Denoising Diffusion Probabilistic Models
读论文时间!
扩散模型改进:DDPM
官方代码: https://github.com/hojonathanho/diffusion
背景知识
扩散模型是一种潜在变量模型。用于生成与观测数据分布相似的新数据。它通过将数据从一个简单的分布(例如高斯分布)逐步扩散到复杂的观测数据分布中实现。
潜在变量模型(Latent Variable Model)是一类用于解释观测数据生成过程的统计模型。它假设数据是由一些不可观测(潜在)的变量生成的,这些潜在变量帮助解释观测数据的结构和关系。潜在变量模型的目标是通过推断这些潜在变量,从而更好地理解观测数据的生成机制。
扩散模型形式如下,可以看作概率课学过的边缘概率分布:
\[p_θ(\mathrm{x}_0) := \int p_θ(\mathrm{x}_{0:T}) \, d\mathrm{x}_{1:T} \tag{1}\]其中,\(\mathrm{x}_1, ..., \mathrm{x}_T\) 是与数据 \(\mathrm{x}_0\sim q(\mathrm{x}_0)\) 具有相同维度的潜在变量。

\(q(\mathrm{x}_0)\)表示真实观测数据 \(\mathrm{x}_0\) 的分布,这些数据是从某个实际存在但未知的复杂分布中采样而来的。例如,在图像生成任务中,\(q(\mathrm{x}_0)\) 是所有自然图像的分布。
\(p_θ(\mathrm{x}_0)\) 是扩散模型生成的观测数据的分布。通过积分边际化潜在变量,我们得到这个分布来描述模型生成的样本的概率。通过优化模型参数 θ,我们希望 \(p_θ(\mathrm{x}_0)\) 能够逼近真实数据分布 \(q(\mathrm{x}_0)\),即生成的数据与真实数据无异。
扩散模型通过从一个简单分布(通常是高斯分布)逐步转换到复杂的观测数据分布来建模数据生成过程。为了实现这一点,它通常包括两个过程:前向过程和逆过程。
前向过程
即扩散过程,逐步向噪声中添加数据。形式上,它是给定观测数据 \(\mathrm{x}_0\),生成一系列潜在变量 \(\mathrm{x}_1, \mathrm{x}_2, ..., \mathrm{x}_T\) 的条件分布,这些中间状态(潜在变量)逐步从数据分布扩散到一个简单的高斯分布。
\[\begin{align} q(\mathrm{x}_{1:T}|\mathrm{x}_0) &:= q(\mathrm{x}_1|\mathrm{x}_0) q(\mathrm{x}_2|\mathrm{x}_1) \cdots q(\mathrm{x}_T|\mathrm{x}_{T-1}) \\ &:=\prod_{t=1}^Tq(\mathrm{x}_t|\mathrm{x}_{t-1}) \tag{2} \\ \end{align}\]连乘的形式来自马尔科夫链的性质。
在前向过程中,从数据 \(\mathrm{x}_0\) 开始逐步根据方差时间表\(\beta_1...\beta_t\)逐渐添加高斯噪声,使其变得越来越“模糊”或“噪声化”。最远的潜在变量 \(\mathrm{x}_T\) 由于噪声的累积,最终满足\(p(\mathrm{x}_T) = \mathcal{N}(\mathrm{x}_T; 0, \mathrm{I})\),即多维的标准正态分布,多维均值向量为0。\(\mathrm{I}\) 表示单位协方差矩阵,这意味着不同维度之间没有相关性,每个维度的方差都是1。
下图展示了一个由两个高斯分布组成的混合高斯模型如何一步步扩散到一个简单的高斯分布:
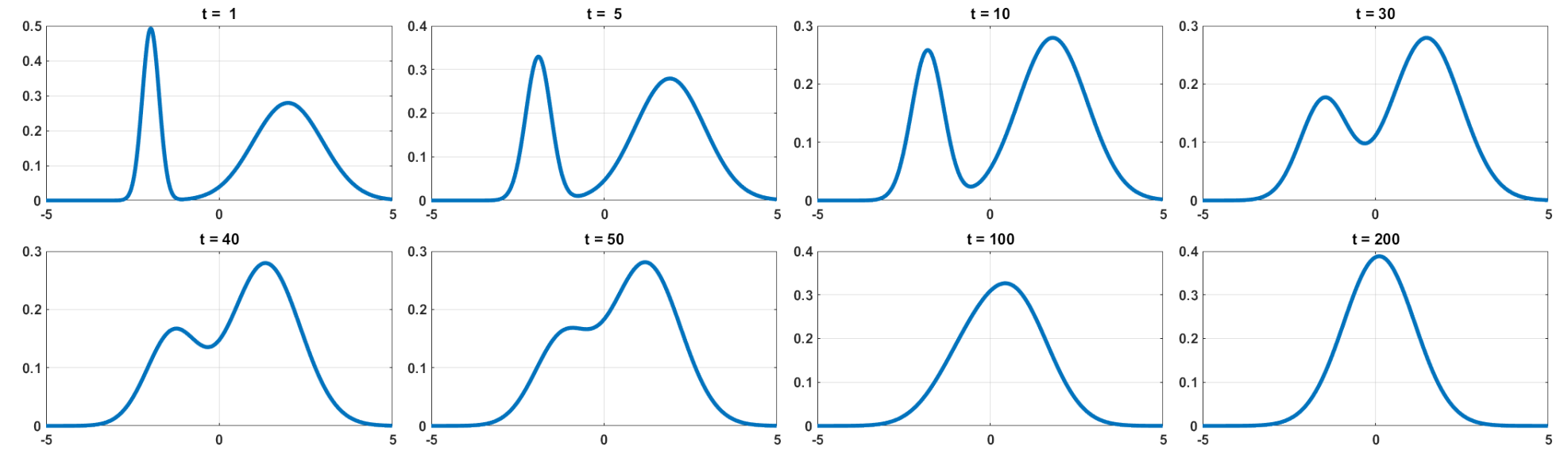
其中前向每一步的公式如下(令$\alpha_t := 1 - \beta_t$):
\[q(\mathrm{x}_t | \mathrm{x}_{t-1}) := \mathcal{N}(\mathrm{x}_t; \sqrt{1-\beta_t} \mathrm{x}_{t-1}, \beta_t \mathrm{I})\]我们不禁想问,这里的两个系数是怎么来的?背后的考虑是:当 t 足够大时,我们想要 \(\mathrm{x}_t\) 最后的分布等于 \(\mathcal{N}(0, \mathrm{I})\) ,经过一系列推导我们可以证明这两个参数就是我们想要的。
另外一个直观的解释是,如果我们控制 \(\beta\) 很小,那么每一步变化的均值基本是不变的,方差也接近0,但是累积起来,最后的分布等于 \(\mathcal{N}(0, \mathrm{I})\)
完整的证明见 Tutorial on Diffusion Models for Imaging and Vision 第13页
在前向过程方差中, \(\beta_t\) 可以通过重参数化学习或保持为超参数,令$\bar{\alpha}t := \prod{s=1}^t \alpha_s$,我们有:
\[q(\mathrm{x}_t | \mathrm{x}_{0}) := \mathcal{N}(\mathrm{x}_t; \sqrt{\bar{\alpha}_t} \mathrm{x}_{0}, (1-\bar{\alpha}_t) \mathrm{I}) \tag{3}\]这个式子的好处是我们不再需要一步一步计算,给定 \(\mathrm{x}_{0}\) 和 \(t\) ,我们可以一下子完成对 \(\mathbf{x}_t\) 的采样,而且我们可以控制 t 和 \(\alpha\) 的关系,控制最后的分布等于 \(\mathcal{N}(0, \mathrm{I})\)
完整的证明见 Tutorial on Diffusion Models for Imaging and Vision 第14页
反向过程
这是模型学习到的从噪声生成数据的过程。模型通过一系列条件概率来反向生成观测数据,我们把下面这个式子叫做潜在变量和观测数据的联合概率分布:
\[\begin{align} p_θ(\mathrm{x}_{0:T}) &:= p_θ(\mathrm{x}_0|\mathrm{x}_1) p_θ(\mathrm{x}_1|\mathrm{x}_2) \cdots p_θ(\mathrm{x}_{T-1}|\mathrm{x}_T) p_θ(\mathrm{x}_T) \\ & := p_θ(\mathrm{x}_{T}) \prod_{t=1}^T p_θ(\mathrm{x}_{t-1}|\mathrm{x}_{t}) \tag{4} \\ p_θ(\mathrm{x}_{t-1} | \mathrm{x}_t) &:= \mathcal{N}(\mathrm{x}_{t-1}; \mu_θ(\mathrm{x}_t, t), \Sigma_θ(\mathrm{x}_t, t)) \end{align}\]- \(\mu_θ(\mathrm{x}_t, t)\): 条件均值函数, \(θ\) 控制。它表示给定当前状态 \(\mathrm{x}_t\) 生成前一时刻状态 \(\mathrm{x}_{t-1}\),需要神经网络去学习。
- \(\Sigma_θ(\mathrm{x}_t, t)\) 条件协方差矩阵,\(θ\) 控制,它表示生成 \(\mathrm{x}_{t-1}\) 的不确定性,需要神经网络去学习。
边缘概率分布
\(\int p_θ(\mathrm{x}_{0:T}) \,d\mathrm{x}_{1:T}\) 表示对所有潜在变量 \(\mathrm{x}_1, \mathrm{x}_2, ..., \mathrm{x}_T\)进行积分,从而得到观测数据的边际概率分布 \(p_θ(\mathrm{x}_0)\)。这个积分的作用是消除潜在变量的影响,只剩下观测数据的概率。
这和马尔科夫链有一样的优美的性质:无记忆性。
损失函数
\[\begin{align} \mathcal{L} :&= \mathbb{E}\left[ - \log p_\theta(\mathbf{x}_0) \right] \\ & \leq \mathbb{E}_q \left[ - \log \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T}|\mathbf{x}_0)} \right] \\ & = \mathbb{E}_q \left[ \underbrace{D_{\mathrm{KL}}\left(q(\mathbf{x}_T | \mathbf{x}_0) \| p(\mathbf{x}_T) \right)}_{L_T} + \sum_{t > 1} \underbrace{D_{\mathrm{KL}}\left(q(\mathbf{x}_{t-1} | \mathbf{x}_t, \mathbf{x}_0) \| p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t)\right)}_{L_{t-1}} \underbrace{-\log p_\theta(\mathbf{x}_0 | \mathbf{x}_1)}_{L_0} \right] \end{align}\]我们的目标是使得模型 \(p_\theta\) 能够生成更接近真实数据 \(\mathbf{x}_0\) 的样本。在已有数据求分布时我们可以使用最小化似然的方法。\(- \log p_\theta(\mathbf{x}_0)\)表示真实数据 \(\mathbf{x}_0\) 在模型 \(p_\theta\) 下的负对数似然,于是优化目标就是最小化这个量,在公式中,我们处理其期望值,表示考虑到所有可能的情况。
不等式来自证据下界(Evidence Lower Bound, ELBO),它是最大化模型对数似然的常用方法。完整的证明见 Tutorial on Diffusion Models for Imaging and Vision 第5页。简而言之,当取等号时,真实的前向过程与模型中的前向过程的 KL 散度为 0。
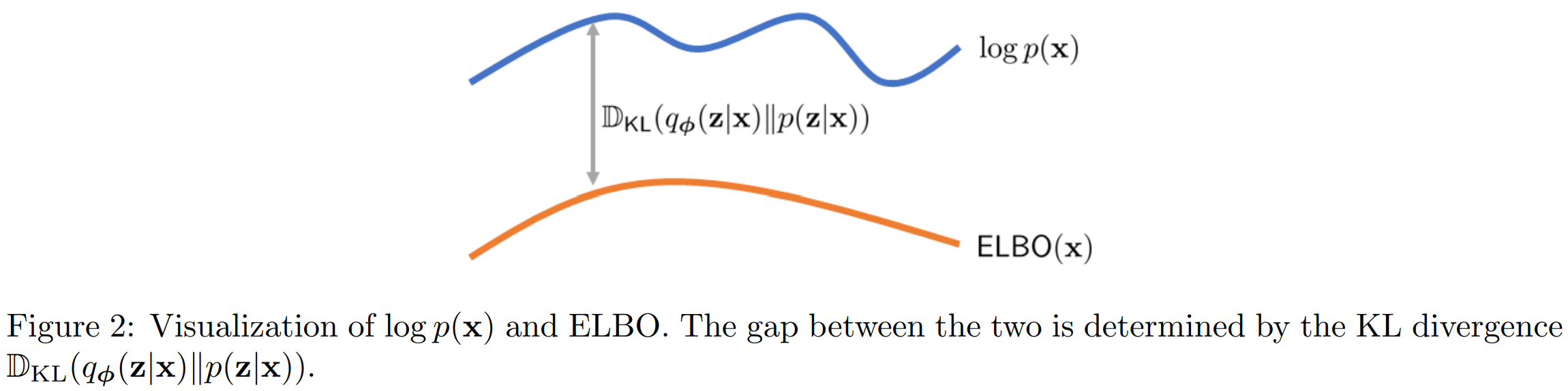
在不等式到最后一步之间,我们隐藏了大量的推导过程,完整的证明见 Tutorial on Diffusion Models for Imaging and Vision 第16~20页。或者本论文的附录A
最后得到的公式可以分为几个部分:
- \(L_T\)部分:衡量在 \(\mathbf{x}_T\) 上的真实前向过程 q 和先验分布 \(p(\mathbf{x}_T)\) 之间的差异。
- \(q(\mathbf{x}_T | \mathbf{x}_0)\): 从真实数据 \(\mathbf{x}_0\) 出发的真实扩散过程到最终的潜在变量 \(\mathbf{x}_T\)
- \(p(\mathbf{x}_T)\) : 终态的标准正态分布
- \(L_{t-1}\) 部分:衡量在每一个时刻 t 上,真实的后向过程 \(q(\mathbf{x}_{t-1} | \mathbf{x}_t, \mathbf{x}_0)\) 和模型的后向过程 \(p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t)\) 之间的差异。
- \(q(\mathbf{x}_{t-1} | \mathbf{x}_t, \mathbf{x}_0)\): 真实的后向扩散过程,从 \(\mathbf{x}_t\) 回到 \(\mathbf{x}_{t-1}\)
- \(p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t)\): 模型学习到的逆过程,从 \(\mathbf{x}_t\) 到 \(\mathbf{x}_{t-1}\)
- 负对数似然 \(L_0\) 部分:模型从潜在变量 \(\mathbf{x}_1\) 生成观测数据 \(\mathbf{x}_0\) 的对数似然。
- \(\mathbb{E}_q\) 表示对真实分布 q 进行期望值计算,表示我们在真实数据下的期望。
换句话说,这个公式分解了扩散模型的训练目标,将其分解为三个部分的和,而且方程中的所有KL散度都是高斯分布之间的比较,因此可以用闭合形式表达式而不是具有高方差的蒙特卡洛估计来计算:
- 终态的 KL 散度:衡量生成过程最后一步和标准正态分布之间的差异。
- 每个中间步骤的 KL 散度 :衡量在每一步生成过程中的逆过程和真实过程之间的差异。
- 初始状态的对数似然:衡量从生成潜在变量到观测数据的拟合程度。
上面的式子中,扩散模型中的真实反向过程公式如下:
\[q(\mathbf{x}_{t-1} | \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \tilde{\mu}_t(\mathbf{x}_t, \mathbf{x}_0), \tilde{\beta}_t \mathbf{I})\] \[\tilde{\mu}_t(\mathbf{x}_t, \mathbf{x}_0) := \frac{\sqrt{\bar{\alpha}_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_0 + \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1 - \bar{\alpha}_t} \mathbf{x}_t \tag{5}\] \[\tilde{\beta}_t := \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \beta_t\]系数由真实正向过程 \(q(\mathbf{x}_{t} | \mathbf{x}_{t-1})\) 通过贝叶斯技巧计算得来。完整的证明见 Tutorial on Diffusion Models for Imaging and Vision 第22页。
这个式子也非常好!因为所有的参数我们都知道,不需要神经网络来学习了!
消噪自编码器与扩散模型
扩散模型可能看起来像是一个受限制的潜在变量模型类,但它们在实现中允许大量的自由度。必须选择正向过程的方差 \(\beta_t\) 和反向过程的架构以及高斯分布参数化。为了指导我们的选择,我们建立了扩散模型与去噪自编码器之间的新显式联系,导致了简化后的、加权变分下限目标。
前向过程
我们忽略了前向过程方差 \(\beta_t\) 可以通过重参数化学习的事实,而是将其固定为常数(而且随着 t 变大而变大,这是因为,当样本变得更嘈杂时,我们可以承受更大的更新步骤)。因此,在我们的实现中,近似后验分布 q (对真实后验分布 \(p(\mathbf{z}|\mathbf{x})\) 的近似)没有可学习的参数,所以在训练过程中 \(L_T\) 是一个常数并可以忽略。
对高斯分布:\(\mathbf{z} \sim \mathcal{N}(\mathbf{\mu}, \mathbf{\sigma}^2)\) 直接对其进行优化比较困难,因为它依赖于随机抽样,梯度无法直接计算。重参数化技巧通过引入一个辅助噪声变量 \(\epsilon\) 将其转换为确定性参数,转换为可微分的操作,使得梯度可以直接通过反向传播计算:
\[\mathbf{z} = \mathbf{\mu} + \mathbf{\sigma} \odot \epsilon \quad \text{where} \quad \epsilon \sim \mathcal{N}(0, \mathbf{I})\]其中,符号 \(\odot\) 代表按元素(逐元素)的乘法。这样,我们将 \(\mathbf{z}\) 从一个随机变量变为 \(\mathbf{\mu}\) 和 \(\mathbf{\sigma}\) 的确定性函数,使得我们可以直接优化 \(\mathbf{\mu}\) 和 \(\mathbf{\sigma}\),而无需考虑抽样过程。
反向过程-最后一步
作者选择不去学习最后一步,使用一个独立的高斯实现最后一步,把连续的值离散化。
对于 \(L_0\) ,为了获得离散对数似然,我们将反向过程的最后一项设置为来自高斯 \(\mathcal{N}(\mathrm{x}_{0}; \mu_θ(\mathrm{x}_1, 1), \sigma^2_1 \mathbf{I})\) 的 独立离散解码器:
\[\begin{align} p_\theta(\mathbf{x}_0 \mid \mathbf{x}_1) &= \prod_{i=1}^D \int_{\delta_-(x_0^i)}^{\delta_+(x_0^i)} \mathcal{N}\left( x; \mu_\theta^i(\mathbf{x}_1, 1), \sigma_1^2 \right) dx \\ \delta_+(x) &= \begin{cases} \infty & \text{if } x = 1 \\ x + \frac{1}{255} & \text{if } x < 1 \end{cases} \\ \delta_-(x) &= \begin{cases} -\infty & \text{if } x = -1 \\ x - \frac{1}{255} & \text{if } x > -1 \end{cases} \end{align}\]其中D是数据维度,i 上标表示提取一个坐标。数字255是怎么来的?我们模型的输入图片 x 是RGB编码0~255之间的数,然后线性缩放至[-1, 1]。神经网络的反向过程就是把-1~1的值分成255份离散化。
这个公式是扩散模型原论文给出的,DDPM直接拿过来用,也不能指望它给出进一步的解释。
反向过程
对于 \(L_{t-1}\),我们讨论在\(p_θ(\mathrm{x}_{t-1} | \mathrm{x}_t) := \mathcal{N}(\mathrm{x}_{t-1}; \mu_θ(\mathrm{x}_t, t), \Sigma_θ(\mathrm{x}_t, t))\)中我们的选择。首先,我们将 \(\Sigma_θ(\mathrm{x}_t, t) = \sigma^2_t \mathbf{I}\) 设置为一个不训练的与时间相关的常数。在实验中,\(\sigma^2_t=\beta_t\) 和 \(\sigma_t^2=\tilde{\beta}_t = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \beta_t\) 效果相似。前者对于 \(\mathrm{x}_0 \sim \mathcal{N}(0, \mathbf{I})\) 是最优的,后者对于 \(\mathrm{x}_0\) 被确定性地设置在一个点上是最优的。这些对应于具有坐标单位方差的数据的反向过程熵的上下界。
还记得方程(5)吗,真实反向过程的均值和方差已知,模型反向过程的方差又被固定,那么,剩下的任务就只有(用神经网络)表示均值 \(\mu_θ(\mathrm{x}_t, t)\) 了,由于 \(p_θ(\mathrm{x}_{t-1} | \mathrm{x}_t) := \mathcal{N}(\mathrm{x}_{t-1}; \mu_θ(\mathrm{x}_t, t), \sigma^2_t \mathbf{I})\) ,KL 散度可以化简成:
\[L_{t-1} = \mathbb{E}_q \left[ \frac{1}{2\sigma_t^2} \left\| \tilde{\mu}_t(\mathbf{x}_t, \mathbf{x}_0) - \mu_\theta(\mathbf{x}_t, t) \right\|^2 \right] + C\]我们利用了这样一个事实:两个具有相同方差的高斯分布之间的KL散度只是两个均值向量之间的欧几里得距离的平方。
其中,C 是一个与 \(\theta\) 无关的常数。式子中 \(\tilde{\mu}_t(\mathbf{x}_t, \mathbf{x}_0)\) 已知。
在这个公式中,我们看到最直接的参数化 \(\mu_\theta\) 的形式是预测 \(\tilde{\mu}_t\),即前向过程后验均值。但是,我们可以进一步展开这个式子。我们重参数化上面的式子(3)得到 \(\mathrm{x}_t(\mathrm{x}_{0},\mathbf{\epsilon}) := \sqrt{\bar{\alpha}_t} \mathrm{x}_{0}+ (1-\bar{\alpha}_t) \mathbf{\epsilon}\) 并且加上反向过程的后验公式(5):
\[\begin{align} L_{t-1} - C &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \left[ \frac{1}{2\sigma_t^2} \left\| \tilde{\boldsymbol{\mu}}_t \left( \mathbf{x}_t (\mathbf{x}_0, \boldsymbol{\epsilon}), \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t (\mathbf{x}_0, \boldsymbol{\epsilon}) - \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon} \right) \right) - \boldsymbol{\mu}_{\boldsymbol{\theta}} (\mathbf{x}_t (\mathbf{x}_0, \boldsymbol{\epsilon}), t) \right\|^2 \right] \\ &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \left[ \frac{1}{2\sigma_t^2} \left\| \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t (\mathbf{x}_0, \boldsymbol{\epsilon}) - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon} \right) - \boldsymbol{\mu}_{\boldsymbol{\theta}} (\mathbf{x}_t (\mathbf{x}_0, \boldsymbol{\epsilon}), t) \right\|^2 \right] \\ &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \left[ \frac{\beta_t^2}{2\sigma_t^2 \alpha_t (1 - \bar{\alpha}_t)} \left\| \boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta \left( \sqrt{\bar{\alpha}_t} \mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon}, t \right) \right\|^2 \right] \end{align}\]第三个等号转换背后的考虑如下:观察第二个等号后的公式,二范数的平方里面,前者与神经网络模型无关可以计算出来,与模型相关的只有后者 \(\boldsymbol{\mu}_{\boldsymbol{\theta}}\) ,换句话说,在给定 \(\mathbf{x}_t\) 的时候需要 \(\boldsymbol{\mu}_{\boldsymbol{\theta}}\) 预测前者 \(\frac{1}{\sqrt{\alpha_t}}(\mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon})\),而且 \(\mathbf{x}_t\) 已经作为模型输入得到,让我们把这个思路写成公式(其中 \(\boldsymbol{\epsilon}_{\boldsymbol{\theta}}\) 是函数逼近器,用于在给定 \(\mathbf{x}_t\) 使预测 \(\boldsymbol{\epsilon}\)):
\[\boldsymbol{\mu}_{\boldsymbol{\theta}}(\mathbf{x}_t, t) = \tilde{\boldsymbol{\mu}}_t \left( \mathbf{x}_t, \frac{1}{\sqrt{\bar{\alpha}_t}} \left( \mathbf{x}_t - \sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{x}_t, t) \right) \right) = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{x}_t, t) \right)\]总之,我们训练模型预测噪声的均值来达到去噪的目的。 (直接预测去噪后的图片效果比较差)
采样
在训练好函数逼近器 \(\boldsymbol{\epsilon}_{\boldsymbol{\theta}}\) 后,我们如何采样 \(\mathrm{x}_{t-1} \sim p_θ(\mathrm{x}_{t-1} | \mathrm{x}_t)\) ?转化为计算:
\[\mathrm{x}_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{x}_t, t) \right) + \sigma_t \mathrm{z}\]通过这个公式完成模型中的反向过程,其中 z 是一个高斯噪声(这里用了重参数化技巧)
完整的采样算法如下:

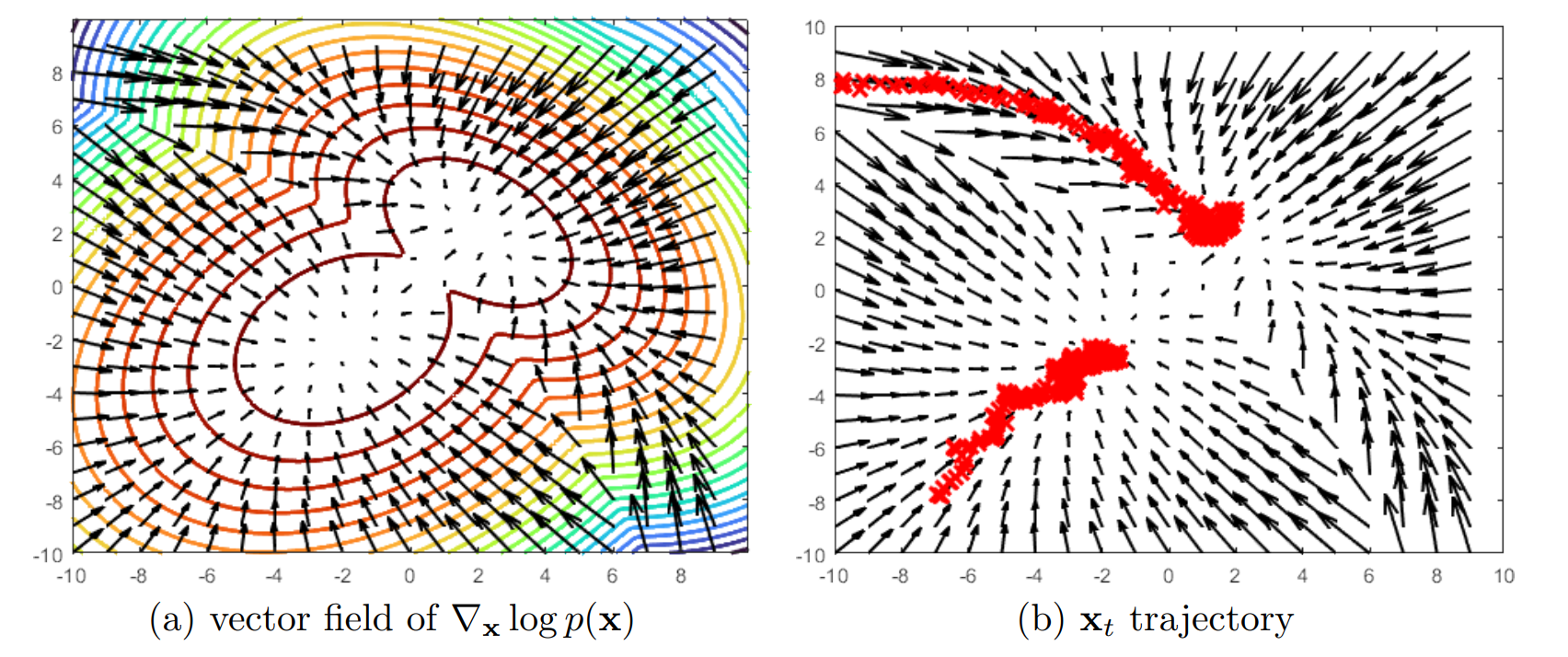
在原论文中,作者说这个采样过程类似 Langevin dynamics(朗之万动力学)。它是起源于物理中的一种用于模拟粒子在复杂环境中随时间演化的数值方法。
在深度学习中,我们可以把它看作一种带噪声的梯度下降,用于在已知参数的已知分布上采样,噪声用来避免坍缩为局部最小值
\[\mathbf{x}_t = \mathbf{x}_{t-1} + \frac{\delta}{2} \nabla_\mathbf{x} \log p(\mathbf{x}_{t-1}) + \sqrt{\delta} \boldsymbol{\epsilon}_t ,\quad\text{where } \boldsymbol{\epsilon}_t \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\]采样过程如下,样本逐渐靠近分布中概率最大的点,但是由于带噪声轨迹会歪歪扭扭:
完整的介绍见 Tutorial on Diffusion Models for Imaging and Vision 第30页起
损失函数
我们简化一下在反向过程中我们得到的损失函数:
\[L_{\text{simple}}(\theta) := \mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}} \left[ \left\| \boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta \left( \sqrt{\bar{\alpha}_t} \mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon}, t \right) \right\|^2 \right]\]其中 t 是均匀分布在 1 和 T 之间的。
- 当 t = 1 时对应于 \(L_0\)
- 当 t > 1 时对应于 \(L_{t-1}\)
- 由于前向过程方差 \(\beta_t\) 固定,所以忽略 \(L_T\)
看到这里可能会疑惑,要怎么去学习一个随机噪声?其实我们给了模型一个经过污染的图片,但是图片的轮廓还是看得出来的,模型的任务是根据它找到一个合适的符合高斯分布的噪声,在去噪后能让图片更清晰一些。
训练

实验
生成图像质量
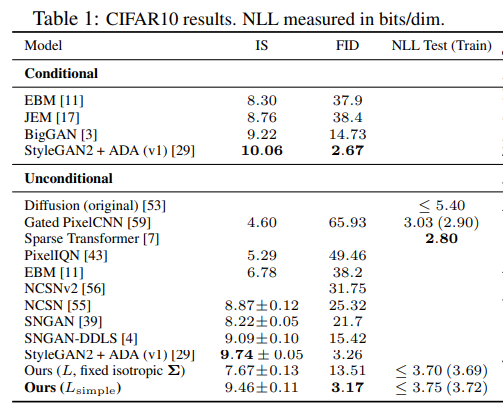
Conditional 和 Unconditional 模型的区别:
- Conditional Model(条件生成模型): 这种模型在生成数据时使用了额外的条件信息。例如,在生成图像时,模型可能会使用标签信息(例如图像类别)作为条件来指导生成过程。这种方法可以生成特定类型的图像,而不是随机的图像。
- Unconditional Model(无条件生成模型): 这种模型在生成数据时不使用任何额外的条件信息。它们仅依赖于输入的随机噪声来生成数据。这意味着生成的图像是完全随机的,没有特定的类别或特征。
三种指标:
- IS(Inception Score)是一种用于评估生成模型生成图像质量的指标。IS 指标越高,表示生成图像的质量和多样性越好。具体通过衡量生成图像的类别分布与真实类别分布的KL散度来评估生成图像的多样性和质量。
- FID(Frechet Inception Distance)是一种用于评估生成模型生成图像质量的指标。FID 指标越低,表示生成图像与真实图像的质量和多样性越相似,生成效果越好。它通过比较生成图像与真实图像的特征分布来进行评估。
- NLL(Negative Log-Likelihood,负对数似然)是一种用于评估生成模型的指标。它表示模型在测试数据上的对数似然的负值。具体而言,NLL 衡量的是模型生成测试数据的概率,NLL 越低,表示模型生成测试数据的概率越高,即模型的生成效果越好。通常以 bits/dim(每维度比特数)为单位表示,即模型每维度(每个数据点的每个元素)所需的平均比特数来编码数据
压缩效果
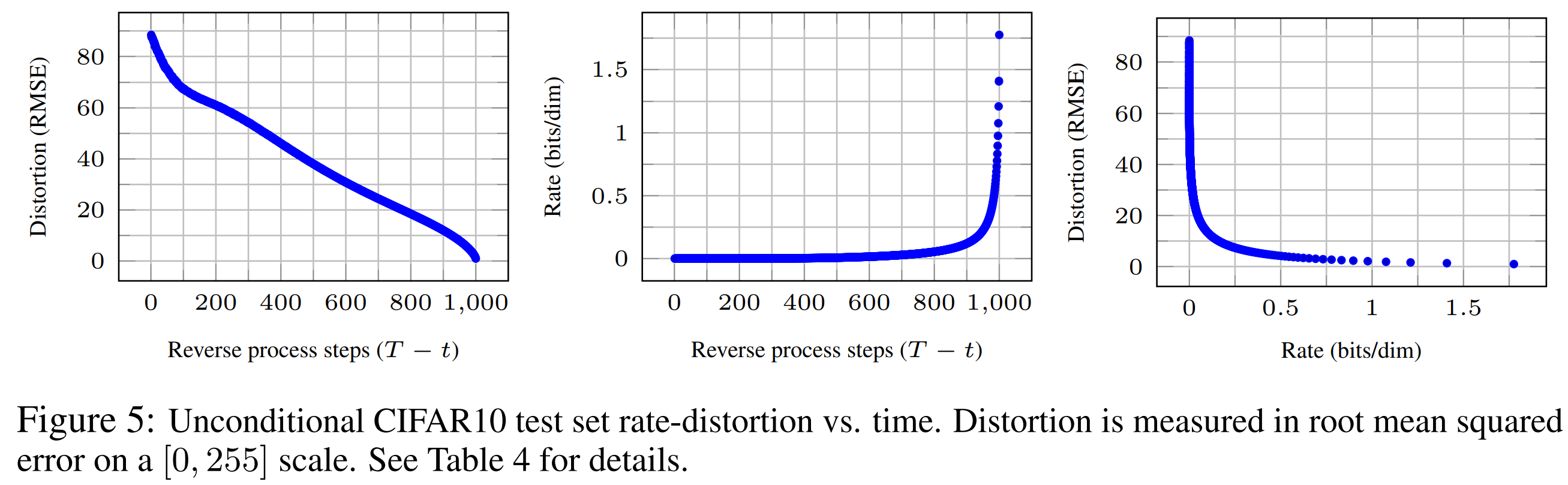
扩散模型可以看作出色的有损压缩器。将变分界限项 \(L_1 + ... + L_T\) 视为压缩率,将 \(L_0\) 视为失真率,我们的CIFAR10模型在最高质量样本下的压缩率为1.78 bits/dim,失真度为1.97 bits/dim,这相当于在0到255的刻度上,均方根误差为0.95。
如果我们一步一步计算压缩率和失真率,它们的关系如下。压缩率变大,失真率变大。
生成过程
如果我们从纯噪声开始一步一步降噪,效果如下:

我们可以在找到图像空间的中点:
- 计算两张照片前向过程后形成的噪声图片。
- 计算这两张噪声图片的均值。
- 再进行去噪。

如果我们控制这两张原图片前向加噪的步数,我们可以发现:
- 加噪少,模型可以很好地还原图像
- 加噪多,模型逐渐丢失原图像

参数设置与实验细节
我们的神经网络架构遵循 PixelCNN++ 的骨干网络,这是一种基于 Wide ResNet 的 U-Net 架构。我们将权重归一化替换为组归一化,以简化实现。我们的 32 × 32 模型使用四个特征图分辨率(32 × 32 到 4 × 4),而 256 × 256 的模型使用六个。
所有模型在每个分辨率级别中都有两个卷积残差块,在卷积块之间的 16 × 16 分辨率处添加了自注意块。扩散时间 t 的指定方式是通过将 Transformer 正弦位置嵌入到每个残差块中。
我们的 CIFAR10 模型有 35.7 百万个参数,LSUN 和 CelebA-HQ 模型有 1.14 亿个参数。我们还通过增加滤波计数训练了 LSUN Bedroom 的较大变体模型,拥有大约 2.56 亿个参数。
我们使用 TPU v3-8(类似于 8 个 V100 GPU)进行所有实验。我们的 CIFAR 模型以每秒 21 步的速度训练,批量大小为 128(训练 80 万步需 10.6 小时),并在批量大小为 256 的情况下抽样 256 张图像需要 17 秒。我们的 CelebA-HQ/LSUN(256²)模型以每秒 2.2 步的速度训练,批量大小为 64,抽样 128 张图像需要 300 秒。我们训练了 CelebA-HQ 50 万步,LSUN Bedroom 240 万步,LSUN Cat 180 万步,LSUN Church 120 万步。更大的 LSUN Bedroom 模型训练了 115 万步。
除了在早期选择超参数以使网络尺寸适合内存限制外,我们在主要的超参数搜索中优化了 CIFAR10 样本质量,然后将结果设置转移到其他数据集:
- 我们从一组恒定、线性和二次的 \(\beta_t\) 计划中选择,并约束 \(\mathcal{L}_T \approx 0\)。我们设置了 T = 1000 且不进行搜索,正向过程方差为常数,并选择了一个从 \(\beta_1 = 10^{-4}\) 到 \(\beta_T = 0.02\) 的线性计划。同时保持信号噪声比尽可能小,\(D_{\mathrm{KL}}\left(q(\mathbf{x}_T | \mathbf{x}_0) \| \mathcal{N}(0, \mathrm{I}) \right) \approx 10^{-5}\) 位/维
- 我们通过在 \(\{0.1, 0.2, 0.3, 0.4\}\) 值上进行搜索,将 CIFAR10 的 dropout 率设置为 0.1。未在 CIFAR10 上使用 dropout 时,我们获得了质量较差的样本,类似于未正则化的 PixelCNN++ 过拟合。我们在所有数据集上将 dropout 率设置为零而不进行搜索。
- 在 CIFAR10 的训练过程中,我们使用了随机水平翻转;我们尝试在有翻转和无翻转的情况下进行训练,发现翻转略微改善了样本质量。我们还在所有数据集上使用了随机水平翻转,但 LSUN Bedroom 除外。
- 在实验阶段,我们早期尝试了 Adam 和 RMSProp,并选择了前者。我们将超参数保持在标准值。我们将学习率设置为 \(2 × 10^{-4}\),没有进行搜索,并在 256 × 256 图像上将其降低到 \(2 × 10^{-5}\),发现随着较大的学习率稳定性较差。
- 我们将CIFAR10的批量大小设置为128,将更大图像的批量大小设置为64。我们没有对这些值进行调参。
- 我们对模型参数使用了EMA(指数移动平均),衰减因子为0.9999。我们没有对这个值进行调参。