从人工智能基础课到真正的“人工智能基础”
Encoder-Decoder
我们从编码器-解码器架构开始,在Transfomer出现之前,还是朴素的RNN结构。
RNN的一种结构是 n-to-m,即输入、输出为不等长的序列,也称为 Encoder-Decoder, 这种结构常见于机器翻译中,因为源语言和目标语言的句子往往并没有相同的长度。
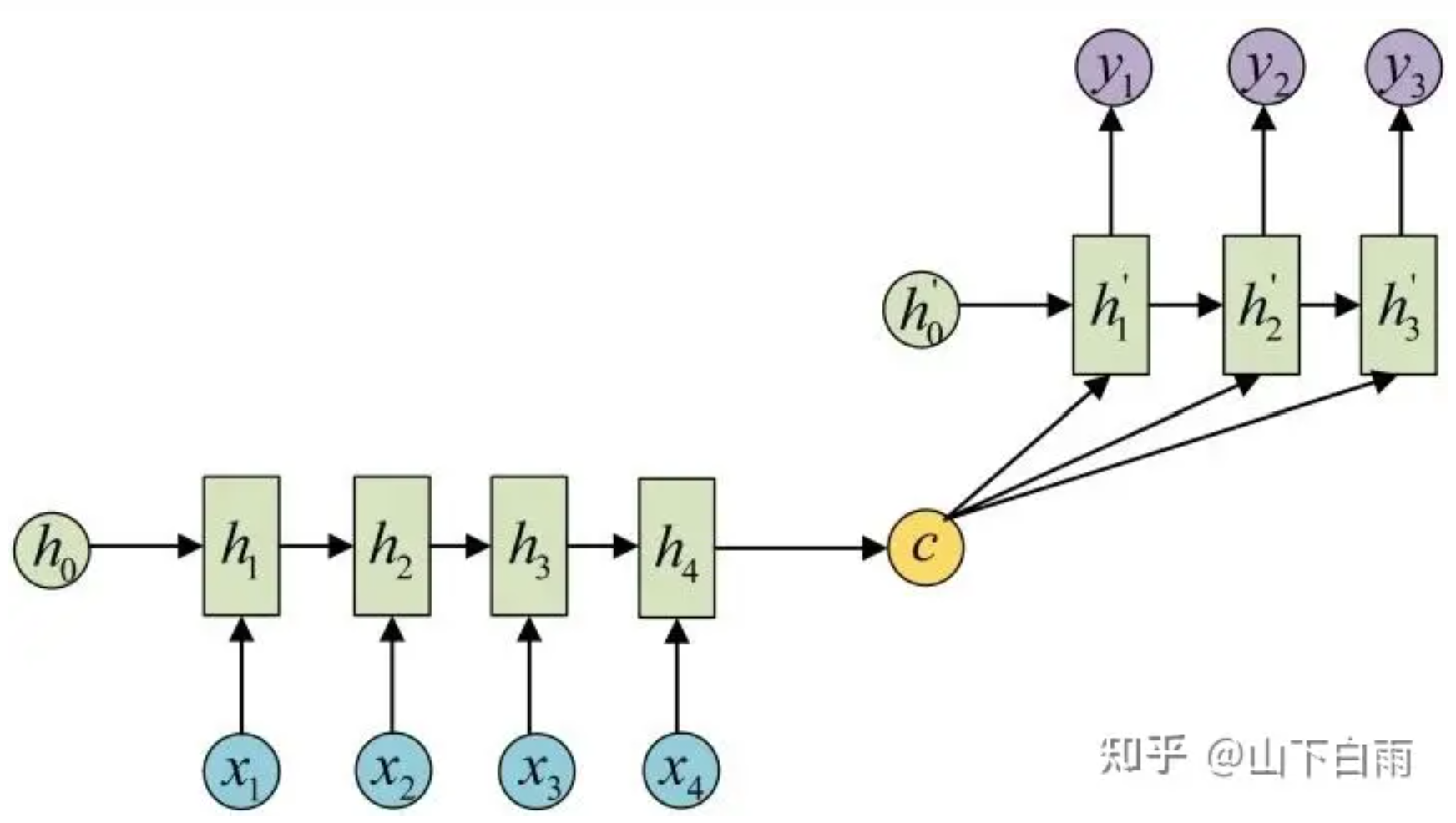
首先:Encoder-Decoder结构先将输入数据编码成一个上下文语义向量c;语义向量c可以有多种表达方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
之后:就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。Decoder的RNN可以与Encoder的一样,也可以不一样。具体做法就是将c当做之前的初始状态h0输入到Decoder中,还有一种做法是将c当做每一步的输入。
这样朴素的结构会容易遗忘很久之前的信息,LSTM可以部分解决这个问题,不过我们要聊的是注意力。
Attention 机制
为了解决这一由长序列到定长向量转化而造成的信息损失的瓶颈,Attention注意力机制被引入了。
Attention机制跟人类翻译文章时候的思路有些类似,即将注意力关注于我们翻译部分对应的上下文。
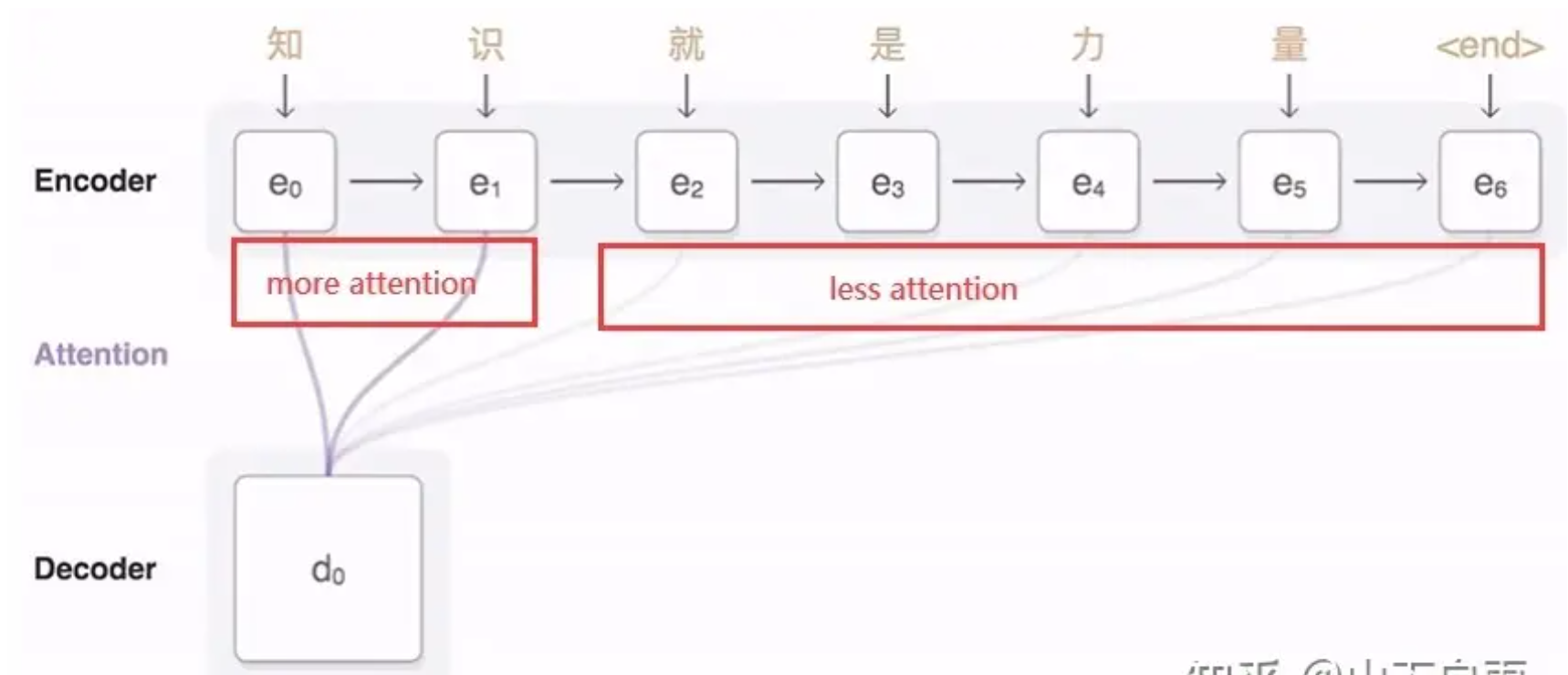
如下图所示,当我们翻译“knowledge”时,只需将注意力放在源句中“知识”的部分。这样,当我们decoder预测目标翻译的时候就可以看到encoder的所有信息,而不仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。
注意力更细致的计算与介绍可以看这个链接
当然,一个自然的疑问是,Attention机制如此有效,那么我们可不可以去掉模型中的RNN部分,仅仅利用Attention呢?
Self-Attention
于是,Transfomer只使用了attention机制(+MLPs),不需要RNN、CNN等复杂的神经网络架构,并行度高。
![]()
Transfomer 同样拥有编码器-解码器架构,并且在每一个块中加入了注意力机制。
Encoder的输入首先流经Self-Attention——该层帮助Encoder在编码特定单词时查看输入句子中的其他单词。Dncoder的Attention层帮助Dncoder专注于输入句子的相关部分(类似于seq2seq 模型中的注意力)。