关标签,所以 CLIP 在这些数据集上表现得不好。对于这种特别难的任务如果只做 zero-shot 不太合理,更适合去做 few-shot 的迁移,对于这种需要特定领域知识的任务(如肿瘤分类等)即是对于人类来说没有先验知识也是很难。
BiT(Big Transfer)主要为迁移学习量身定做,是 few-shot 迁移学习表现最好的工作之一。而 zero-shot CLIP 直接就和最好的 BiT 持平。随着训练样本的增多, few-shot CLIP 的效果是最好的,不仅超越了之前的方法,也超越了 zero-shot CLIP。
Prompt Engineering and Ensembling
prompt 主要是在做 fine-tune 或做推理时的一种方法,而不是在预训练阶段,所以不需要那么多的计算资源,并且效果也很好。prompt 指的是 提示,即文本的引导作用。
为什么需要做 Prompt Engineering and Prompt Ensembling?
- polysemy(一词多义):如果在做文本和图片匹配的时候,每次只用标签对应的那 一个单词 去做文本上的特征抽取,那么很容易遇到这种问题。例如在 ImageNet 中,同时包含两个类,一类是 “construction crane”,一类是 “crane”,在相应的语境下这两个 “crane” 的意义是不一样的,在建筑工地的环境下指的是“起重机”,作为动物又指的是“鹤”,这时就有歧义性。当然别的数据集也有这种问题,如 Oxford-IIIT Pet,有一类叫 boxer,这里指的是狗的一种类别,但对于文本编码器来说它就可能翻译成“拳击手”,那这样提取特征就是不对的。总之,如果只是单独一个单词去做 prompt,那么很容易出现歧义性的问题。
- 做预训练时,匹配的文本一般都是一个句子,很少是一个单词。如果推理时传进来的是一个单词的话,很容易出现 distribution gap,提取的特征可能不是很好。
基于以上两种问题作者提出了 prompt template(提示模板),“A photo of a { label }”。首先所有的标签都变成了一个句子,就不容易出现 distribution gap。而且 label 也一般都是名词,也能减少歧义性的问题。使用 prompt template 后准确率提升了 1.3%。
Prompt Engineering 不只给出这么一个提示模板,作者发现如果提前知道一些信息,这样对 zero-shot 的推理是很有帮助的。假如现在做的事 Oxford-IIIT Pet 这个数据集,这里面的类别一定是宠物,那么提示模板可以变为 “A photo of a { label }, a type of pet.”,把解空间缩小了很多,很容易得到正确的答案。当对于 OCR(文字识别)数据集来说,如果在想找的文本上添加双引号,那么模型也是更容易找到答案。
Prompt Ensembling:使用多个提示模版,做多次推理,最后再把结果结合起来,一般都会取得更好的结果。在源码 CLIP/notebooks/Prompt_Engineering_for_ImageNet.ipynb 文件中,这里提供了 80 种提示模板,以便适用于不同的图片。
1
2
3
4
5
6
7
8
9
10
11
12
imagenet_templates = [
'a bad photo of a {}.',
'a photo of many {}.',
'a sculpture of a {}.',
'a photo of the hard to see {}.',
'a low resolution photo of the {}.',
'a rendering of a {}.',
'graffiti of a {}.',
'a bad photo of the {}.',
'a cropped photo of the {}.',
'a tattoo of a {}.',
'the embroidered {}.',
特征学习
这里作者讨论了下游任务用全部数据,CLIP 的效果会如何。特征学习一般都是先预训练一个模型,然后在下游任务上用全部的数据做微调。这里在下游任务上用全部数据就可以和之前的特征学习方法做公平对比了。
衡量模型的性能最常见的两种方式就是通过 linear probe 或 fine-tune 后衡量其在各种数据集上的性能。linear probe 就是把预训练好的模型参数冻结,然后在上面训练一个分类头;fine-tune 就是把整个网络参数都放开,直接去做 end-to-end 的学习。fine-tune 一般是更灵活的,而且在下游数据集比较大时,fine-tune往往比 linear probe 的效果要好很多。
但本文作者选用了 linear probe,因为 CLIP 的工作就是用来研究这种跟数据集无关的预训练方式,如果下游数据集足够大,整个网络都放开再在数据集上做 fine-tune 的话,就无法分别预训练的模型到底好不好了(有可能预训练的模型并不好,但是在 fine-tune 的过程中经过不断的优化,导致最后的效果也很好)。而 linear probe 这种用线性分类头的方式,就不太灵活,整个网络大部分都是冻住的,只有最后一层 FC 层是可以训练的,可学习的空间比较小,如果预训练的模型不太好的话,即使在下游任务上训练很久,也很难优化到特别好的结果,所以更能反映出预训练模型的好坏。此外,作者选用 linear probe 的另一个原因就是不怎么需要调参,CLIP 调参的话太耗费资源了,如果做 fine-tune 就有太多可做的调参和设计方案了。
CLIP比所有的其他模型都要好,不光是上文中讲过的 zero-shot 和 few-shot,现在用全部的数据去做训练时 CLIP 依然比其他模型强得多。
局限
CLIP 在很多数据集上平均来看都能和普通的 baseline 模型(即在 ImageNet 训练的 ResNet50)打成平手,但是在大多数数据集上,ResNet50 并不是 SOTA,与最好的模型比还是有所差距的,CLIP 很强,但又不是特别强。实验表明,如果加大数据集,也加大模型的话,CLIP 的性能还能继续提高,但如果想把各个数据集上的 SOTA 的差距弥补上的话,作者预估还需要在现在训练 CLIP 的计算量的基础上的 1000 倍,这个硬件条件很难满足。如果想要 CLIP 在各个数据集上都达到 SOTA 的效果,必须要有新的方法在计算和数据的效率上有进一步的提高。
zero-shot CLIP 在某些数据集上表现也并不好,在一些细分类任务上,CLIP 的性能低于 ResNet50。同时 CLIP 也无法处理抽象的概念,也无法做一些更难的任务(如统计某个物体的个数)。作者认为还有很多很多任务,CLIP 的 zero-shot 表现接近于瞎猜。
CLIP 虽然泛化能力强,在许多自然图像上还是很稳健的,但是如果在做推理时,这个数据与训练的数据差别非常大,即 out-of-distribution,那么 CLIP 的泛化能力也很差。比如,CLIP 在 MNIST 的手写数字上只达到88%的准确率,一个简单的逻辑回归的 baseline 都能超过 zero-shot CLIP。 语义检索和近重复最近邻检索都验证了在我们的预训练数据集中几乎没有与MNIST数字相似的图像。 这表明CLIP在解决深度学习模型的脆弱泛化这一潜在问题上做得很少。 相反,CLIP 试图回避这个问题,并希望通过在如此庞大和多样的数据集上进行训练,使所有数据都能有效地分布在分布中。
虽然 CLIP 可以做 zero-shot 的分类任务,但它还是在你给定的这些类别中去做选择。这是一个很大的限制,与一个真正灵活的方法,如 image captioning,直接生成图像的标题,这样的话一切都是模型在处理。 不幸的是,作者发现 image captioning 的 baseline 的计算效率比 CLIP 低得多。一个值得尝试的简单想法是将对比目标函数和生成目标函数联合训练,希望将 CLIP 的高效性和 caption 模型的灵活性结合起来。
CLIP 对数据的利用还不是很高效,如果能够减少数据用量是极好的。将CLIP与自监督和自训练方法相结合是一个有希望的方向,因为它们证明了比标准监督学习更能提高数据效率。
在研发 CLIP 的过程中为了做公平的比较,并得到一些回馈,往往是在整个测试的数据集上做测试,尝试了很多变体,调整了很多超参,才定下了这套网络结构和超参数。而在研发中,每次都是用 ImageNet 做指导,这已经无形之中带入了偏见,且不是真正的 zero-shot 的情况,此外也是不断用那 27 个数据集做测试。创建一个新的任务基准,明确用于评估广泛的 zero-shot 迁移能力,而不是重复使用现有的有监督的数据集,将有助于解决这些问题。
因为数据集都是从网上爬的,这些图片-文本对儿基本是没有经过清洗的,所以最后训练出的 CLIP 就很可能带有社会上的偏见,比如性别、肤色、宗教等等。
虽然我们一直强调,通过自然语言引导图像分类器是一种灵活和通用的接口,但它有自己的局限性。 许多复杂的任务和视觉概念可能很难仅仅通过文本来指导,即使用语言也无法描述。不可否认,实际的训练示例是有用的,但 CLIP 并没有直接优化 few-shot 的性能。 在作者的工作中,我们回到在CLIP特征上拟合线性分类器。 当从 zero-shot 转换到设置 few-shot 时,当 one-shot、two-shot、four-shot 时反而不如 zero-shot,不提供训练样本时反而比提供少量训练样本时查了,这与人类的表现明显不同,人类的表现显示了从 zero-shot 到 one-shot 大幅增加。今后需要开展工作,让 CLIP 既在 zero-shot 表现很好,也能在 few-shot 表现很好。
快速上手
skimage自带图像与描述文字的相似度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
import numpy as np
import torch
from pkg_resources import packaging
import clip
# 导入数据
model, preprocess = clip.load("ViT-B/32") # 加载模型
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
# Model parameters: 151,277,313
# Input resolution: 224
# Context length: 77
# Vocab size: 49408
import os
import skimage
import IPython.display
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from collections import OrderedDict
import torch
# 描述文字
descriptions = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}
original_images = []
images = []
texts = []
for filename in [filename for filename in os.listdir(skimage.data_dir) if filename.endswith(".png") or filename.endswith(".jpg")]:
name = os.path.splitext(filename)[0]
if name not in descriptions:
continue
image = Image.open(os.path.join(skimage.data_dir, filename)).convert("RGB")
original_images.append(image)
images.append(preprocess(image))
texts.append(descriptions[name])
image_input = torch.tensor(np.stack(images)).cuda()
text_tokens = clip.tokenize(["This is " + desc for desc in texts]).cuda() # shape: 8*77
# 512 dimension
with torch.no_grad():
image_features = model.encode_image(image_input).float()
text_features = model.encode_text(text_tokens).float()
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
cifar100的标签分类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 加载数据
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
# 描述文字
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
# 展示概率最高的top5分类
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
判断性别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
classes = ['man', 'woman']
image_input = preprocess(Image.open('man.jpg')).unsqueeze(0)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in classes])
#特征编码
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
#选取参数最高的标签
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(1)
#输出结果
print("\nTop predictions:\n")
print('classes:{} score:{:.2f}'.format(classes[indices.item()], values.item()))
迁移训练
其中image_caption_dataset用来加载图像文字对,load_data调用image_caption_dataset来包装训练数据对。 load_pretrian_model用于加载训练用的模型,jit需要设置为False。 通过logits_per_image, logits_per_text = model(images, texts)可以得到预测结果,与torch.arange(N)计算交叉熵进行优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
from PIL import Image
import os
device = 'cuda' if torch.cuda.is_available() else 'cpu'
class image_caption_dataset(Dataset):
def __init__(self, df, preprocess):
self.images = df["image"]
self.caption = df["caption"]
self.preprocess = preprocess
def __len__(self):
return len(self.caption)
def __getitem__(self, idx):
images = self.preprocess(Image.open(self.images[idx]))
caption = self.caption[idx]
return images, caption
def load_data(cup_path, cupnot_path, batch_size, preprocess):
df = {'image': [], 'caption':[]}
cup_list = os.listdir(cup_path)
cupnot_list = os.listdir(cupnot_path)
caption = cup_path.split('/')[-1]
for img in cup_list:
img_path = os.path.join(cup_path, img)
df['image'].append(img_path)
df['caption'].append(caption)
caption = cupnot_path.split('/')[-1]
for img in cupnot_list:
img_path = os.path.join(cupnot_path, img)
df['image'].append(img_path)
df['caption'].append(caption)
dataset = image_caption_dataset(df, preprocess)
train_dataloader = DataLoader(dataset, batch_size=batch_size)
return train_dataloader
def convert_models_to_fp32(model):
for p in model.parameters():
p.data = p.data.float()
p.grad.data = p.grad.data.float()
def load_pretrian_model(model_path):
model, preprocess = clip.load(model_path, device=device, jit=False) # 训练时 jit必须设置为false
if device == "cpu":
model.float()
else:
clip.model.convert_weights(model)
return model, preprocess
def train(epoch, batch_size, learning_rate, cup_path, cupnot_path):
# 加载模型
model, preprocess = load_pretrian_model('ViT-B/32')
#加载数据集
train_dataloader = load_data(cup_path, cupnot_path, batch_size, preprocess)
#设置参数
loss_img = nn.CrossEntropyLoss().to(device)
loss_txt = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.98), eps=1e-6, weight_decay=0.2)
for i in range(epoch):
for batch in train_dataloader:
list_image, list_txt = batch
texts = clip.tokenize(list_txt).to(device)
images = list_image.to(device)
logits_per_image, logits_per_text = model(images, texts)
if device == "cpu":
ground_truth = torch.arange(batch_size).long().to(device)
else:
ground_truth = torch.arange(batch_size, dtype=torch.long, device=device)
#反向传播
total_loss = (loss_img(logits_per_image, ground_truth) + loss_txt(logits_per_text, ground_truth)) / 2
optimizer.zero_grad()
total_loss.backward()
if device == "cpu":
optimizer.step()
else:
convert_models_to_fp32(model)
optimizer.step()
clip.model.convert_weights(model)
print('[%d] loss: %.3f' %(i + 1, total_loss))
torch.save(model, './model/model1.pkl')
def main():
epoch = 100
batch_size = 6
learning_rate = 5e-5
cup_path = './data/It is photo with cup'
cupnot_path = './data/It is photo without cup'
train(epoch, batch_size, learning_rate, cup_path, cupnot_path)
if __name__ == '__main__':
main()