BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
读论文时间!
参考:
1、标题解释
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- pre-training: 在一个大的数据集上训练好一个模型 pre-training,模型的主要任务是用在其它任务 training 上。
- deep bidirectional transformers: 深的双向 transformers
- language understanding: 更广义,transformer 主要用在机器翻译 MT
BERT: 用深的、双向的、transformer 来做预训练,用来做语言理解的任务。 于 BERT 的目标是生成语言模型,因此只需要编码器机制。
2、相关工作
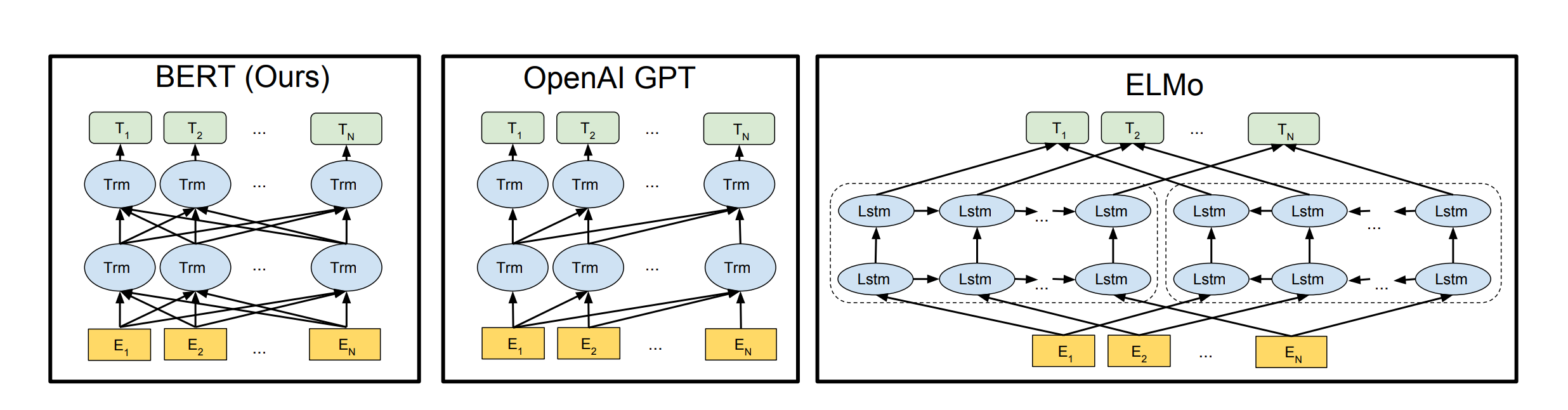
基于特征的 ELMo ,构建和每一个下游任务相关的 NN 架构,将训练好的特征作为额外的特征 和 输入 一起放进模型。
基于微调参数的 GPT,所有的权重参数根据新的数据集进行微调。
- GPT unidirectional,使用左边的上下文信息预测未来。BERT bidirectional,使用左右侧的上下文信息。GPT 从左到右的架构,只能将输入的一个句子从左看到右。句子情感分类任务:从左看到右、从右看到左 都应该是合法的。 整个句子对被放在一起输入 BERT,self-attention 能够在两个句子之间相互看。BERT 更好,但代价是 不能像 transformer 做机器翻译。
- ELMo based on RNNs, down-stream 任务需要调整一点点架构。BERT based on Transformers, down-stream 任务只需要调整最上层。GPT, down-stream 任务 只需要改最上层。
- transformer 预训练时候的输入是一个序列对。编码器和解码器分别会输入一个序列。BERT 只有一个编码器,为了使 BERT 能处理两个句子的情况,需要把两个句子并成一个序列。
与 ELMo 和 GPT 不同,BERT 从无标注的文本中联合左右的上下文信息预训练得到无标注文本的 deep bidirectional representations
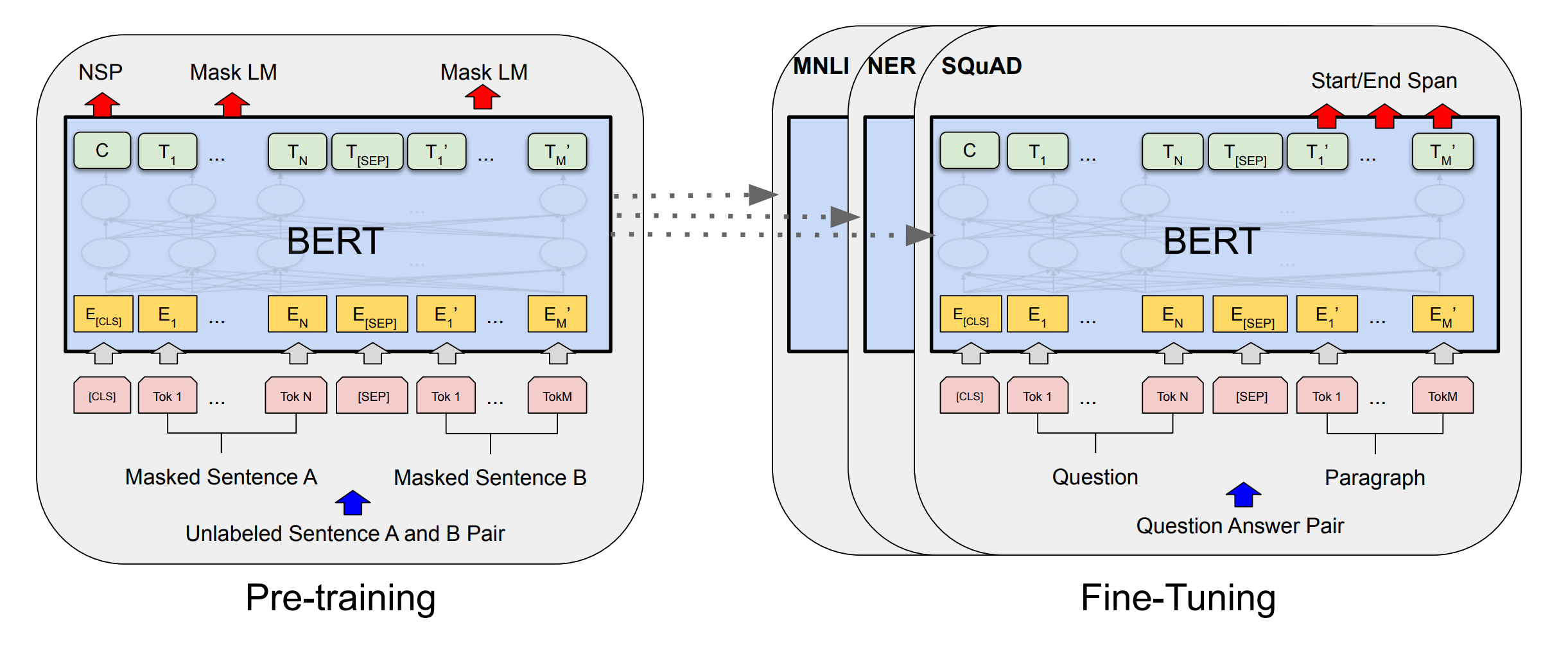
pre-trained BERT 可以通过加一个输出层来 fine-tune(微调),在很多任务(问答、推理)有 SOTA 效果,而不需要对特定任务的做架构上的修改。
3、模型
BERT 包括两步:预训练 + 微调。预训练和微调不是 BERT 的创新,CV里用的比较多。
- pre-training: 使用 unlabeled data 训练
- fine-tuning: 微调的 BERT 使用 预训练的参数 初始化,所有的权重参数通过 下游任务的 labeled data 进行微调。
每一个下游任务会创建一个 新的 BERT 模型,(由预训练参数初始化),但每一个下游任务会根据自己任务的 labeled data 来微调自己的 BERT 模型。
3.1、multi-layer bidirectional Transformer encoder
一个多层双向 Transformer 的解码器,基于 transfomer 的论文和代码。
模型调了 3 个参数:
- L: transform blocks的个数
- H: hidden size 隐藏层大小
- A: 自注意力机制 multi-head 中 head 头的个数
BERT_BASE模型1亿参数(和 GPT 差不多),L=12,H=768,A=12。BERT_LARGE模型3.4亿参数,L=24,H=1024,A=16。
3.2、估计参数个数
模型包含嵌入层和Transformer 块
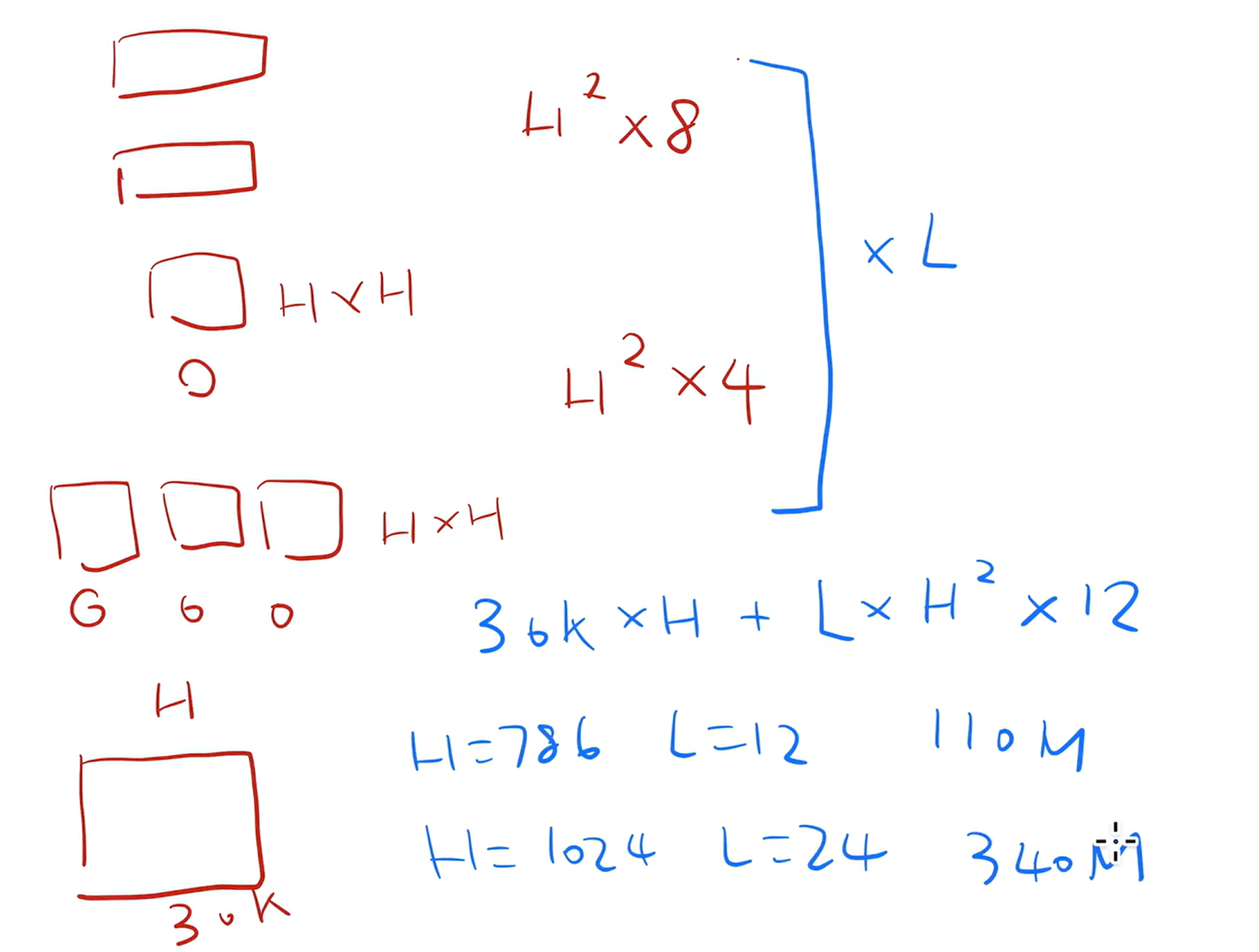
- 嵌入层: 输入是词的字典大小 30k,输出是 H。嵌入层的输出会进入 transformer 块。
- transformer blocks 的 self-attention mechanism 本身无可学习参数; multi-head self-attention mechanism 要对 Q、K、V 做投影,一共$H^2 \times 4$
- MLP 的 2个全连接层:第一个全连接层输入是 H,输出是 4 * H;第二个全连接层输入是 4 * H,输出是 H。一共$H^2 \times 8$
一共$30k \times H + L \times H^2 \times 12$
3.3、Input/Output Representations
下游任务有处理一个句子或者处理 2 个句子,BERT 需要能处理不同句子数量的下游任务。
a single sentence: 一段连续的文字,不一定是真正上的语义上的一段句子,它是我的输入叫做一个序列 sequence。A “sequence” 序列可以是一个句子,也可以是两个句子。
存在一个问题,如果数据量大的时候,词典会特别大,到百万级别。可学习的参数基本都在嵌入层了。因此使用WordPiece, 把一个出现概率低的词切开,只保留一个词出现频率高的子序列,30k token 经常出现的词(子序列)的字典。 例如reckless = reck + ##less
序列开始使用: [ CLS ] 标记。
区分两个合在一起的句子 的方法:每个句子后 + [ SEP ] 表示 seperate。例子是:[ CLS ] [Token1] …… [Token n] [SEP] [Token1'] …… [Token m]
每一个 token 进入 BERT 得到 这个 token 的embedding 表示。对于 BERT,输入一个序列,输出一个序列。最后一个 transformer 块的输出,表示 这个词源 token 的 BERT 的表示。在后面再添加额外的输出层,来得到想要的结果。
3.4、BERT 嵌入层
一个词源的序列 –> 一个向量的序列 –> 进入 transformer 块
- Token embeddings: 词源的embedding层,整成的embedding层, 每一个 token 有对应的词向量。
- Segement embeddings: 这个 token 属于第一句话 A还是第二句话 B。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。
- Position embeddings: 输入是 token 词源在这个序列 sequence 中的位置信息。从0开始 1 2 3 4 –> 1024
BERT input representation = token embeddings + segment embeddings + position embeddings
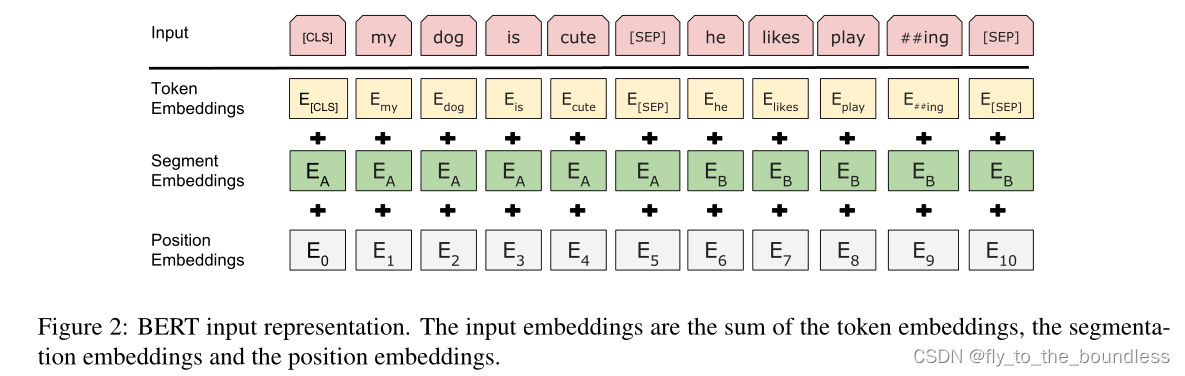
BERT 的 segment embedding (属于哪个句子)和 position embedding (位置在哪里)是学习得来的,transformer 的 position embedding 是给定的。
4、预训练
4.1、Masked LM
预训练要做的一个任务是遮盖部分输入的词,预测这些词。
由 WordPiece 生成的词源序列中的词源,它有 15% 的概率会随机替换成一个掩码。但是对于特殊的词源( 例如[ CLS ] 和 [SEP])不做替换。,该模型尝试根据序列中其他非掩码单词提供的上下文来预测掩码单词的原始值。具体来讲,输出词的预测需要:
- 在编码器输出之上添加一个分类层。
- 将输出向量乘以嵌入矩阵,将它们转换为词汇维度。
- 用 softmax 计算词汇表中每个单词的概率。
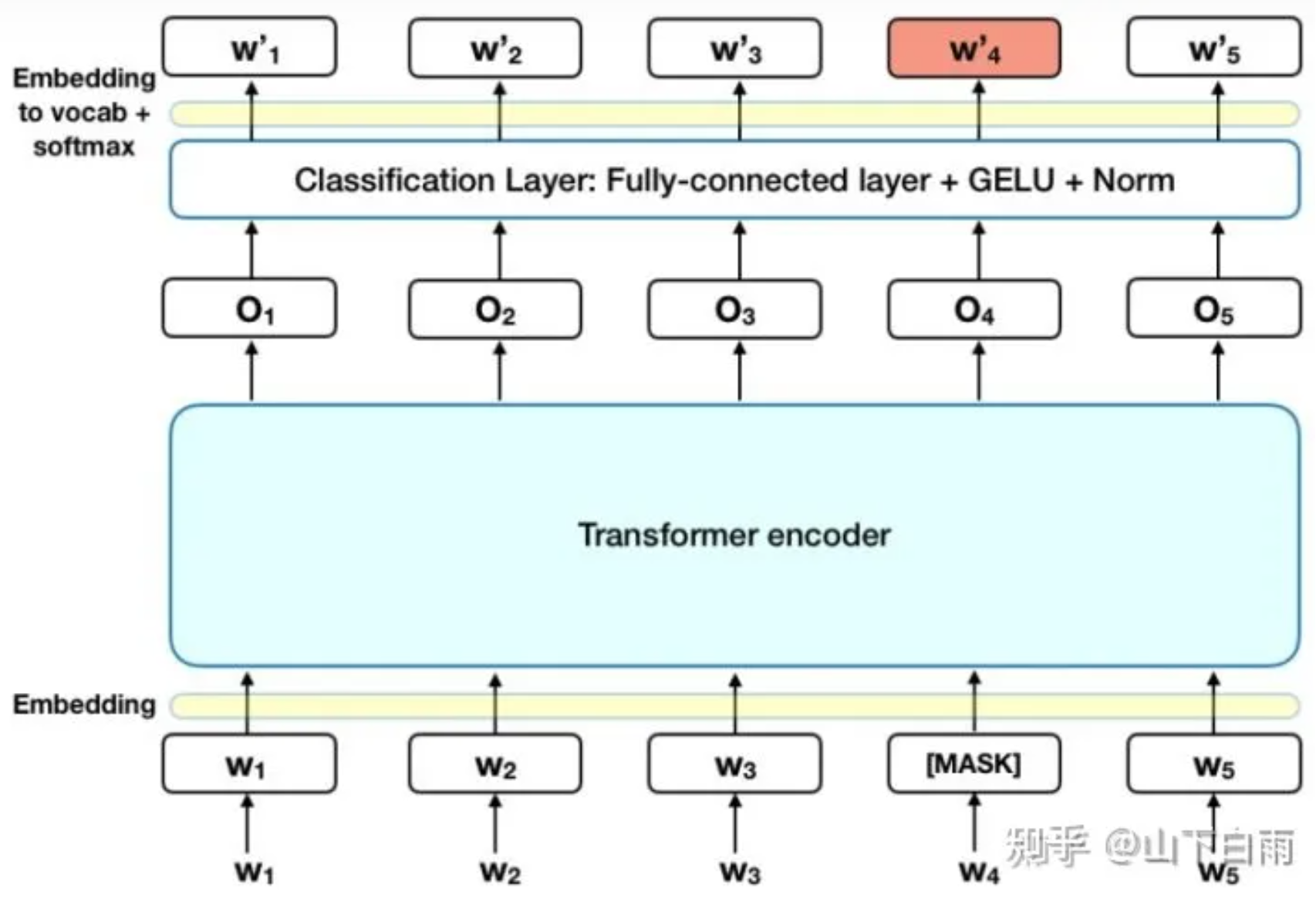
MLM 带来的问题:预训练和微调看到的数据不一样。预训练的输入序列有 15% [MASK],微调时的数据没有 [MASK].
15% 计划被 masked 的词: 80% 的概率被替换为 [MASK], 10% 换成 random token,10% 不改变原 token。但还是被用来做预测。
这么做的原因是如果句子中的某个Token100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’hairy‘。至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。
另外文章指出每次只预测15%的单词,因此模型收敛的比较慢。
例子:
- 80% of the time: my dog is hairy → my dog is [MASK]
- 10% of the time: my dog is hairy → my dog is apple
- 10% of the time: my dog is hairy → my dog is hairy.
4.2、NSP Next Sentence Prediction
第二个预训练任务是判断两个句子是否处于同一篇文章,具体来说是否是前后关系。
输入序列有 2 个句子 A 和 B,50% 正例,50%反例。50% B 在 A 之后,50% 是 a random sentence 随机采样的。
为了预测第二个句子是否确实与第一个句子相关,执行以下步骤:
- 整个输入序列通过 Transformer 模型。
- 使用简单的分类层(权重和偏差的学习矩阵)将 [CLS] 标记的输出转换为 2×1 形状的向量。
- 用 softmax 计算 IsNextSequence 的概率。
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 一起训练,目标是最小化这两种策略的组合损失函数。
例子:
- Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] Label = IsNext
- Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] Label = NotNext
flight ## less, flightless 出现概率不高,WordPiece 分成了 2 个出现频率高的子序列,## 表示 less 是 flightless 的一部分。
4.3、Pre-training data
2 个数据集:BooksCorpus (800 M) + English Wikipedia (2500 M)
使用一篇一篇文章,而不是随机打断的句子。 a document-level corpus rather than a shuffled sentence-level corpus
transformer 可以处理较长的序列,一整个文本的输入,效果会好一些。
5、微调
BERT 可用于多种语言任务,仅需在核心模型中添加一小层:
- 情感分析等分类任务与 Next Sentence 分类类似,方法是在 [CLS] 令牌的 Transformer 输出之上添加一个分类层。
- 在问答任务(例如 SQuAD v1.1)中,当需要接收与文本序列的问题,并且需要在序列中标记答案。使用 BERT,可以通过学习两个标记答案开始和结束的额外向量来训练问答模型。
- 在命名实体识别 (NER) 中,接收文本序列并需要标记文本中出现的各种类型的实体(人、组织、日期等)。使用 BERT,可以通过将每个标记的输出向量输入到预测 NER 标签的分类层来训练 NER 模型。
在微调训练中,大多数超参数与 BERT 训练中保持一致,论文对需要调优的超参数给出了具体指导。
要点:
- 模型大小很重要。BERT_large 拥有 3.45 亿个参数,是同类模型中最大的。它在小规模任务上明显优于 BERT_base,BERT_base 使用相同的架构,“只有”1.1 亿个参数。
- 足够的训练数据,更多的训练步骤 == 更高的准确度。例如,在 MNLI 任务上,与具有相同批量大小的 500K 步训练相比,在 1M 步(128,000 字批量大小)上训练时,BERT_base 准确度提高了 1.0%。
- BERT 的双向方法 (MLM) 的收敛速度比从左到右的方法要慢(因为每批中仅预测 15% 的单词),但经过少量预训练步骤后,双向训练的性能仍然优于从左到右的训练。
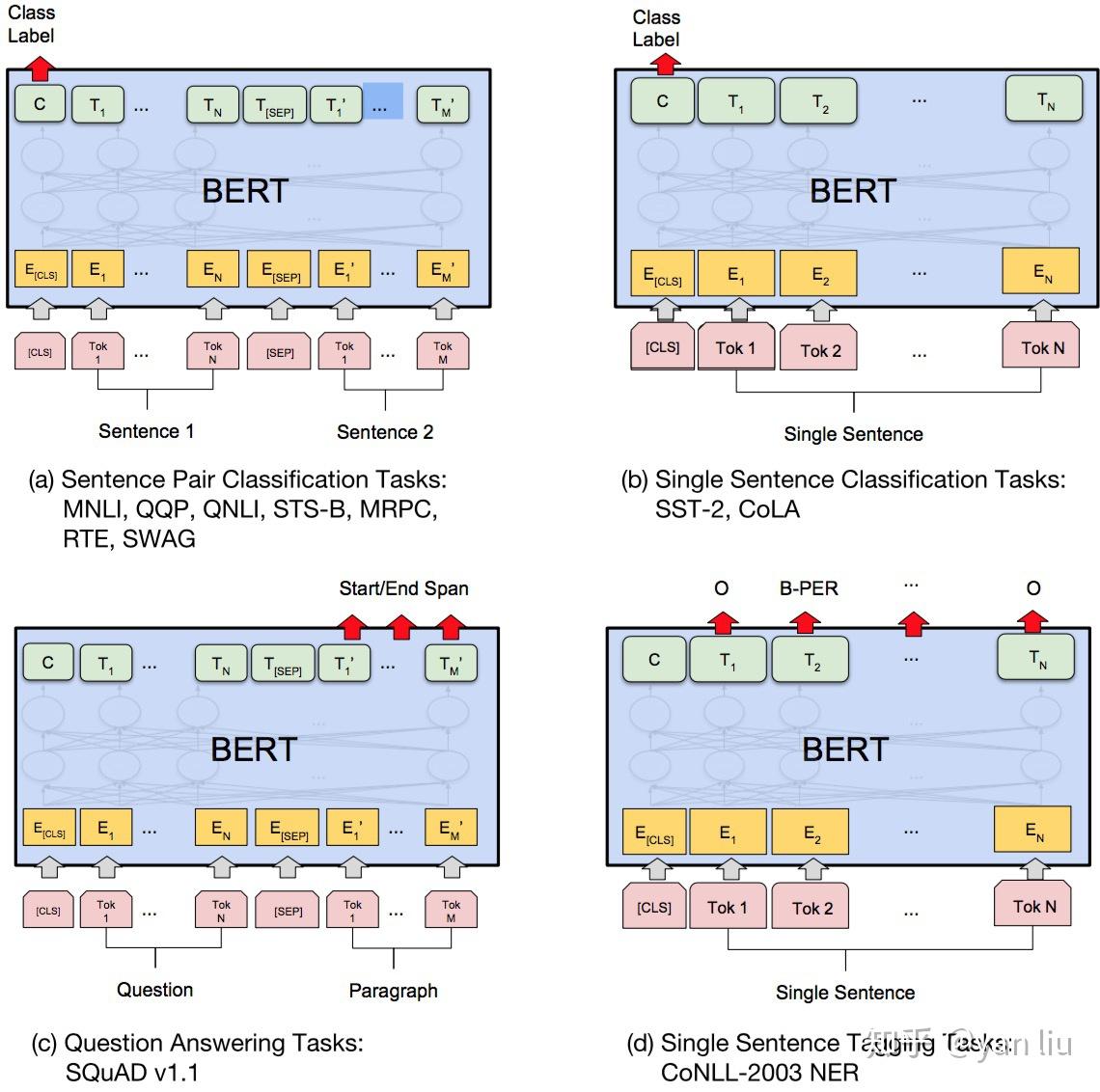
微调的任务包括
(a)基于句子对的分类任务:
- MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,我们需要做的是去发掘前提和假设这两个句子对之间的交互信息。
- QQP:基于Quora,判断 Quora 上的两个问题句是否表示的是一样的意思。
- QNLI:用于判断文本是否包含问题的答案,类似于我们做阅读理解定位问题所在的段落。
- STS-B:预测两个句子的相似性,包括5个级别。
- MRPC:也是判断两个句子是否是等价的。
- RTE:类似于MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。
- SWAG:从四个句子中选择为可能为前句下文的那个。
(b)基于单个句子的分类任务
- SST-2:电影评价的情感分析。
- CoLA:句子语义判断,是否是可接受的(Acceptable)。
5.1、GLUE
对于GLUE分类任务,将 [CLS] 的 BERT 输出表示 + 一个输出层 W,softmax 分类得到 label,公式为
\[log(\text{softmax}(CW^T)\]其中 C 是BERT输出中的[CLS]符号, W 是可学习的权值矩阵。
5.2、SQuAD
QA 问答:给一段文字,问一个问题,问题的答案就在给的文字里面。本质的任务就是摘录答案,即对每个词源 token,判断是不是答案的开始or结尾。
具体学 2 个向量 S 和 E,分别对应这个词源 token 是答案开始词的概率 和 是答案结尾词的概率。