Adversarial Incomplete Multi-view Clustering
读论文时间!
多模态模型:AIMC
一、聚类模块的对齐
多模态对齐是指找到两种或多种模态的instances中sub-components之间的对应关系,例如:给定一张图片和一个描述,找到词或者短语对应图片中的区域;另一个例子是给定一个电影,将它和字幕或者书中的章节对齐。
多模态对齐分成两类:隐式对齐和显示对齐
- 显示对齐显示的关注模态间sub-components的对应关系,例如将视频和菜谱中对应的步骤对齐
- 隐式对齐常作为其它任务的一个环节,例如基于文本的图像搜索中,将关键词和图片的区域进行对齐
显示对齐
sub-components间的相似性衡量是显示对齐的基础,两类算法:无监督方法和(弱)监督方法
无监督方法:无监督方法不需要模态间对齐的标注,Dynamic time warping衡量两个序列的相似性,找到一个optimal的match,是一种dynamic programming的方法。由于DTW需要预定义的相似性度量,可以利用CCA(典型相关性分析)将模态映射到一个协同表达空间。DTW和CCA都是线性变换,不能找到模态间的非线性关系。图模型也可以用于无监督多模态序列的对齐。
DTW和图模型的方法用于多模态对齐需要遵循一些限制条件,例如时序一致性、时间上没有很大的跳跃、单调性。DTW能够同时学习相似性度量和模态对齐,图模型方法在建模过程中需要专家知识。
(弱)监督方法:监督方法需要标注好的模态对齐实例,用于训练模态对齐中的相似性度量,许多监督式序列对齐方法收到非监督方法的启发,当前深度学习方法用于模态对齐更加常见。
隐式对齐(本论文用到)
常用作其它任务的中间步骤,使得例如语音识别、机器翻译、多媒体描述和视觉问答达到更好的性能。早期工作基于图模型,当前更多基于神经网络。
图模型:需要人工构建模态间的映射关系
神经网络:模态转换如果能够使用模态对齐,任务的性能可以得到提升
单纯的使用encoder只能通过调整权重来总结整张图片、句子、视频,作为单一的向量表示;注意力机制的引入,使得decoder能够关注到sub-components。注意力机制会让decoder更多的关注sub-components
注意力机制可以认为是深度学习模态对齐的一种惯用方法。
二、论文简介
AIMC是对于多视图聚类传统方法IMC的改进,多了一个A(生成对抗网络),多了一个对齐聚类损失。
在深度学习中,聚类是一种无监督学习任务,它旨在将数据集中的样本分成不同的群组或簇,使得同一个簇内的样本相似性较高,而不同簇之间的相似性较低。聚类任务的目标是发现数据中的内在结构和模式,并将相似的样本归为一类,从而实现数据的自动分类。
聚类算法通过计算样本之间的相似度或距离来进行聚类,常见的算法包括k-means、层次聚类、DBSCAN等。这些算法使用不同的策略和准则来确定样本之间的相似性,并根据相似性将其分组。
聚类在许多领域都有应用,例如市场分析、图像处理、社交网络分析等。它可以帮助我们了解数据集的特点、发现异常数据、降维数据复杂性、构建推荐系统等。
多视图聚类的目的是利用来自多个视图的信息来提升聚类效果。以前的大多数研究都假设每个视图都有完整的数据。然而,在真实数据集中,视图可能包含一些缺失的数据,导致不完整的多视图聚类问题。
以往解决这一问题的方法至少有以下缺点之一:
- 采用浅层模型,不能很好地处理不同视图之间的依赖性和差异;
- 忽略了缺失数据所包含的隐藏信息;
- 专门用于双视图的情况。
为了消除所有这些缺点,本文提出了一种对抗的不完全多视图聚类(AIMC)方法。与大多数现有的方法只使用现有的视图学习新的表示方式不同,AIMC寻求多视图数据的公共潜在空间,并同时执行缺失的数据推断。具体来说,提出的模型集成了元素重构和生成对抗网络(GAN)来推断缺失的数据。它们的目标是分别捕获数据的整体结构和获得更深层次的语义理解。此外,还设计了一个对齐的聚类损失,以获得更好的聚类结构。
使用了BDGP数据集(Berkeley Drosophila Genome Project dataset)是一个广泛应用于果蝇(Drosophila melanogaster)基因组研究的数据集。该数据集由加州大学伯克利分校Drosophila Genome Project团队创建,包含了果蝇的基因组序列、基因注释信息以及其他相关的生物学实验数据。
BDGP包含5类共2500个果蝇胚胎实例。我们使用1000D侧视向量、500D背视向量和79D纹理特征向量作为三视图。我们在实验中使用了所有的实例。
三、数据及符号的表示
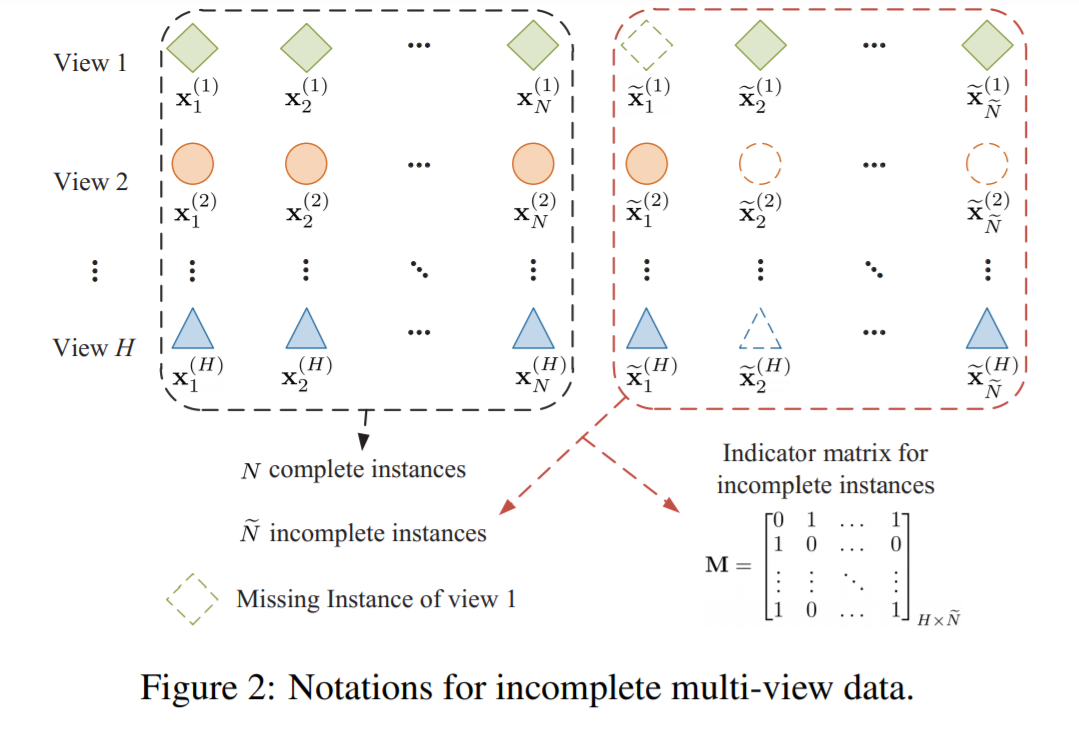
- 我们有$N$个完整的例子(完整指所有的view都具备)
- $\hat{N}$个不完整的例子
- $H$个view

四、模型
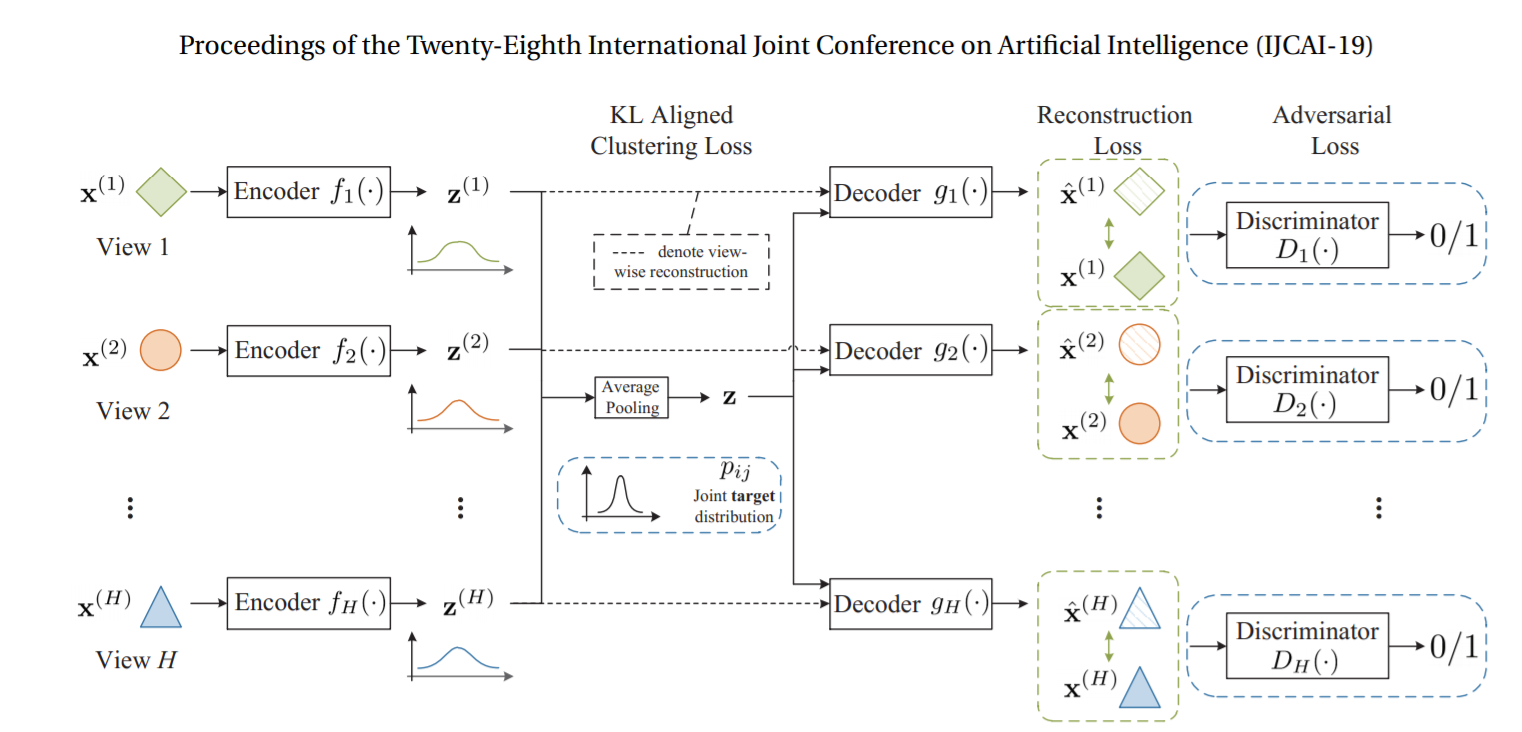
编码器和解码器
- 对于视图$v$,编码器$f_v$专门用于学习$v$到对齐子空间$\text{z}^{(v)}$的映射,所有的$\text{z}^{(v)}$维度相同,即$\text{z}^{(v)} \in R^c$。
- 使用average pooling来得到每个样本的公共表示$\text{z}$。后续在重构$\text{x}^{(v)}$时,同时使用$\text{z}^{(v)}$和$\text{z}$。
灵感来源:
- 使每个$\text{z}^{(v)}$和$\text{z}$相似,或者最小化它们的距离,可以让它们具有互补的高层特征。
- 如果某一个视图$v$丢失或不完整,也可以从$\text{z}$推测。
训练的目的之一是让decoder成为一个优秀的丢失信息的生成器。

损失函数
联合损失主要由三个损失构成:
- 重建损失(Reconstruction loss) $\mathcal{L_R}$
- 对抗损失(Adversarial loss) $\mathcal{L_A}$,多视图重建的问题是在对抗性的设置中建模的,以学习条件分布。
- KL散度聚类模块的对齐(KL Aligned Clustering Loss) $\mathcal{L_D}$,拉近每个视图分布和目标分布之间的KL散度,从而增强不同视图之间的公共潜在表示。
