知识蒸馏简要介绍
知识蒸馏(Knowledge Distillation,KD)是为了解决如何训练一个轻量并且高性能的深度学习模型这个问题出现的。
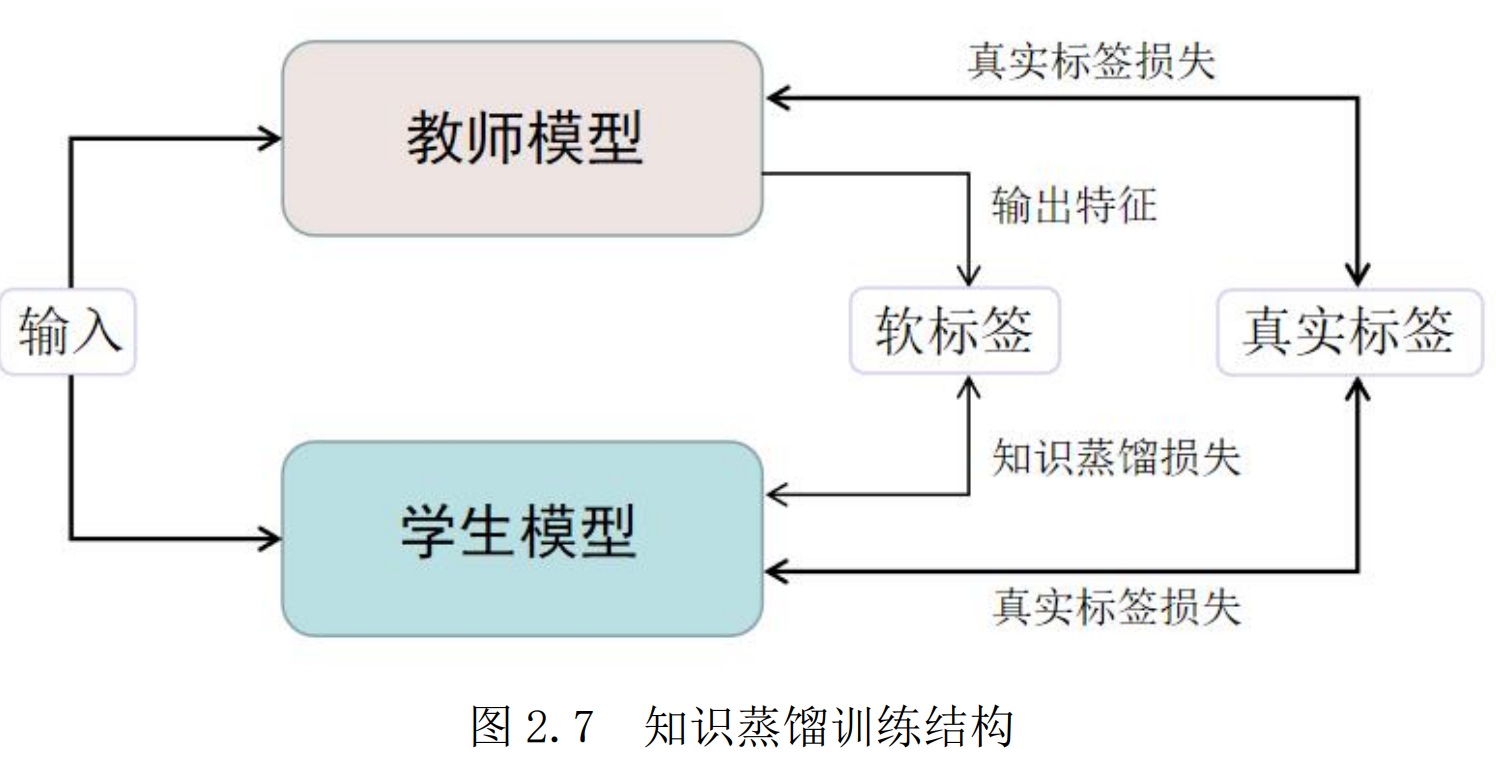
知识蒸馏通常意义指一种教师-学生式的训练架构,在训练完成大规模复杂的教师模型后,将已训练的教师模型的知识蒸馏出来供相对简单的学生模型学习,而学生模型只需要以轻微的损失计算为代价便可学习到教师模型中丰富的知识。
若是以模型压缩为目的,学生模型往往是一种轻量而高效的模型,其参数量远小于庞大复杂的教师模型,而最终性能相对于教师模型却没有下降很多。而模型增强则旨在通过教师模型丰富的知识指导学生模型,通过自学习和互学习等策略或利用跨模态等数据,进一步提高模型性能。
在分类任务中,传统的模型学习过程是将最后一层逻辑单元的输出值,通过Softmax激活函数进行归一化后,用所得到的类概率来与真实标签计算损失,从而进行迭代训练,其类概率公式如下,其中,$y_i$表示为第 i 类逻辑单元的输出值,$p(y_i)$表示所预测的类别为第i 类的概率,n表示类别的个数 :
\[p(y_i)=\frac{\exp(y_i)}{\sum^n_i \exp(y_i)}\]对于知识蒸馏来说,将最后一层逻辑单元的输出用于学生模型学习时,其所包含的大量噪声信息可能会导致学生模型过拟合,影响其泛化能力;而如果使用类概率时,同样会造成信息丢失的问题。因此,在考虑这些问题下,学习软目标概念的知识蒸馏被提出,其知识表示公式如下:
\[p_{KD}(y_i,T)=\frac{\exp(y_i/T)}{\sum^n_i \exp(y_i/T)}\]其中,T 代表所设置的蒸馏温度,为超参数,通过温度 T 的调节来改变软标签的软化程度。于此同时,在训练过程中加上真实标签的训练会使训练效果有效提升,因此,知识蒸馏时学生模型所计算的总损失可表示为:
\[L = \alpha L_{KD} ( p( y_t ,T ), p( y_s ,T )) +L_S ( z, p( y_s ,T))\]其中,$y_t$ 和 $y_s$ 分别表示教师模型和学生模型的输出特征,z 表示真实标签值,$L_{kd}$ 和$L_s$ 分别表示知识蒸馏损失和真实标签损失的计算函数,一般为交叉熵损失函数,α为超参数,通过调节该参数改变知识蒸馏损失在总损失中的权重大小。