JSAI Competition2023-sophgo

赛题
可以看作是 Kaggle 比赛的一个复刻
算能杯——面向Stable Diffusion的图像提示语优化专项赛的目标为创建一个模型来预测给定生成图像的文本提示。参赛选手将在包含Stable Diffusion 2.0生成的各种(提示、图像)对的数据集上进行预测,通过了解潜在存在的提示、图像之间关系的可逆性。参赛选手通过构建一个模型来预测给定生成图像的文本提示。并把这个文本提示与标注过的文本提示进行对比。
提示工程(Prompt Engineering)是一种针对预训练语言模型(如ChatGPT),通过设计、实验和优化输入提示来引导模型生成高质量,准确和有针对性的输出的技术。由此产生的提示学习是一种通过构建合适的输入提示来解决特定任务的方法。本赛题就是通过构建数据模型来研究如何提升提示工程的效果。
文本到图像模型的流行已经是基于提示工程的一个人工智能全新领域。用户体验的一部分是艺术,一部分是充满不确定性的数据科学,机器学习工程师正在迅速努力理解提示和它们生成的图像之间的关系。在提示中添加“4k”是使其更具照片感的最佳方式吗?提示中的微小扰动是否会导致图像高度发散?提示关键字的顺序如何影响生成的场景?这项竞赛的任务是创建一个模型,该模型可以可靠地反转生成给定图像的扩散过程。
本赛题任务是预测用于生成目标图像的提示。这个挑战的提示是使用各种(未公开)方法生成的,从简单到复杂,都有多个对象和修饰符。使用Stable Diffusion 2.0(768-v-ema.ckpt)根据提示生成图像,并以768x768像素的50步生成图像,然后将竞争数据集的图像缩小到512x512。使用了此脚本,参见参考代码库。
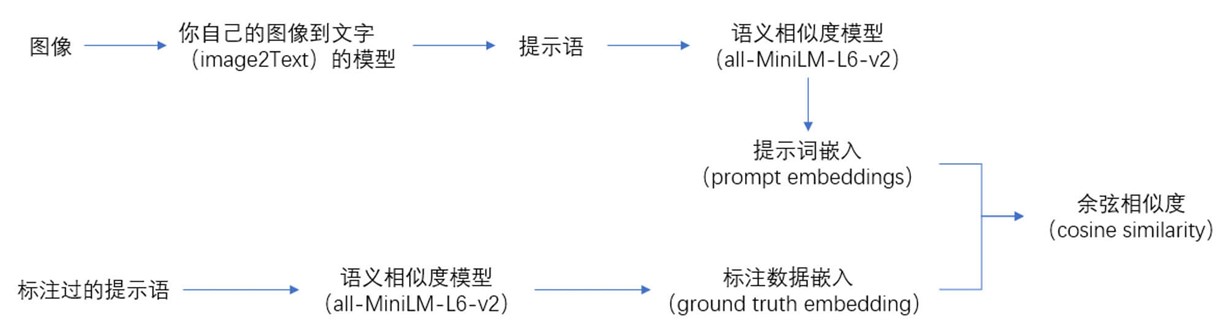
评价方式使用预测的和实际的提示嵌入向量之间的平均余弦相似性得分来评估提交。对于测试集中的每个图像,必须预测用于生成图像的提示,并将提示转换为384长度的嵌入向量。预测应该被展平为图像(imgId)和嵌入(eId)对(imgId_eId)的行。例如:
1
2
3
4
5
6
7
imgId_eId,val
20057f34d_0,0.018848453
20057f34d_1,0.030189732
....
20057f34d_383,-0.007934112
227ef0887_0,0.017384542
etc.
评奖方式是平均余弦相似性得分+PPT,省赛需要提交csv文件(就是上面这个)和ppt,国赛需要答辩。最终成绩是省赛一等奖+国赛二等奖。
时间节点:
- 2023年09月25日:比赛开始报名。
- 2023年10月30日:学院发通知。
- 2023年11月18日:我看到通知,报名比赛。
- 2023年11月28日:召集团队,但一开始没人想做。
- 2023年12月01日:做完第一个模型。
- 2023年12月04日:做完第二个模型。
- 2023年12月05日:做完PPT,卡着截止时间点提交了。
- 2023年12月18日:省赛出结果,开始准备国赛答辩。
- 2023年12月23日:国赛答辩。
- 2023年12月26日:国赛出结果。
这个博客的剩余部分是对比赛和我们模型用到的技术做简要回顾。
比赛官方示例用到的模型:
- Vit Gpt2 Image Captioning,将图片转为描述,基于Vision Transformer。
- all-MiniLM-L6-v2,将句子转为嵌入向量,基于Sentence-BERT。
我们的模型中用到的技术:
- CLIP,OpenAI 提出的多模态模型,原任务是zero-shot的图片分类。
- Vit-Large,Transformer在CV领域的应用,原来的任务是图片分类。
- LoRA,一种参数高效的微调方法。
深度学习中的图像描述
图像描述是生成图像文本描述的过程。它使用自然语言处理和计算机视觉来生成字幕。数据集的格式为 [image → captions]。数据集由输入图像及其相应的输出标题组成。
具有图像及其标题的流行基准数据集是:
- 上下文中的常见对象(COCO) 超过 120,000 张带有描述的图像的集合。
- Flickr 8K:从 flickr.com 拍摄的 8000 张描述图像的集合。
- Flickr 30K:从 flickr.com 拍摄的 30,000 张描述图像的集合
一个基本的Network Topology:
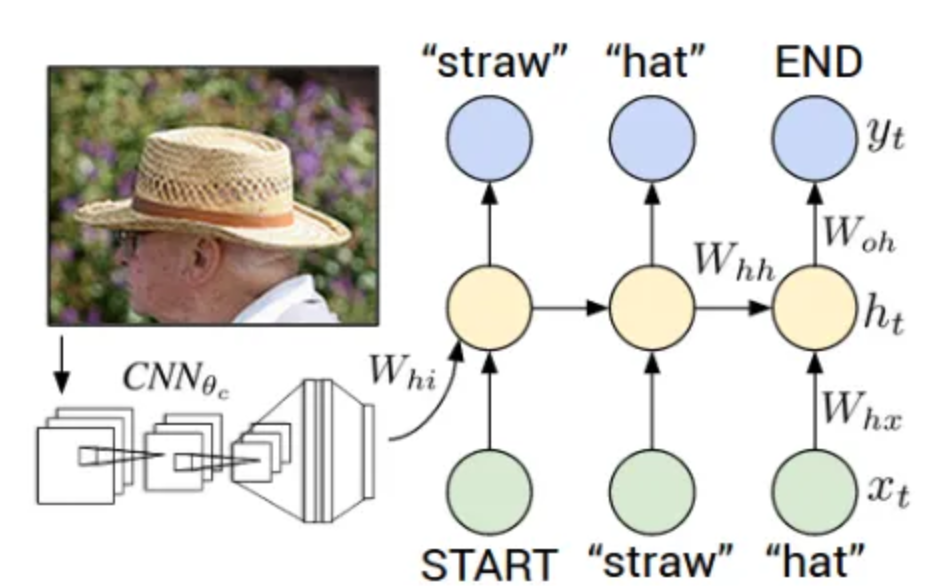
卷积神经网络(CNN)可以被认为是一个编码器。输入图像被提供给CNN以提取特征。CNN 的最后一个隐藏状态连接到解码器。
解码器是一种递归神经网络(RNN),可以进行语言建模,直到单词级别。第一个时间步长接收来自编码器的编码输出以及
- x1 =
, y1 = 序列中的第一个单词。 - x2 =第一个单词的词向量,并期望网络预测第二个词。
- 在最后一步,xT = 最后一个字,目标标签 yT =
标记。
在训练过程中,即使在解码器之前犯了错误,也会在每个时间步向解码器提供正确的输入。
在测试期间,解码器在时间 t 的输出被反馈,并在时间 t+1 成为解码器的输入。
Vision Transformer
简单而言,模型由三个模块组成:
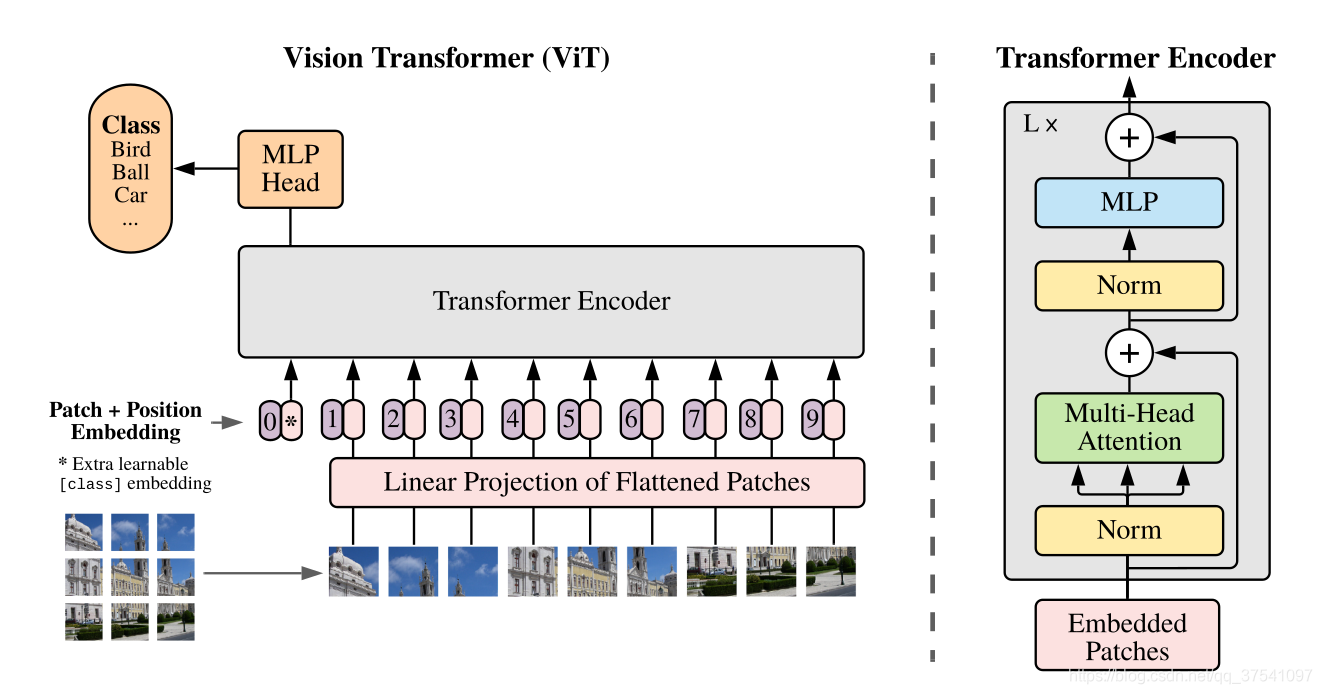
- Linear Projection of Flattened Patches(Embedding层),对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding 层来对数据做个变换。
- Transformer Encoder(图右侧有给出更加详细的结构),即重复堆叠Encoder Block $L$次
- MLP Head(最终用于分类的层结构)
处理过程如图:

在我们的模型中,使用的是 Large 版本
| Model | Patch Size | Layers | Hidden Size D | MLP size | Heads | Params |
|---|---|---|---|---|---|---|
| ViT-Base | 16x16 | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 16x16 | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 14x14 | 32 | 1280 | 5120 | 16 | 632M |
Vit Gpt2 Image Captioning
参考:
视觉编码器解码器模型可用于初始化图像到文本模型,使用任何预训练的基于 Transformer 的视觉模型作为编码器(例如 ViT、BEiT、DeiT、Swin)和任何预训练的语言模型作为解码器(例如 RoBERTa、GPT2、BERT、DistilBERT)。
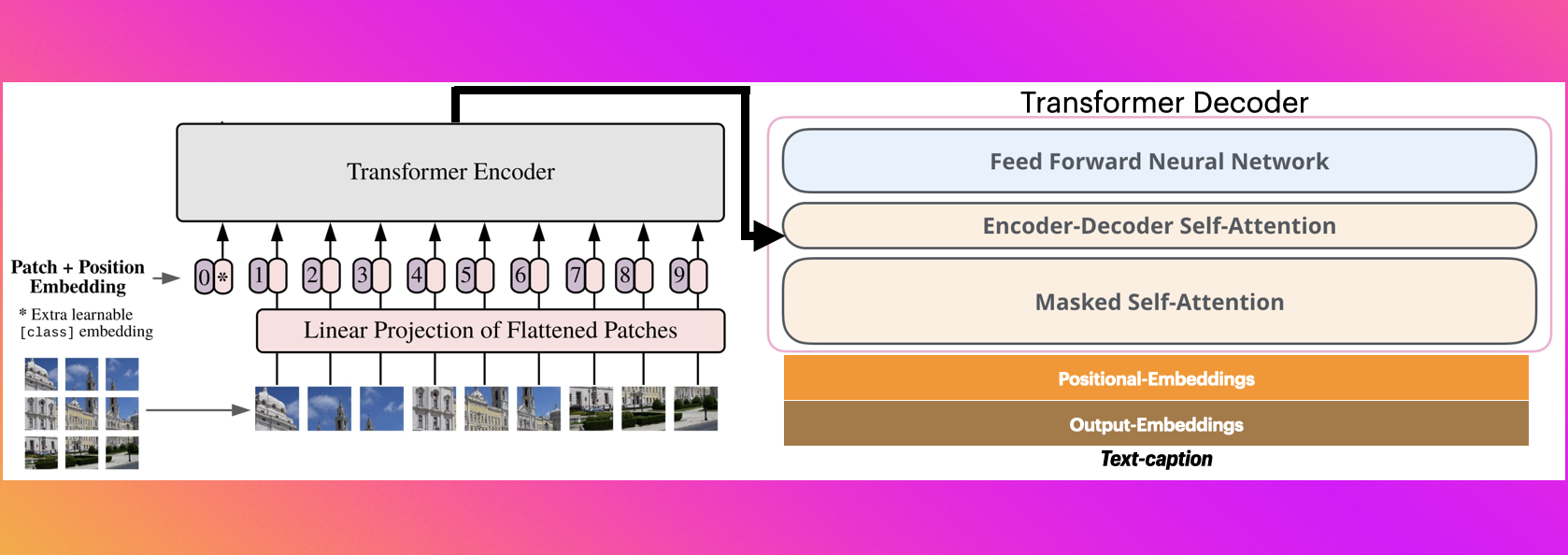
Image captioning是一个示例,其中编码器模型用于对图像进行编码,然后使用自回归语言模型(即解码器模型)生成标题。
1
2
3
4
image_encoder_model = "google/vit-base-patch16-224-in21k" # 编码器模型用于对图像进行编码
text_decode_model = "gpt2" # 自回归语言模型(即解码器模型)生成标题
model = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(image_encoder_model, text_decode_model)
在比赛任务中如何使用(其他相关设置略):
1
2
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning") # 创建模型
output_ids = model.generate(pixel_values, **gen_kwargs) # 生成图片的描述
all-MiniLM-L6-v2
前置知识:Sentence-BERT
参考:
复习一下,一个基本的SBert模型如下:
Sentence-Transformers 提供了许多预训练模型,它们对嵌入式句子(Performance Sentence Embeddings)和嵌入式搜索查询和段落(Performance Semantic Search)的质量进行了广泛的评估。如下:
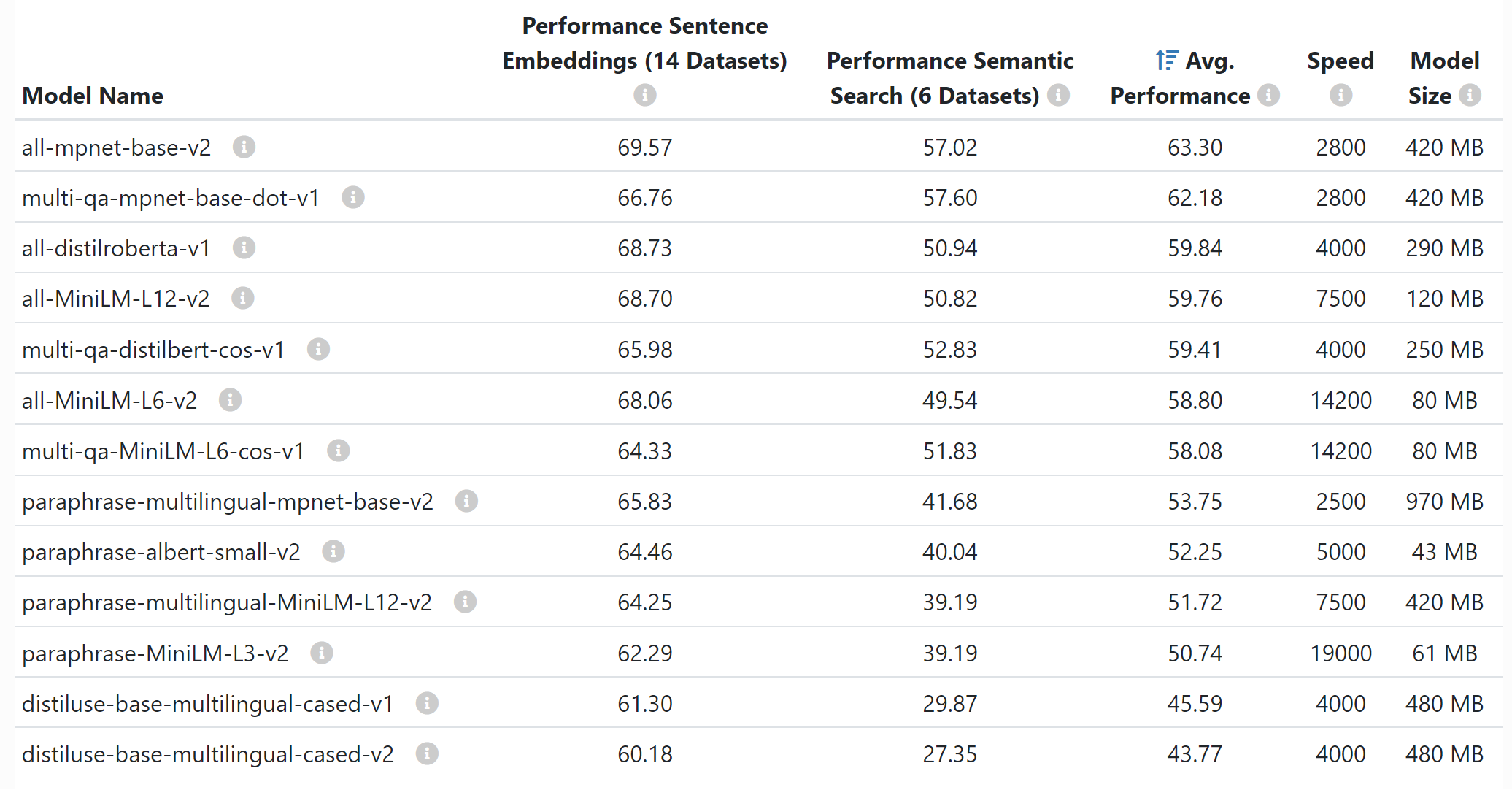
all-* 模型使用所有可用的训练数据(超过 10 亿个训练对)进行训练,并被设计为通用模型。all-mpnet-base-v2 型号提供最佳质量,而 all-MiniLM-L6-v2 速度提高 5 倍,并且仍然提供良好的质量。
是一个 sentence-transformers 模型:它将句子和段落映射到一个 384 维的密集向量空间,可用于聚类或语义搜索等任务。
可以像这样使用模型:
1
2
3
4
5
6
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
CLIP
完整参考:Learning Transferable Visual Models From Natural Language Supervision
CLIP(Contrastive LanguageImage Pre-training)是OpenAI 提出的多模态模型,后续也作为基础 模型,被广泛用在DALLE2,Stable Diffusion等重要文生图大模型中, 实现了zero-shot的图片分类。
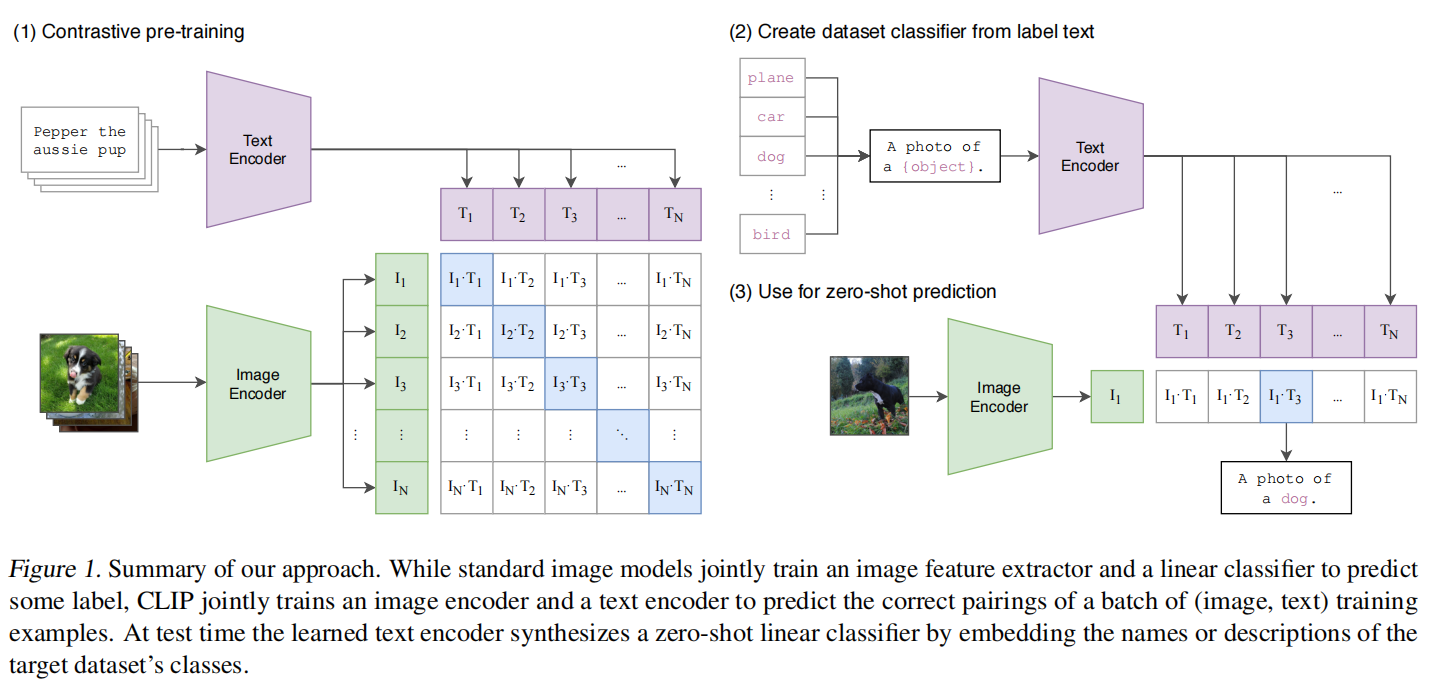
模型训练步骤:
- 输入图片->图像编码器(vision transformer)->图片特征向量
- 输入文字->文本编码器(text )->文本特征向量
- 对两个特征进行线性投射,得到相同维度的特征,并进行L2归一化
- 计算两个特征向量的相似度(夹角余弦)
- 对n个类别进行softmax,确定个正样本和个负样本,并最大化正样本的权重
模型预测步骤:
- 给出一些文本提升,选项中要包含正确答案。
- 然后计算每一个文本提升和图片特征的相似度。
- 找到相似度最高的即为正确答案.
CLIP正常包括两个模型:Text Encoder和 Image Encoder。 Text Encoder用来提取文本的特征,采用NLP 中常用的text transformer模型; Image Encoder用来提取图像的特征,可以 采用常用vision transformer模型。
本次模型中引入VIT主要通过利用CLIP引入基 本模型,之后又通过LoRA对VIT模型的 encoder中的attn进行改善微调,从而更好地 提升模型效果。
LoRA
由于大语言模型参数量十分庞大,当将其应用到下游任务时,微调全部参数需要相当高的算 力。为了节省成本,研究人员提出了多种参数高效(Parameter Efficient)的微调方法,旨在仅训练少量参数使模型适应到下游任务。LoRA (Low-Rank Adaptation of Large Language Models)方法 可以在缩减训练参数量和 GPU 显存占用的同时,使训练后的模型具有与全量微调相当的性能。
语言模型针对特定任务微调之后,权重矩阵通常具有很低的本征秩 (Intrinsic Rank)。参数更新量即便投影到较小的子空间中,也不会影响学习的有效性。因此,提出固定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变化量: \(h=W_0x+ \triangle Wx=W_0x+ABx\) 其中,预训练权重为 $W_0 ∈ R ^{d∗k}$,可训练参数为 ∆W = BA,其中 $B ∈ R ^{d∗r}, A ∈ R^{ r∗d}, r <d$。初始化时,矩阵 A 通过高斯函数初始化,矩阵 B 为 零初始化,使得训练开始之前旁路对原模型不造成影响,即参数改变量为 0。
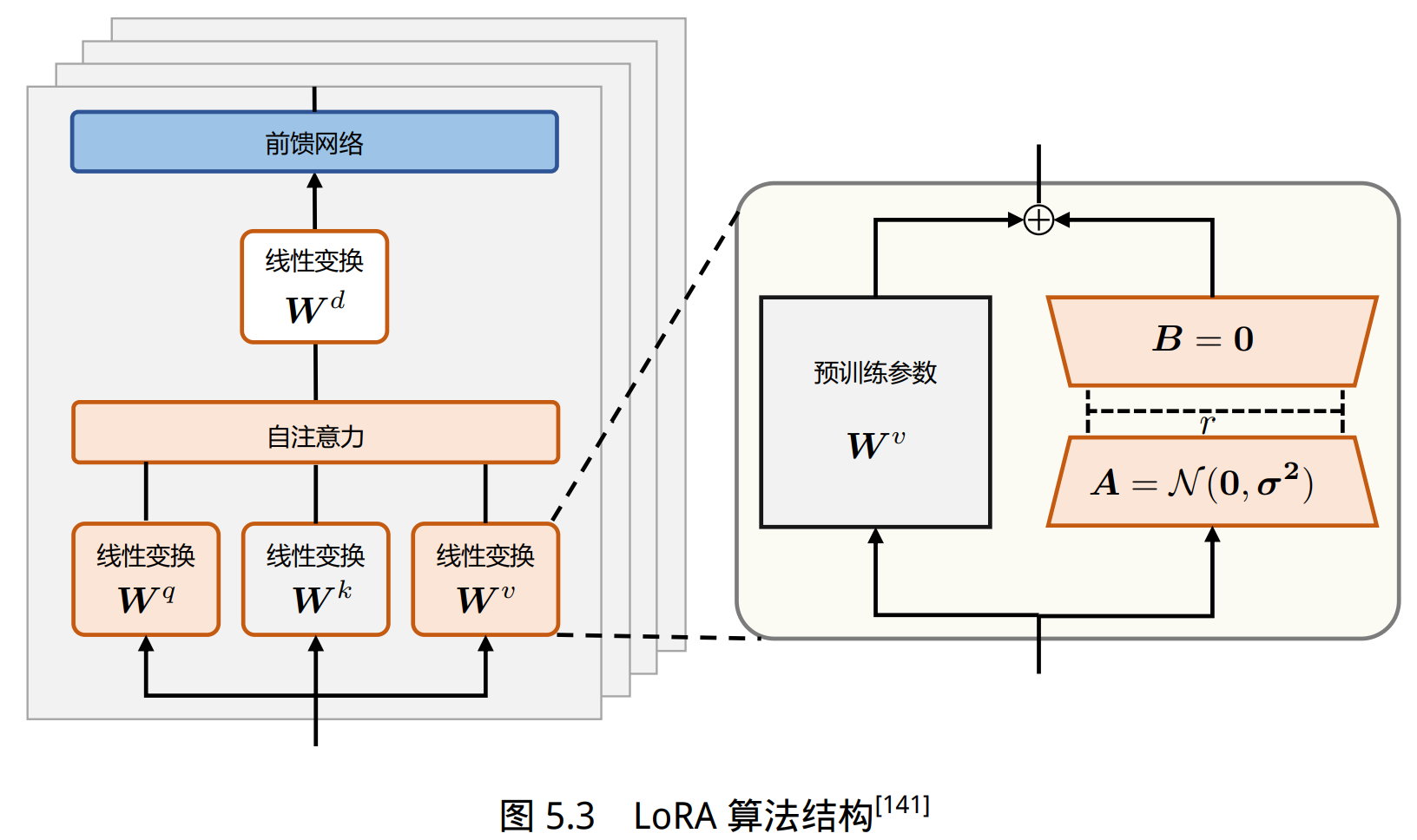
对于 GPT-3 模型,当 r = 4 且仅在注意力模块的 Q 矩阵和 V 矩 阵添加旁路时,保存的检查点大小减小了 10000 倍(从原本的 350GB 变为 35MB),训练时 GPU 显存占用从原本的 1.2TB 变为 350GB,训练速度相较全量参数微调提高 25%。
我们的模型
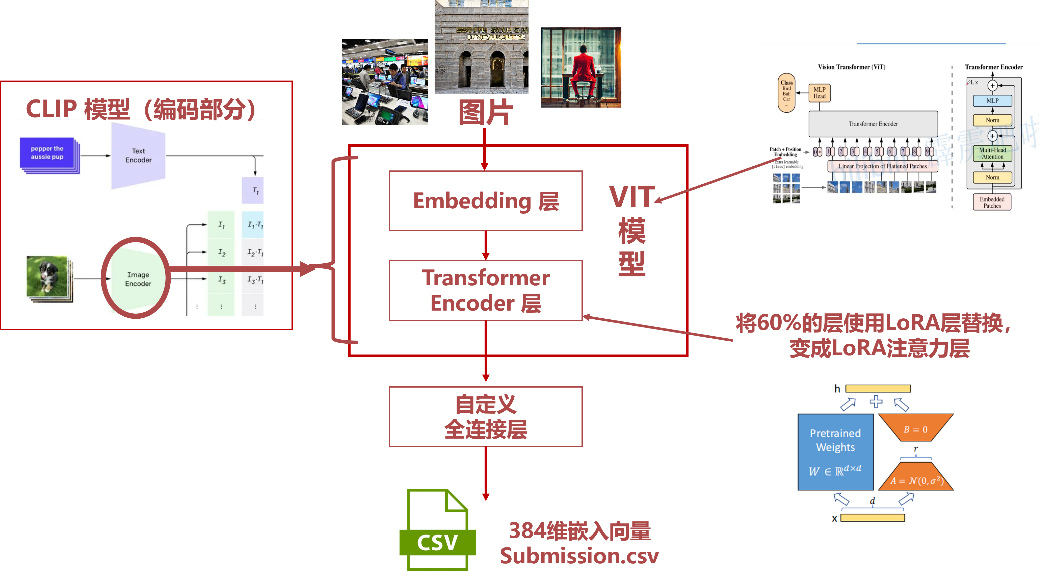
在本次比赛中,主要参考CLIP模型 (Contrastive Language-Image Pre-Training) 来搭建和训练模型, 在Image Encoder中使用 vit-large 模型提取图像的特征,之后又通过 LORA对vit模型的encoder中的注意 力层进行改善微调,从而更好地提升模型效果。
在具体模型部署中,参考了 OpenAI 在 Hugging Face 上发表的预训练模型 clip-vit-large-patch14-336。
比赛模型ClipNet类,全连接层即self.head:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
class ClipNet(torch.nn.Module):
def __init__(self, args, lora_rate=0.0, nfz_rate=0.0, lora_scale=1.0, rank=4):
super().__init__()
self.args = args
config = CLIPConfig.from_pretrained(PRETRAINED_MODEL_PATH(args.model_name))
config.vision_config.image_size = args.image_size
clip = CLIPModel(config)
pretrained_file = f'{PRETRAINED_MODEL_PATH(args.model_name)}/pytorch_model.pt'
load_pretrained(clip, pretrained_file, strict=False, can_print=True)
self.vision_model = clip.vision_model
fc_dim = 16 * 1024
ebd_dim = self.vision_model.embeddings.position_embedding.embedding_dim
# 添加的额外的全连接层,将输出的特征维度转换为embedding_dim,即384
self.head = nn.Sequential(
nn.Linear(ebd_dim, fc_dim),
nn.BatchNorm1d(fc_dim),
nn.ReLU(),
nn.Linear(fc_dim, args.embedding_dim),
)
lora_clip_model(self.vision_model, args, lora_scale, lora_rate, nfz_rate, rank)
def forward(self, data):
out = self.vision_model(data['image'])
logits = self.head(out['pooler_output'])
return logits
LoRA 注意力层的一些细节,在比赛模型中,LoRA层用于替换Transformer架构中, 自注意力模块中有四个权重矩阵 Q、K、V、O,具体来说,将视觉模型 self.vision_model 的后部 60% 层使用 LoRA 层替换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def lora_clip_model(model, args, lora_scale, lora_rate, nfz_rate=0.4, rank=4):
# 在clip模型中,将lora_scale设置为1.0,lora_rate设置为0.6,nfz_rate设置为0.4,rank设置为4
# 设置不计算梯度
model.embeddings.requires_grad_(False)
model.pre_layrnorm.requires_grad_(False)
model.encoder.layers.requires_grad_(False)
layer_num = len(model.encoder.layers)
lora_num = int(layer_num * lora_rate) # lora层数
nfz_num = int(layer_num * nfz_rate) # 非冻结区域的比例
for _i in range(layer_num - lora_num - nfz_num, layer_num): # 从倒数第lora_num层开始,到最后一层
if (layer_num - _i) <= nfz_num: # 如果是非冻结区域的比例
model.encoder.layers[_i].requires_grad_(True) # 设置计算梯度
continue
# 如果是lora层
attn = model.encoder.layers[_i].self_attn # 获取self_attn
new_attn = LoRACLIPAttention(attn, rank=rank, lora_scale=lora_scale) # 替换为lora attention
model.encoder.layers[_i].self_attn = new_attn # 替换
if args.can_print: print(f'lora clip_model, scale:{lora_scale} rate:{lora_rate} num:{lora_num}')
其他信息:
- 最终评分:0.749(相比微调得分只在0.67左右,可能原因是比赛数据集比较小)
- 样本:微调2M图片(全部用作训练),大小336x336,原数据集大小1.6TB(未清洗)
- 验证集:kaggle比赛官方给出的一些图片-文本样例
- 测试集:比赛数据集有20张图片,有限次提交
- 显卡:NVIDIA P100
- 损失函数:CosineEmbeddingLoss
- 正则化:LayerNorm(VisionTransformer),BatchNorm1d(全连接层)
- 优化器:Adam
- 参数量:主要为ViT-Large,总量大约3亿
- 微调参数:
Initial lr:1e-4,Final lr:5e-5,Epochs:3,Batch size:320 - 冻结底部 40% 的层,将 LoRA 用于中间的 40% 层,并使顶部 20% 的层可训练.可训练参数的数量为 47%。
训练样本来自DiffusionDB,一个文本到图像提示数据集。它包含使用 Stable Diffusion 产生的1400万张图像,并使用了真实用户指定的提示和超参数。

仓库结构
原仓库内容主要是为大赛提供测试数据集。同时给出一些样例和参考代码。
- input 目录下提供了all-MiniLM-L6-v2模型,vitgpt2模型
- stable-diffusion-image-to-prompts目录下提供了样本参考。包括样本图像和prompt.cvs文件样例。
- Calculating prompt Sample 01.py提供了一个基于it-gpt2-image-captioning试题解的样例。
比赛试题在Sample Image目录下的20副图,通过你自己设计的算法,生成矢量数据文件,提交到大赛网站上。
由于非付费企业用户无法使用 Gitee 的 LFS 服务,请先前往发行版下载三个大文件放在./input/sentence-transformers-222/all-MiniLM-L6-v2下
我们的模型主要放在compitition文件夹下,img文件夹用于存放文档需要的图片,reference文件夹用于存放参考。
出题方提供的案例可以本地直接跑。而我们做的模型是放在 kaggle 上跑的,compitition文件夹下的代码仅供参考。