Aggregated Residual Transformations for Deep Neural Networks
读论文时间!
计算机视觉模型:ResNeXt
参考:
- 前置知识:ResNet
- 吴恩达《深度学习》课程
前情提要
ResNeXt,简单来说是ResNet与Inception网络的优化,先简单复习一下ResNet与Inception网络。
ResNet
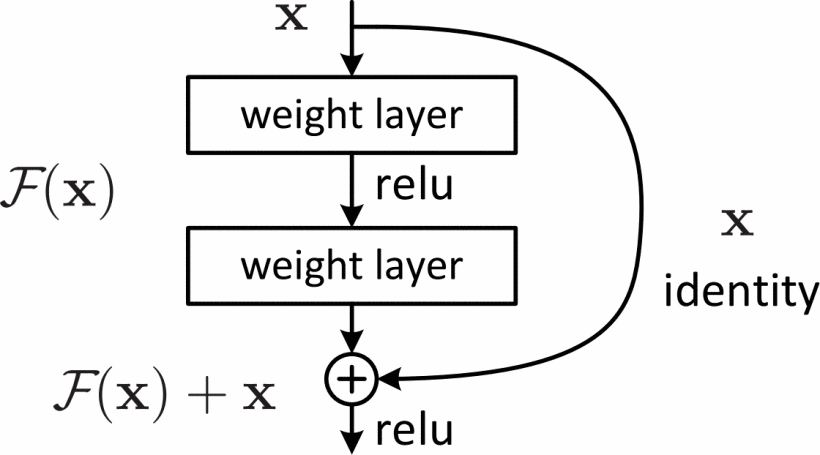
这是一个基本模块,ResNet由这种基本模块堆叠构成。这种基本模块可以用数学公式概括为:
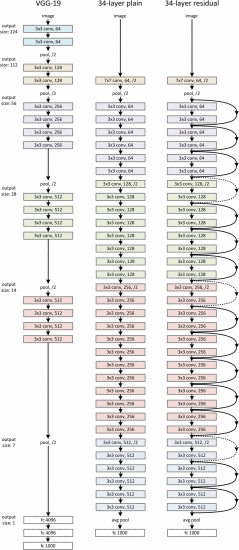
\[\text{y}=\mathcal{F}(\text{x},\{W_i\})+\text{x}\]下图分别是VGG-19,朴素网络与残差网络的对比。
Inception网络
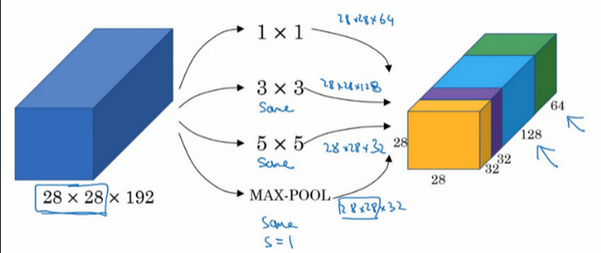
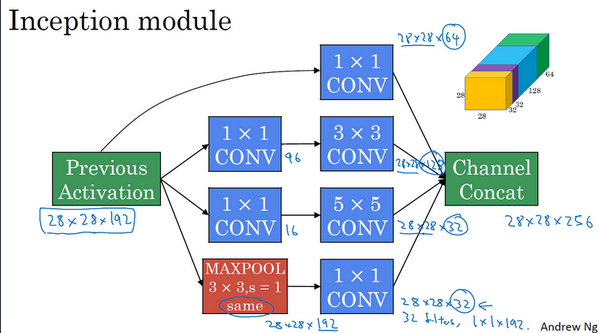
构建卷积层时,要决定过滤器的大小究竟是1×1,3×3还是5×5,或者要不要添加池化层。而Inception网络保留所有的过滤器和池化层输出,并把输出堆叠到一起。一个典型的Inception模块如下图。
一个具体的Inception模组例子:
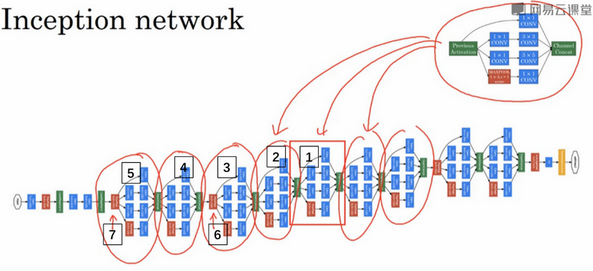
一个Inception网络例子:
继承与超越
ResNeXt,同时使用了ResNet与Inception网络的思想,让我们具体看看。
简单来说,ResNeXt使用了VGG/ResNets重复基本模块的思想,也使用了Inception网络split-transform-merge的思想。
repeating layers
什么叫做strategy of repeating layers?
VGG-nets与ResNets使用了一种构建深层网络的简单但是高效的策略:堆叠相同形状的基本模块。
split-transform-merge
什么叫做split-transform-merge的思想?
我们举一个最简单的例子:神经网络中的单个“神经”,示例图片如下:
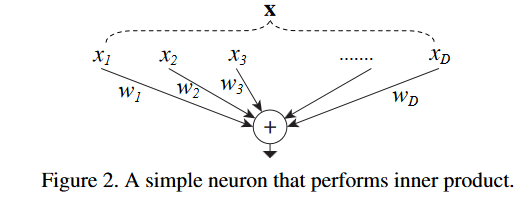
即,给定一个含有 $D$ 个元素的输入数据 $\text{x}=[x_1,x_2,\dots,x_d]$ ,权为 $w1,w_2,…,w_D$ ,一个没有偏置的线性激活神经元为:
\[\sum^D_{i=1}w_ix_i\]这是一个最简单的“split-transform-merge”结构,可以拆分成3步:
- Split:将数据 $\text{x}$ 分割成 $D$ 个子空间(特征)。
- Transform:每个特征经过一个线性变换。即$w_ix_i$。
- Merge:通过单位加合成最后的输出。
超越
为什么说ResNeXt更好?主要两个原因:
- 在与相同参数量的ResNet做比较时,ResNeXt性能更好。
- Inception 需要人工设计每个分支,ResNeXt的分支的拓扑结构是相同的,更简单。
主角登场
终于到ResNeXt本体出场了,它与ResNet的最主要区别就是基本模块不同,两种基本模块对比如下。
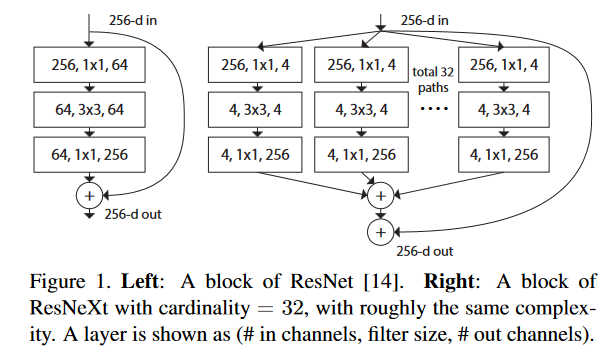
完整网络模型对比如下:
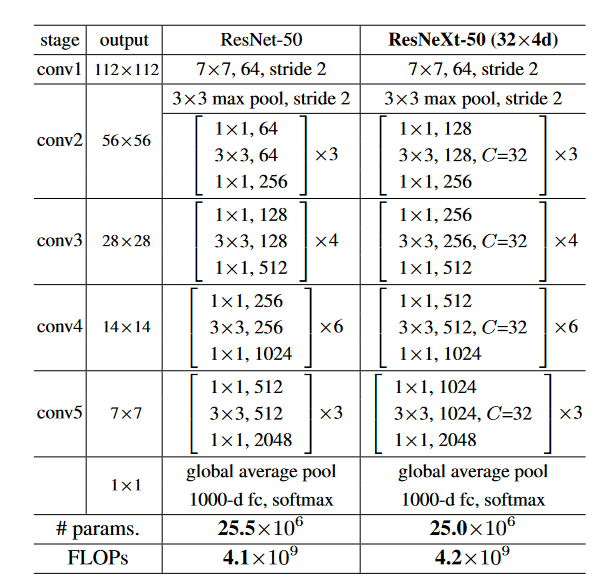
可以看到ResNeXt与ResNet非常像。
代码分析
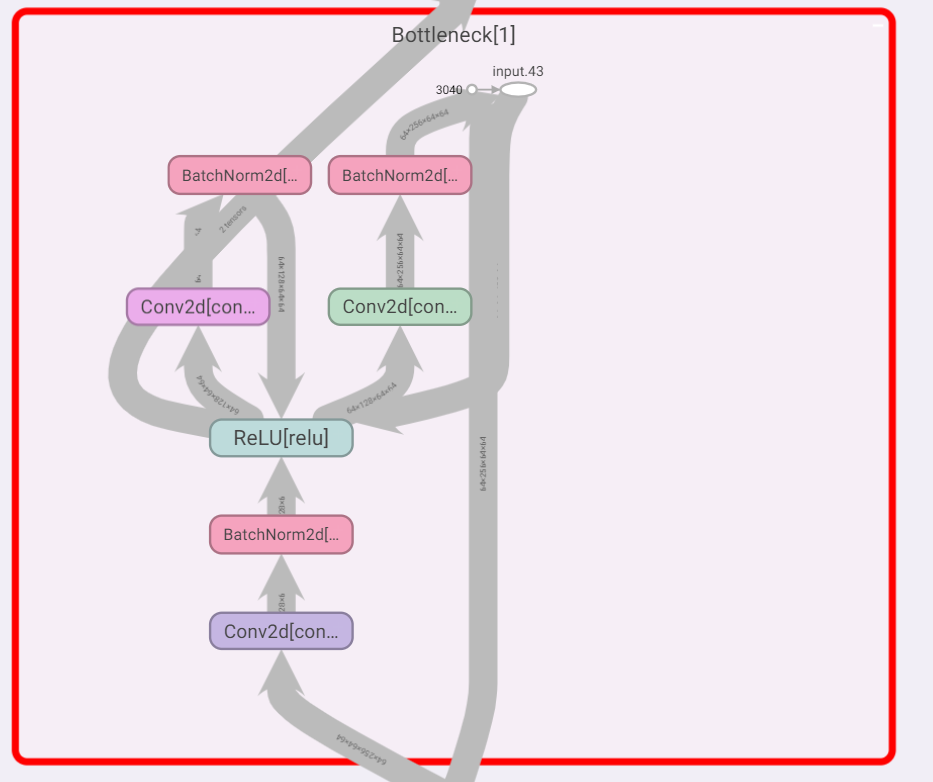
在torchvision的实现中,ResNeXt与ResNet的代码被放在了一起,具体来说,它们共用了类Bottleneck作为基本模块的一种实现方式。(ResNet还有一种简单的基本模块,类Basicblock)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
如果我们使用ResNet,那么groups=1,base_width=64就是使用默认值,如果使用ResNeXt,参数groups,base_width是手动指定的:
1
2
3
4
5
def resnext50_32x4d(pretrained=False, progress=True, **kwargs):
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
对于resnext50_32x4d,groups=32,base_width=4。
我们说过,ResNeXt与ResNet共用了类Bottleneck作为基本模块的一种实现方式,那它们在代码中是怎么区别的呢?重要的代码是:
1
width = int(planes * (base_width / 64.)) * groups
- 如果是ResNet,假设
planes=64,width=64*64/64*1=64 - 如果是ResNeXt50_32x4d,假设
planes=64,width=64*4/64*32=128
这与我们的网络模型对应:

简单print模型的Bottleneck:
1
2
3
4
5
6
7
8
9
(1): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
tensorboard的Bottleneck: