Improving Medical Predictions by Irregular Multimodal Electronic Health Records Modeling
读论文时间!
代码:github
介绍
重症监护室 (ICU) 患者的健康状况通过电子健康记录 (EHR) 进行监测,这些记录由数字时间序列和冗长的临床笔记组成,并在不规则的时间间隔内进行采集。
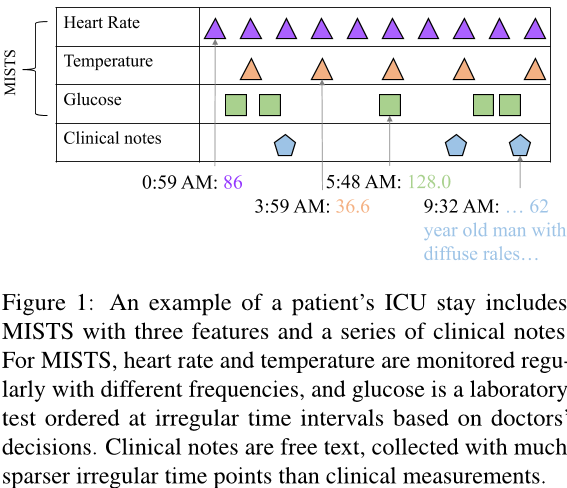
图片解释:一个病人ICU停留的示例包括三个特征的MISTS和一系列临床记录。对于MISTS,心率和体温以不同的频率定期监测,并根据医生的决定在不规则的时间间隔内进行实验室检查。临床记录是自由文本,与临床测量相比,在稀疏得多的不规则时间点收集。
MISTS: multivariate irregularly sampled time series,多变量不规则采样时间序列
处理所有模式中的这种不规则性并将其整合到多模态表示中以提高医学预测能力是一项具有挑战性的任务。
因此,我们制定了两个研究目标:
- 解决时间序列和临床记录中的不规则性。
- 将不规则性整合到多模态表示学习中。
我们观察到现有工作中不规则多模态 EHR 模型化的主要缺点有三点:
- MISTS模型表现多样:虽然已经提出了许多用于解决不规则性的 MISTS 模型,但没有一种方法始终优于其他方法。
- 临床记录中的不规则性尚未得到很好的处理:大多数现有工作直接将每个患者的全部临床记录连接起来,但忽略了记录时间信息。
- 现有工作的多模态融合忽视了不规则性。
为了解决上述问题,我们分别对MISTS和不规则临床记录进行建模,并进一步在时间步骤上整合多模式,以便基于复杂的不规则时间模式和EHR的多模式结构提供强大的医学预测。
我们的方法:
首先,动态地将手工制作的插值嵌入集成到学习的插值嵌入中,从而对每个单个模式中的不规则性进行建模。换句话说,我们通过引入一种门控机制来证明处理MISTS的不同TDE方法对于医疗预测是互补的,该机制包括针对每个患者的不同的TDE嵌入。
Temporal Discretization-based Embedding (TDE) ,基于时间的离散化嵌入
其次,我们将笔记表示和记笔记的时间视为MISTS,并利用一个时间注意力机制来建模笔记表示中每个维度的不规则性。
最后,我们采用一种融合方法将不规则性纳入多模式表示中,该方法使用交互式自注意力和交叉注意力来跨时间步整合多模式知识。
我们的全面消融研究证明了每个模态都处理不规则性不仅有益于其自身的模态还有助于多模式融合。我们还展示了进一步建模长序列临床记录可以提高医学预测性能。
相关工作
MISTS 指的是在不规则的时间间隔内对每个变量进行观察所获得的内容,可能不同变量之间的观察时间也不一致。
TDE 方法是处理 MISTS 的一种子集方法,将它们转换为固定维数特征空间,并将定期时间表示馈入深度神经模型以用于定期时间序列。
插值方法是一种简单的 TDE 方法,它通过手动填充缺失值将 MISTS 分离成常规时间序列,但忽略了原始数据中的不规则性。
为了充分建模不规则性,我们将临床笔记表示为MISTS,其中每个维度是一系列临床笔记表示的不规则时间序列,并执行时间注意力机制以进一步建模不规则性。
之前的多模态融合方法只针对 EHRs,未考虑不规则性,未能充分将时间信息纳入多模态表示,而这在现实世界情况下至关重要。为了填补这一空白,我们首先分别解决时间序列和临床笔记中的不规则性问题,并进一步利用融合模块,该模块交替使用自注意力和交叉注意力,以在时间步长内整合具有不规则性的多模态交互。
模型
我们的方法在三个部分中建模不规则性:MISTS、临床记录和多模式融合,如下图:
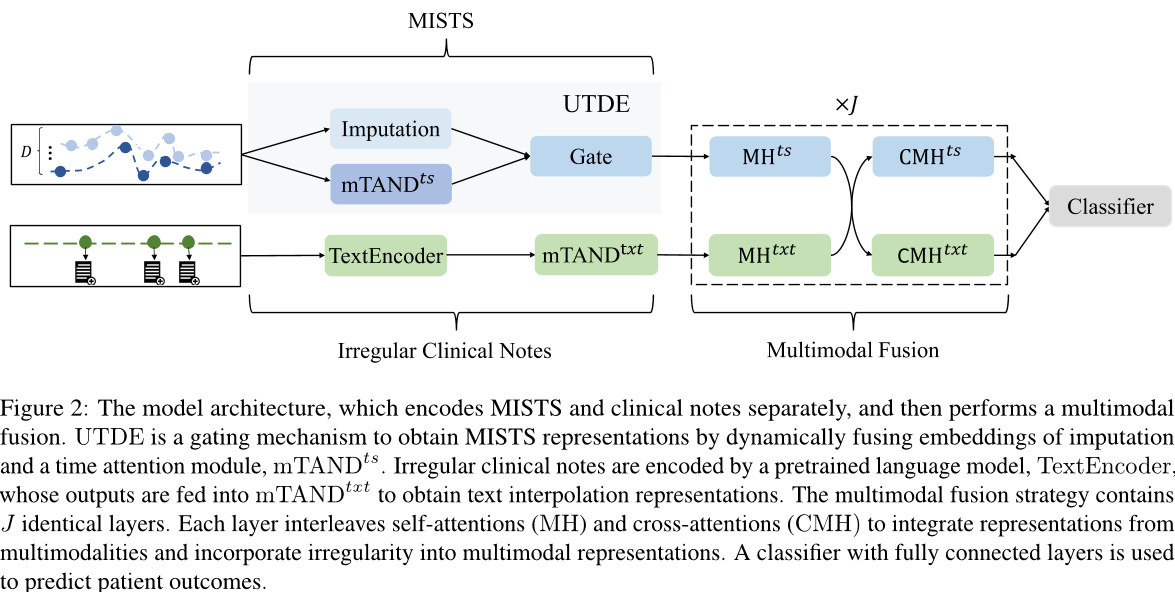
图片解释:模型架构,它分别对 MISTS 和临床记录进行编码,然后执行多模式融合。
- UTDE 是一个门控机制,通过动态融合缺失值嵌入和时间注意力模块 mTANDts 来获得 MIST 表示形式。
- 使用预训练语言模型 TextEncoder 编码不规则的临床记录,其输出被馈送到 mTANDtxt 以获得文本插值表示形式。
- 多模式融合策略包含 J 个相同的层。每个层交替使用自注意力 (MH) 和交叉注意力 (CMH) 来整合来自多个模态的表示,并将不规则性纳入多模式表示中。
- 使用具有全连接层的分类器来预测患者结果。
一些简写:
- UTDE:Unified Temporal Discretization-based Embedding
- mTAND:Discretized multi-time attention
- ts:time series
定义
含N个患者的EHR数据集定义为:
\[\mathcal{D}= \{ (x_i^{ts}, t_i^{ts}), (x_i^{txt}, t_i^{txt}),y_i \}\]- 其中, (xtsi, ttsi) 是 $d_m$ 维MISTS
- xtsi 表示观察值
- ttsi表示相应的时间点
- (xtxti, ttxti)是一系列临床记录和记录时间
- yi是目标结果,例如预测模式的出院或死亡
在下面的部分中,我们为了简单起见省略了患者索引 i
- 每个维度的MISTS, $(x_j^{ts}, t_j^{ts})$ , 其中 $j = 1, …, d_m$,拥有 $l_j^{ts}$ 个观测
- 每个患者的$(x^{txt}, t^{txt})$ , 有 $l^{txt}$ 个观测
在早期阶段的医学预测中,给定 $(x^{ts}, t^{ts})$ 和 $(x^{txt}, t^{txt})$,在某个时间点(例如入院后48小时)之后,我们希望预测每个患者的y。
TDE
为了更好地介绍我们提出的MISTS嵌入方法,我们将描述两种TDE方法。 下图中显示了示例以帮助理解。
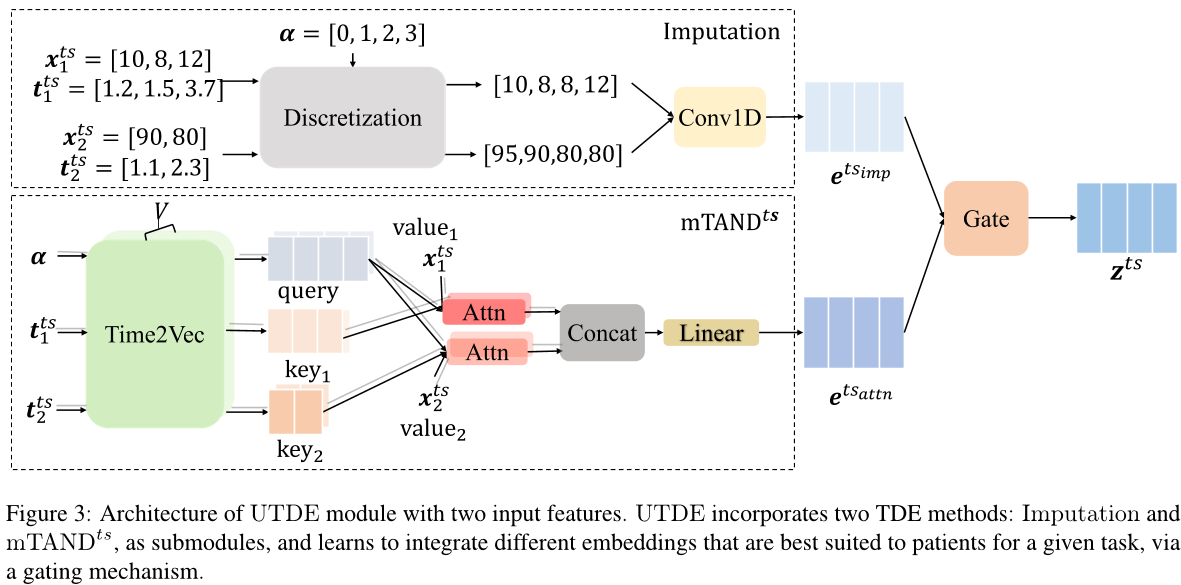
图片解释:带有两个输入特征的UTDE模块架构。UTDE通过子模块将两种TDE方法融合起来:插值和mTANDts,并通过门控机制,学习为给定任务整合最适合患者的嵌入。
插补方法
我们首先根据 $t^{tx}$ 对 $x^{tx}$ 进行离散化,使其成为具有规则时间点序列的,每小时级的,时间间隔。其中 α= [0, 1,…, α−1]。然后,对于每个特征,如果一个间隔存在多个观测值,则使用最后一个观测值,将没有观察到任何观察值的间隔视为缺失值。
如果存在,则用最近的观测值来填充缺失值,否则用所有患者的总体均值来填充。

举个例子,如图。对于预测 α=[0, 1, 2, 3] 这住院后的前四个小时,在 [1.2, 1.5, 3.7] 小时后入院的收集特征值 [10, 8, 12] 被离散化为 [miss1, 8, miss2, 12],其中 miss1 和 miss2 分别由全局平均值和先前观测到的值进行插补。常规时间序列被馈送到一个步长为 1 的 1D 因果卷积层中,以获得具有隐藏维度 $d_h$ 的插值嵌入,即 $e^{ts_{imp}}∈\R ^{\alpha \times d_h}$
离散多时间注意力 mTAND
我们利用离散多时间注意力模块将 MISTS 重新表示为α。
为了整合 MISTS 的不规则时间知识,学习了一个时间表示 Time2Vec,将连续时间点列表中的每个值 $\tau$ (任意的长度 $l_\tau$), 转换为大小为 $d_v$ 的向量,并获得一系列时间嵌入 $θ(τ)∈\R ^{l_τ×d_v}$
\[\theta(\tau)[i]= \left\{ \begin{array}{l} w_i \tau + \phi_i & \text{if }i=1 \\ \text{sin}(w_i \tau + \phi_i) & \text{if } 1<i<d_v \end{array} \right.\]- $\theta(\tau)[i]$ 是 Time2Vec 的第 i 维
- ${ w_i,\phi_i }^{d_v}_{i=1}$ 是可学习参数
- 正弦函数捕获周期模式,而线性项根据时间推移捕获非周期行为
mTAND 模块利用了 V 个不同的Time2Vec, $ { \theta_v(\cdot)}^V_{v=1}$,基于一个时间注意力机制来产生在α处的插值嵌入。
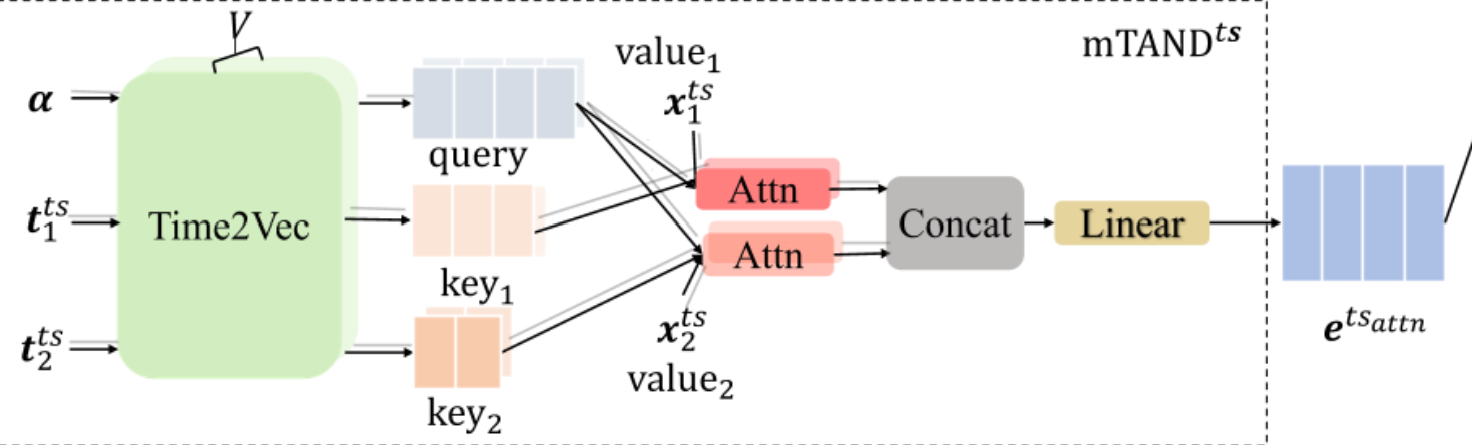
具体来说,与多头注意力机制类似,$ { \theta_v(\cdot)}^V_{v=1}$ 对α 和所有 MISTS 的维度进行操作,以同时将所有时间点嵌入到 V 个不同的 $d_v$ 维隐藏空间中,从而捕捉不同时间点在不同子时空中整体时间信息的各种特征。
对于每个 $\theta_v(\cdot)$ ,对 MISTS 的每个维度执行一个时间注意机制,它将α作为查询q、$t^{ts}_j$ 作为键k、$x^{ts}_j$ 作为值v,并获得 $\hat{x}^{ts}_j \in \R^\alpha$,它是对应于单变量时间序列的 α 的一系列插值。因此,通过以下方式获得了插值矩阵 $o^{ts}_v \in \R^{\alpha \times d_m}$
\[o^{ts}_v = [\hat{x}^{ts}_1, \hat{x}^{ts}_2,...,\hat{x}^{ts}_{d_m}]\] \[\hat{x}^{ts}_j=\text{Attn}(\theta_v(\alpha)w_v^q,\theta_v(t^{ts}_j)w_k^q,x_j^{ts})\]$j = 1, …, d_m$,w 是可学习参数,之后 $o^{ts}1,o^{ts}_2,….o^{ts}_V$ 进一步连接并线性投影以获得 mTAND的嵌入,$e^{ts{attn}}∈\R ^{\alpha \times d_h}$
UTDE
小标题原文UNIFYING TDE METHODS
插补方法忽略了时间序列的不规则性,而 mTAND 可能会导致性能下降,这可能是由于不同的时间序列采样策略。我们通过门控机制提出了一种UTDE (Unified Temporal Discretization-based Embedding)模块以利用这两种技术来解决电子病历中的复杂时间模式。结构如图。
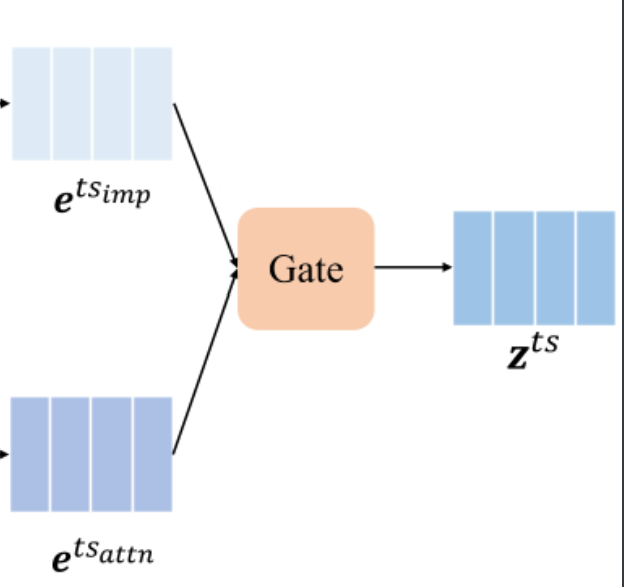
UTDE 将插值和 mTAND 集成为子模块,并学习将 $e^{ts_{imp}}$ 动态集成到 $e^{ts_{attn}}$ 中以获得复合嵌入向量 $z^{ts}∈\R ^{\alpha \times d_h}$
\[\text{z}^{ts}= \text{g}\odot \text{e}^{ts_{imp}} + (1-\text{g})\odot \text{e}^{ts_{attn}}\] \[\text{g} = f( \text{e}^{ts_{imp}} \otimes \text{e}^{ts_{attn}})\]- $f(\cdot)$ 是一个由 MLP 实现的门控函数
- ⊕ 是串联操作
- $\otimes$ 是点积
具体来说,我们在三个层次上执行 UTDE,g 在每个层次上具有不同的维度
- 患者级别,g∈ $\R$
- 时间级别,g∈ $\R^α$
- 隐藏空间级别,g ∈ $\R^{α×d_h}$
在隐藏空间级别上的 g 可能比时间和患者级别的 g 更强大,但它引入了更多的参数以供更新,从而使整个模块更难以优化。在实验部分,我们使用验证集来确定操作的层次。原则上,UTDE 可以应用于任何两种 TDE 方法。在这里,我们基于经验结果利用插值和 mTAND 作为子模块。
不规则临床记录
为了从临床记录中提取相关信息,我们首先使用域内预训练语言模型 TextEncoder 对文本进行编码。
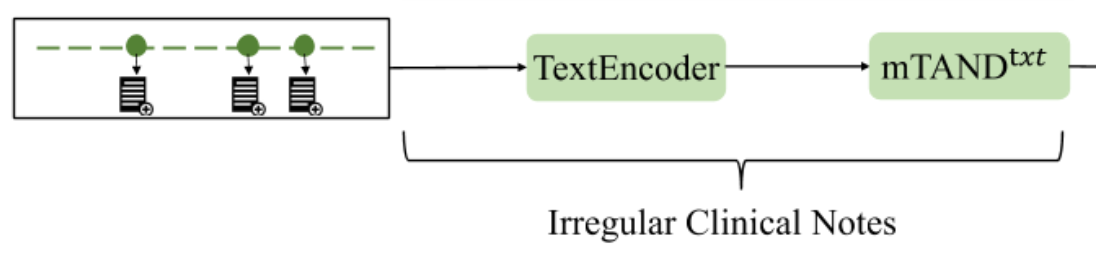
然后,我们为每个编码的临床记录提取 [CLS] 令牌的表示形式,以获得一系列条目表示形式 $e^{txt}∈\R^{l^{txt}×d_t}$,其中 $d_t$ 是编码文本的隐藏维度。
\[e^{txt} = \text{TextEncoder}(x^{txt})\]为了解决不规则性,我们按 $t^{txt}$ 对 $e^{txt}$ 进行排序,并将 $(e^{txt},t^{txt})$ 表示为MISTS,使每个隐藏维度的 etxt 都是一个时间序列序列,而每个时间序列序列都具有相同的收集时间点。
进一步利用 mTAND 模块重新表示 etxt 到α。具体来说,mTANDtxt 以α作为查询,ttxt作为键,etxt作为值并输出 $z^{txt}∈\R^{α \times d_h}$,即一组在α处的文本插值表示。
\[z^{txt} = \text{mTAND}^{txt}(\alpha, t^{txt}, e^{txt})\]对于 mTANDts,用于时间序列的 mTAND 模块,以及 mTANDtxt,我们使用相同的 ${θ_v(·)}^V_{v=1}$ 来编码两个模态的不规则时间点以获得时序知识,因为所有连续的时间点都在同一个特征空间中。
然而,mTANDts 和 mTANDtxt 中的所有其他组件都是分开学习的,因为时间序列和临床记录的表示位于不同的隐藏空间中。
此外,由于 mTANDtxt 把 ztxt 投影到与 zts 相同的维度 dh,因此可以在融合中的注意力模块中采用点积。
多模态融合
我们的多模态融合模块由J个相同的层堆叠而成。每个层都包含两个自注意力子层和两个跨时间步长的交叉注意力子层,以探索两种模式之间的潜在交互作用。
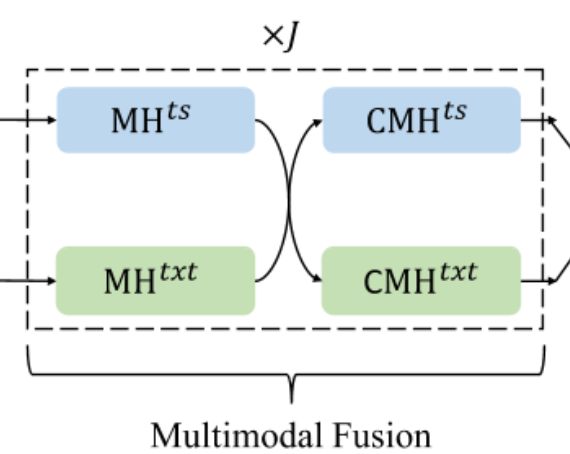
具体来说,在第 j 层中,对于每种模式,我们首先通过采用来自相应 j-1 层的对应模式的输出来执行跨时间步长的多头自注意(MH)以获得上下文嵌入。
\[\hat{z}_j^{ts}=MH_j^{ts}(z_{j-1}^{ts})\] \[\hat{z}_j^{txt}=MH_j^{txt}(z_{j-1}^{txt})\]其中,j = 1 … J,并且 $z^{ts}_0 = z^{ts},z^{txt}_0 = z^{txt}$
为了捕获两种模式之间的跨模态信息,我们利用了两个多头交叉注意力(CMH)来学习当前模式关注的另一种模式的知识,反之亦然。
具体来说,在第 j 层的时间序列分支中,一个 $CMH^{ts}_j$ 将 $\hat{z}_j^{txt}$ 转换为键值对以与时间序列模态进行交互,并输出 $z^{ts}_j$,它是带有从临床记录传递的信息的时间序列表示。对于文本分支,执行相同的过程。
\[z_j^{ts}=CMH_j^{ts}(\hat{z}_j^{ts}, \hat{z}_j^{txt})\] \[z_j^{txt}=CMH_j^{txt}( \hat{z}_j^{txt}, \hat{z}_j^{ts})\]在每个模态的 MH 输出上堆叠了一个 position-wise 前馈子层。我们在每个 MH、CMH 和前馈子层中应用预层归一化和残差连接。为了简单起见,我们在模型图中仅绘制了多模式融合中的 MH 和 CMH。
在这个过程中,每个模态通过MH交替收集时间知识,并通过CMH从另一个模态获得外部信息来更新其序列。经过J层后,zts和ztxt中的每一项都充分整合了来自另一种模态的信息。最终,从ztsJ和ztxt中提取出最后的隐藏状态并连接起来,以通过具有全连接层的分类器进行预测。
实验
两个任务:48小时住院死亡预测(48-IHM)和24小时表型分类(24-PHE)
数据集
MIMIC III 是一个包含 ICU 患者的真实世界公共 EHR 的数据库,包括数值时间序列和临床笔记,在预测时间之前没有任何临床笔记的患者被删除。经过预处理后,用于 48-IHM 的训练、验证和测试数据中的患者数量分别为 11181、2473 和 2488;对于 24-PHE,它们分别是 15561、3410 和 3379。
评价指标
48-IHM 是一个死亡与出院比率为大约1:7 的不平衡二元分类问题。 24-PHE 是一个多标签分类问题,有25种急性护理状况,由于预测时间较早和更多的预测类别,因此更具挑战性。 在48-IHM上使用F1和AUPR,在24-PHE上使用F1(宏平均)和AUC。
MISTS baselines
我们使用 Transfomer 作为UTDE 和TDE 方法的基础,我们将时间序列嵌入馈送到transformer,并提取transformer输出的最后一个隐藏状态以通过全连接层进行预测。我们在基线中最初添加了两种旨在用于预测任务的方法:DGM2-O、MTGNN。
不规则临床笔记 baselines
考虑到领域知识和临床记录长度,我们使用 Clinical-Longformer 作为我们的文本编码器,其最大输入序列长度为1024,可覆盖两个任务中超过98%的记录。
与时间序列模态一样,我们将由 mTANDtxt 获得的文本插值表示馈入 Transfomer 进行预测。
消融实验
- 比较mTAND和IP-Net,证明了 UTDE 中门控机制的有效性。
- 在 MISTS 中使用不同骨干的 UTDE,包括 CNN、LSTM、Transfomer,Transfomer效果优秀
- 通过融合模型中去掉 UTDE,证明 UTDE 有益于多模态融合性能。
- 通过删除了mTANDtxt,并直接将一系列临床记录表示与UTDE表示进行融合,证明了解决临床记录中的不规则性能提高多模态融合性能。
- 通过改变临床记录表示的长度,证明了各种评估指标中任务性能随着最大输入序列长度的增加而提高。
训练细节
我们使用批量大小为 32,预训练语言模型 (PLMs) 的学习率为 2 × 10 ^ -5,其他为 0.0004。 我们使用基于梯度的优化算法 Adam 进行优化。 我们存储在验证集上获得的最佳 F1 和宏 F1 分数的参数,并将其用于对测试样本进行预测,分别对应于 48-IHM 和 24-PHE。
对于所有 MISTS 模型,我们在 20 个 epoch 的训练中运行模型。我们搜索插值、mTAND、IP-Net、GRU-D 和 SeFT 中隐藏单元的数量,并在 {64,128} 范围内进行搜索。对于插值,我们将 1D 卷积核大小设置为 1。在 mTAND 中,我们在 {64,128} 范围内搜索时间嵌入的隐藏大小,并将时间嵌入的数量 V 设置为 8。我们使用一个包含 3 层编码器的 Transformer 作为插值、mTAND 和 IP-Net 的主干编码器。在 UTDE 中,我们在与仅使用单个方法的模型相同的范围内搜索子模块插值和 mTAND 的超参数,并使用一个包含 3 层编码器的 Transformer 作为主干编码器。我们在 “患者”、“时间”和“隐空间”中搜索门控集成级别。
在我们的初步研究中,我们通过经验发现临床笔记模态的所有模型都在6个 epoch 内收敛,因此我们将所有模型训练了6个epoch。此外,我们还发现,在前3个epoch微调 PLM 并在后期将其视为特征提取器比在整个训练过程中微调 PLM 能够获得更好的结果。我们搜索T-LSTM、FT-LSTM、GRU-D 和 mTANDtxt 的隐藏单元,取值范围为 {64,128}。对于 mTANDtxt,时间嵌入的隐藏大小在 {64,128} 范围内搜索,嵌入的数量 V 等于 8。
与临床记录模态相同,我们在所有融合模型上运行了 6 个 epoch,并在前三个 epoch 中微调 PLM。我们使用 3 层 Transformer 编码器对每个模态进行编码以形成 Concat、MAG 和 TF。对于 MulT,我们在每个模态上执行 3 层跨模态 Transformer 后跟 3 层自注意力 Transformer。我们为多模态融合策略(J = 3)学习了一个 3 层交错 Transformer。我们在每个单模设置中搜索 UTDE 和 mTANDtxt 的超参数。我们在 {64,128} 范围内搜索 Transformer 的隐藏大小。