基于EHR数据集的深度学习模型思考
文章笔记:
三篇文章都是基于EHR的MIMIC-III数据集,训练模型,做病人相关数据的预测。
按照时间顺序,第一篇有四个任务(院内死亡、生理衰竭、住院时间、表型分类),使用基于LSTM的模型,现在来看LSTM似乎过时了。
第二篇有两个任务(预测诊断、急性呼吸衰竭),其中一个任务是创新的,我觉得这是一种讨巧的行为,我提出100种新任务,我可以写100篇论文吗?
原文:注意到我们的急性呼吸衰竭(ARF)诊断任务是一项全新的任务,我们认为,在临床实践中,越早做出诊断,其价值就越高。因此,我们在这项工作中提取了前 48/12 小时的数据来进行诊断预测,而不是整个入院期间的数据。
模型如下,引入了对于医疗笔记的特征提取,以及多模态融合方法,值得学习。
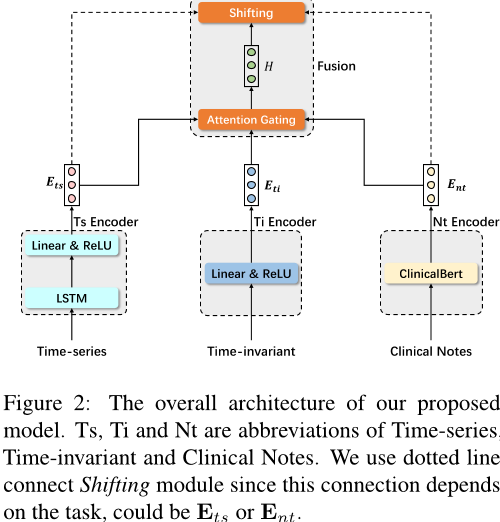
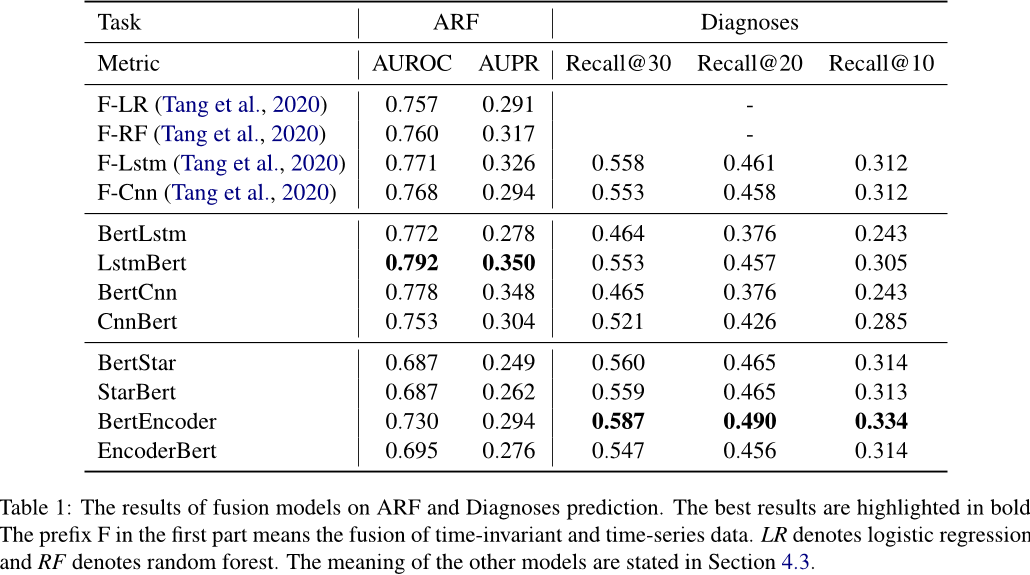
可以看到,对于时间相关、时间无关的两种特征提取方法还是比较原始的(LSTM+线性层),我坚信有更好的方法。但是在结果中(如下图)基于LSTM的模型在ARF任务中表现最优,我坚信有更好的特征提取方法,能达到更好的效果。(而且ARF是全新的任务,参考价值不大)
第三篇实现了将时间的不规则性整合到多模态表示中,以提高医学预测能力。提取特征的方式和多模态融合方式相较于前两篇更加复杂。模型图如下:
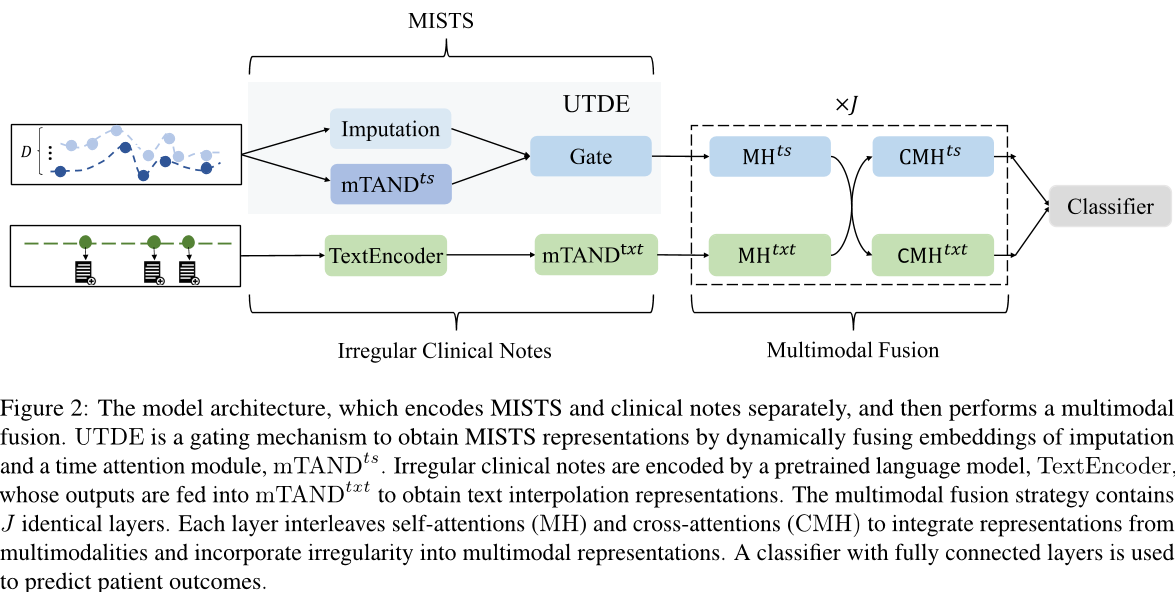
这个模型在提取MISTS时使用了两种方法(Imputation、mTAND),并且使用UTDE做融合。这确实可以提高效果,但我并不喜欢这种方法。
- Imputation、mTAND、UTDE都不是作者的新方法,只是把别人的方法拿过来做排列组合。在后面实验部分也可以看到作者实验了很多之前的方法。
- 使用多个方法做融合(这里不是指多模态)常常是深度学习比赛为了刷榜使用的方法,那我使用之前用过的100种旧方法做融合(类似于Boosting),效果不会提升吗?
第三篇的两个任务:48小时住院死亡预测(48-IHM)和24小时表型分类(24-PHE)。
有趣的是,三篇文章的任务都是不完全相同的,我还是认为这是一种讨巧的方法,我提出一种模型结构,在很多不同的任务上做预测,是不是只要一个达到SOTA就可以发论文?如果工作量不够,是不是还可以提出一个新任务来做分析?
本文由作者按照 CC BY 4.0 进行授权